

ggplot2包是基于Wilkinson在《Grammar of Graphics》一书中所提出的图形语法的具体实现, 这套图形语法把绘图过程归纳为data, transformation, scale, coordinates, elements, guides, display等一系列独立的步骤, 通过将这些步骤搭配组合, 来实现个性化的统计绘图。于是, 得益于该图形语法, Hadley Wickham所开发的ggplot2是如此人性化, 不同于R基础绘图和先前的lattice那样参数满天飞, 而是摈弃了诸多繁琐细节, 并以人的思维进行高质量作图。在ggplot2包中, 加号的引入革命性的, 这个神奇的符号完成了一系列图形语法叠加, 也是这个符号, 让很多人喜欢上了用R来进行统计绘图。
ggplot2的作者Hadley Wickham绝对是R界的男神, 很多人都对Hadley的R包重度依赖, 例如他所开发的plyr、reshape2和ggplot2三款包, 完全可满足日常的数据处理和可视化过程。所以, 当男神今年造访北京R语言大会引起了不小的轰动。
在论文绘图哪家强这个问题上, 知乎上已有各种神回复。除却一些稀奇古怪的绘图难以达成, ggplot2以美轮美奂的统计制图能力一定能排进各类绘图软件的前三。对ggplot2功能的扩展也在加强。例如plotly能够支持以ggplot2为源码的交互式绘图, Hadley正在开发ggvis除了支持交互式绘图, 已把管道作为ggvis的重要组成部分。可以预见的是统计绘图将会变得更交互、更快速。
本文既是自己对ggplot2学习的总结, 也希望能帮助大家对ggplot2快速入门。主要以Hadley的官方文档为教材, 介绍了ggplot2的基本原理和操作, 链接了部分ggplot2参数索引, 并在最后加入了作图实战。
ggplot2的图形语法
尽管qplot作为ggplot2的快速作图(quick plot)函数, 能够极大的简化作图步骤, 容易入门和上手, 但是qplot却不是泛型函数, 而ggplot()作为泛型函数, 能对任意类型的R对象进行可视化操作, 是ggplot2的精髓所在, 因而在本文中主要的绘图都是通过ggplot()来完成的。有关于qplot的介绍可以细看Hadley的官方介绍。
在Hadley的ggplot2官方文档中, Hadely这样对Wilkinson的图形语法进行了描述:“一张统计图形就是从数据到几何对象(geometric object, 缩写为geom, 包括点、线、条形等)的图形属性(aesthetic attributes, 缩写为aes, 包括颜色、形状、大小等)的一个映射。此外, 图形中还可能包含数据的统计变换(statistical transformation, 缩写为stats), 最后绘制在某个特定的坐标系(coordinate system, 缩写为coord)中, 而分面(facet, 指将绘图窗口划分为若干个子窗口)则可以用来生成数据中不同子集的图形。”因此在ggplot2中, 图形语法中至少包括了如下几个图形部件:
- 数据(data)
- 映射(mapping)
- 几何对象(geom)
- 统计变换(stats)
- 标度(scale)
- 坐标系(coord)
- 分面(facet)
这些组件之间是通过“+”, 以图层(layer)的方式来粘合构图的, 所以图层是ggplot2中一个重要的概念。当然, 在掌握基本的图形部件基础上, 要完成一幅高质量的统计绘图, 仍然需要其他图形部件来进一步扩展, 这包括了:
- 主题(theme)
- 存储和输出
接下来将对这些在ggplot2包中出现的概念逐一展开
数据(data)
- 在ggplot2中, 所接受的数据集必须为数据框(data.frame)格式, 如内置的mtcars数据集:
- head(mtcars)
- 这种格式带来的好处是数据易于存储, 也能在保留原有的绘图参数下, 用%+%方便地变更已有数据集。
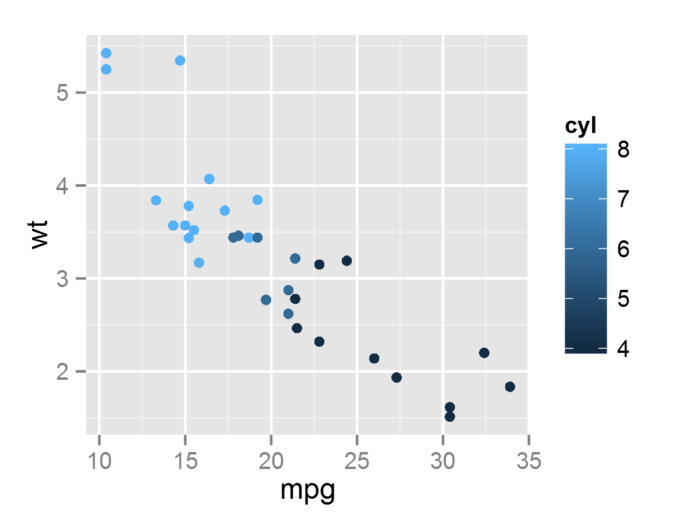
为通过”+”以图层的方式加入点的几何对象
- p <- ggplot(mtcars, aes(mpg, wt, colour = cyl)) +
- geom_point() #geom_point()为通过”+”以图层的方式加入点的几何对象
- p
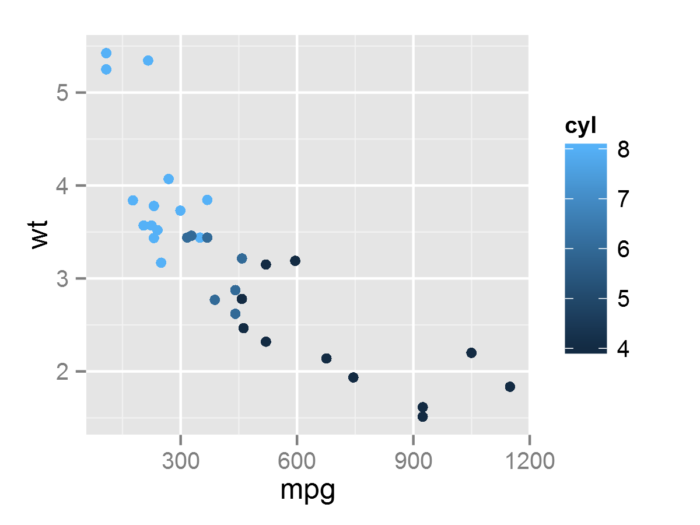
- mtcars.c <- transform(mtcars, mpg = mpg^2)
- p %+% mtcars.c #用mtcars.c替换mtcars
- 而ggplot2进行数据分组时必须根据行, 而不能根据列, 例如在mtcars的数据集中, 可以把汽车按汽缸数进行分组, 但不能按汽车的档位数和汽缸数这两个变量分为两组。这要求把“宽”数据转化为“长”数据。所谓的长数据是变量不在是放在各个列上, 而是拍成一列, 每一个变量都分别占其中的几行, 这样就能方便的对每个变量进行分组。reshape2中melt()和cast()能够灵活的融合(melt)和重铸(cast)在数据框中的数据。
- #融合档位数和汽缸数这两个变量
- mtcars.m <- melt(mtcars, id = c("mpg", "disp", "hp", "drat", "wt", "qsec", "vs", "carb"))
- head(mtcars)
- head(mtcars.m)
映射(mapping)
(1) 映射的概念
aes()函数是ggplot2中的映射函数, 所谓的映射即为数据集中的数据关联到相应的图形属性过程中一种对应关系, 例如:
- > p1 <- ggplot(data = mtcars)
- > summary(p1)
- data: mpg, cyl, disp, hp, drat, wt, qsec, vs, am, gear, carb [32x11]
- faceting: facet_null()
- > p2 <- ggplot(data = mtcars, mapping = aes(x = wt, y = hp, color = gear))
- > summary(p2)
- data: mpg, cyl, disp, hp, drat, wt, qsec, vs, am, gear, carb [32x11]
- mapping: x = wt, y = hp, colour = gear
- faceting: facet_null()
可以发现, 在p2中, 通过aes()指定了横纵坐标分别为wt和hp, 颜色为gear这三种图形属性, 在ggplot2中不同的几何对象对应着不同的图形属性, 有关于几何对象的将在下面的小节讲解。
(2) 设定和映射
映射是将一个变量中离散或连续的数据与一个图形属性中以不同的参数来相互关联, 而设定能够将这个变量中所有的数据统一为一个图形属性。
- p <- ggplot(mtcars, aes(wt, mpg))
- p + geom_point(color = "blue") #设定散点的颜色为蓝色
- p + geom_point(aes( color = "blue"))
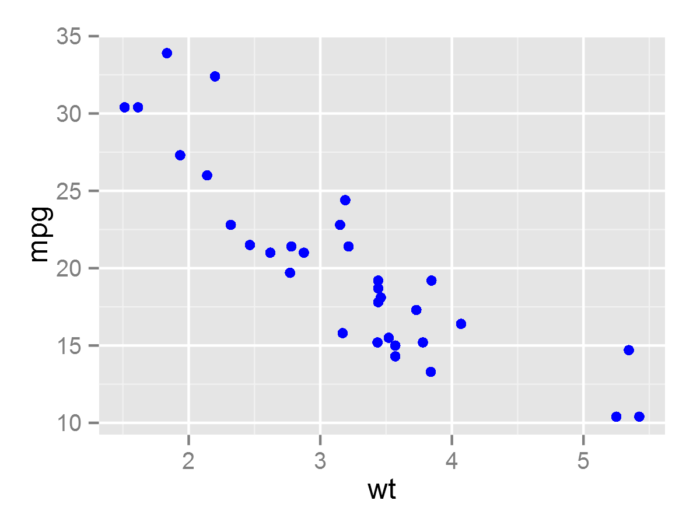
最后一行语句为错误的映射关系, 在aes中, color = “blue”的实际意思是把”blue”当为一个变量, 用这个变量里的数据去关联图形属性中的参数, 因为”blue”只含有一个字符变量, 默认情况下为离散变量, 按默认的颜色标度标记为桃红色
(3)分组(group)也是ggplot2种映射关系的一种, 默认情况下ggplot2把所有观测点分为了一组, 如果需要把观测点按额外的离散变量进行分组处理, 必须修改默认的分组设置。
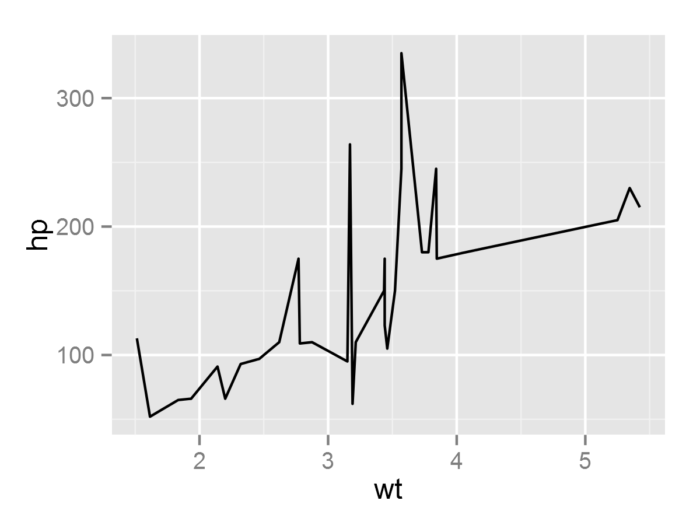
- p1 <- ggplot(data = mtcars, mapping = aes(x = wt, y = hp)) + geom_line()
- #默认分组设置, 即group=1
- #geom_line为折线图的几何对象
- p2 <- ggplot(data = mtcars, mapping = aes(x = wt, y = hp, group = factor(gear))) + geom_line()
- #把wt和hp所对应的观测点按gear(gear以因子化变为离散变量)进行分组
图层(layer)
在上文中通过对数据和映射的讲解中, 我们已经采用过”+”来添加图层, ggplot2中图层的概念和PS中图层的概念很像, 可以这样理解ggplot2中的图层:每个图层可以代表一个图形组件, 例如下面要介绍的几何对象、统计变换等图形组件, 这些组件以图层的方式叠加在一起构成一个绘图的整体, 在每个图层中的图形组件又可以分别设定数据、映射或其他相关参数, 因此组件之间又是具有相对独立性的。ggplot2中图层的设定是十分成功的, 因为这一过程是如此实用、方便而富有逻辑性。
(1)在几何对象中设定映射
前面我们已在ggplot()中设定了映射了关系, 这种映射关系是默认的, 我们可以在后面的几何对象中沿用已设定的默认映射关系, 也可以随时在几何对象中进行更改。
- p <- ggplot(mtcars, aes(x = mpg, y = wt, color = factor(gear)))
- #设定默认的映射关系
- p + geom_point()
- #沿用默认的映射关系来绘制散点图
- p + geom_point(aes(shape = factor(carb)))
- #添加图层中的shape的映射关系
- p + geom_point(aes(y = carb)))
- #修改默认的y的映射关系, 注意图中y轴名称仍然以默认的wt表示
- p + geom_point(aes(color = NULL))
- #删除默认的color映射关系
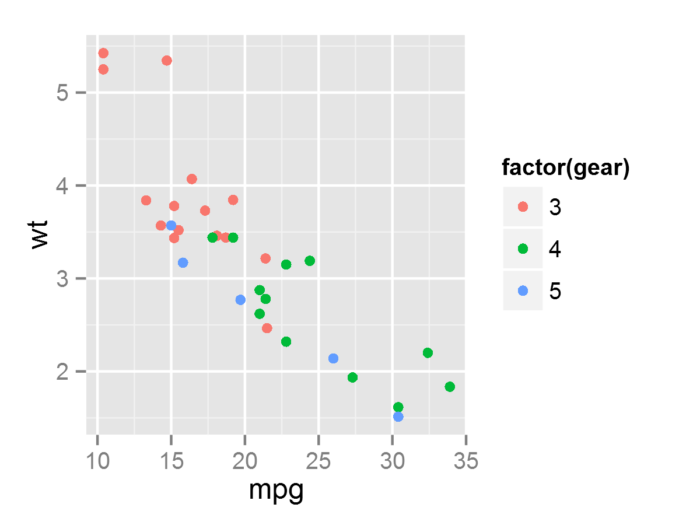
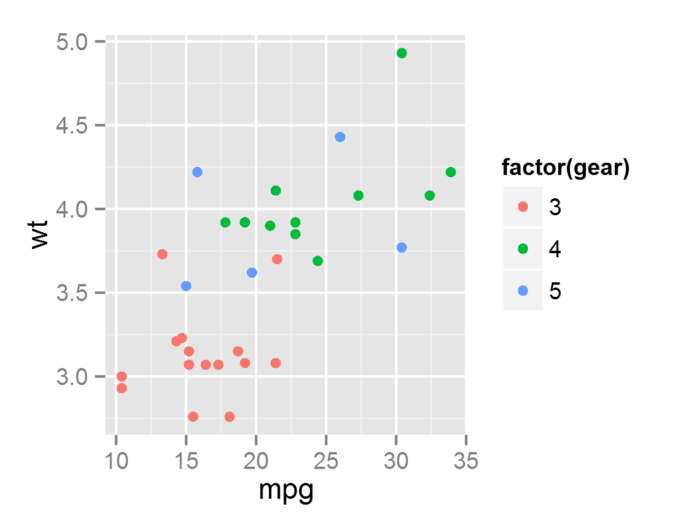
尽管上面三个有关例子在实际应用中很少去涉及, 但是很好的说明了图层、数据和映射之间的关系。
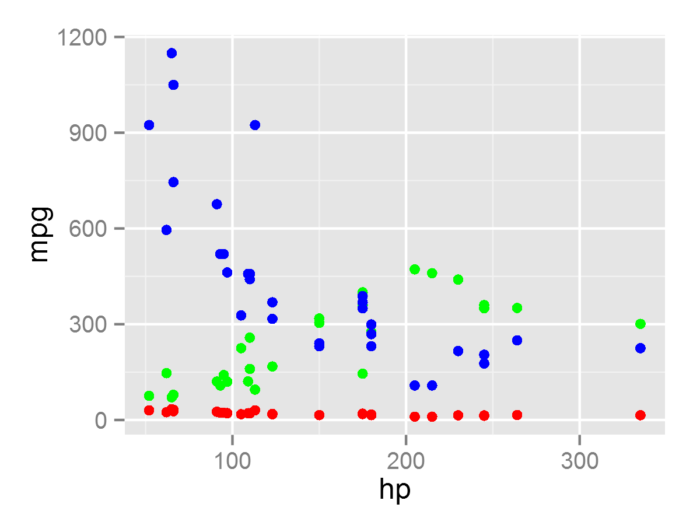
(2) 采用多个数据集或向量数据绘图
在很多种绘图场合中, 我们会运用到多个数据集或向量数据来进行图层叠加, 具体的例子如下
- #构建不同于mtcars的数据集mtcars.c
- mtcars.c <- transform(mtcars, mpg = mpg^2)
- ggplot()+
- geom_point(aes(x = hp, y = mpg), data = mtcars, color = "red") +
- geom_point(aes(x = mtcars$hp, y = mtcars$disp), color = "green")+
- #选用向量数据
- geom_point(aes(x = hp, y= mpg), data = mtcars.c, color = "blue")
- #选用不同的数据集
几何对象(geom)和统计变换(stat)
几何对象执行着图层的实际渲染, 控制着生成的图像类型。例如用geom_point()将会生成散点图, 而geom_line会生成折线图。统计变换即对数据进行统计变化, 通常以某种方式对数据信息进行汇总, 例如通过stat_smooth()添加光滑曲线。
每一个几何对象都有一个默认的统计变换, 并且每一个统计变换都有一个默认的几何对象。正因如此, 这一设定将会使绘图过程变的灵活多变。
在ggplot2的官方索引中, 已对ggplot2中所有的geom和stat组件进行了汇总, 更详细的内容, 可直接点开相应图形组件所对应的链接。下面对几个常用的几何对象和统计变换进行举例描述。
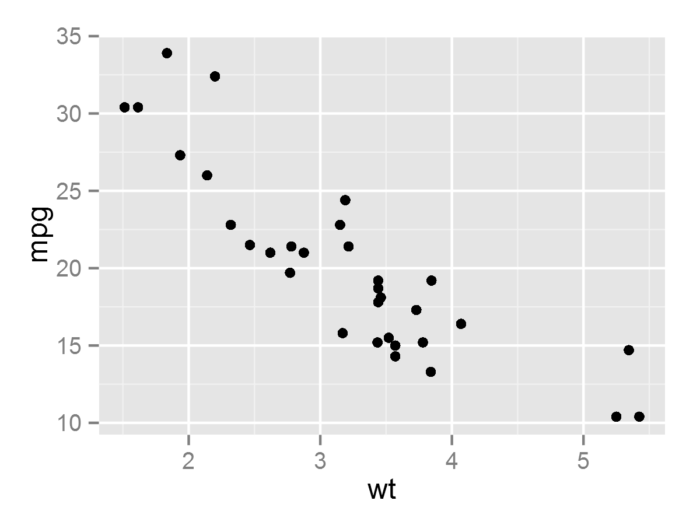
(1) geom_point()散点图
- p <- ggplot(mtcars, aes(wt, mpg))
- p + geom_point()
- #更改颜色-连续变量
- p + geom_point(aes(color = qsec))
- #更改颜色-离散变量
- p + geom_point(aes(color = factor(gear)))
- #更改透明度
- p + geom_point(aes(alpha = qsec))
- #更改形状
- p + geom_point(aes(shape = factor(gear)))
- #更改点大小
- p + geom_point(aes(size = qsec))
- #两种颜色的叠加
- p + geom_point(color = "grey50", size = 5) + geom_point(aes(color = qsec), size = 4)
- #颜色和形状的叠加
- p + geom_point(color = "grey50", size = 5) + geom_point(aes(shape = factor(gear)), size = 3)
(2) geom_histogram()
- m <- ggplot(movies, aes(rating))
- #这里使用movies数据集
- m + geom_histogram()
- m + geom_histogram(bin = 0.5)
- #调整分箱(bin)数据
- m + geom_histogram(bin = 1)
- m + geom_histogram(bin = 2)
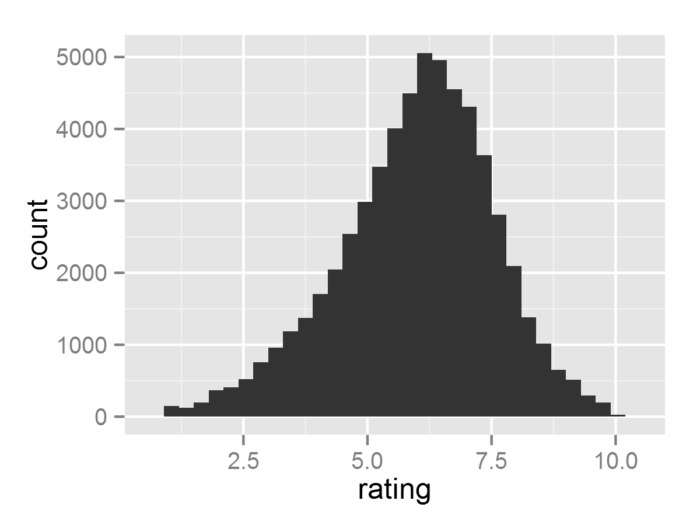
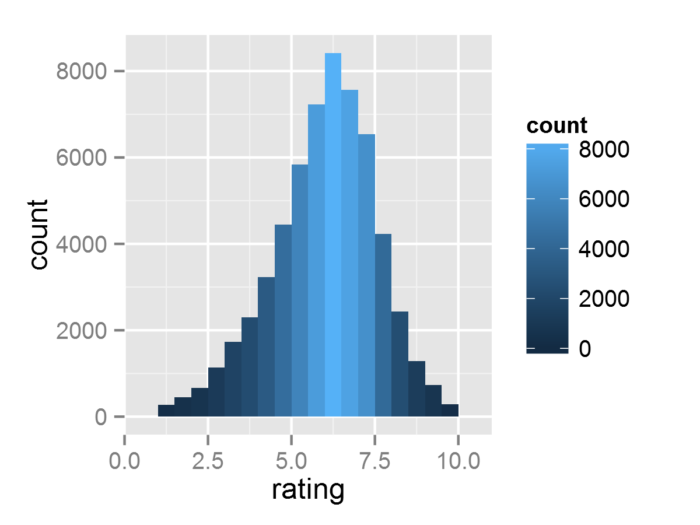
geom_histogram()这个几何对象默认使用stat_bin这个统计变换, 而这个统计变换会生成(1)count:每个组里观测值的数目, (2)density:每个组里观测值的密度和(3)x:组的中心位置这三个变量。生成的变量在ggplot()中的再使用..围起来, 因此可以用来生成如下的图
- m + geom_histogram(bin = 0.5, aes(fill =..count..))
- m + geom_histogram(bin = 0.5, aes(y = ..density..)) + geom_density()
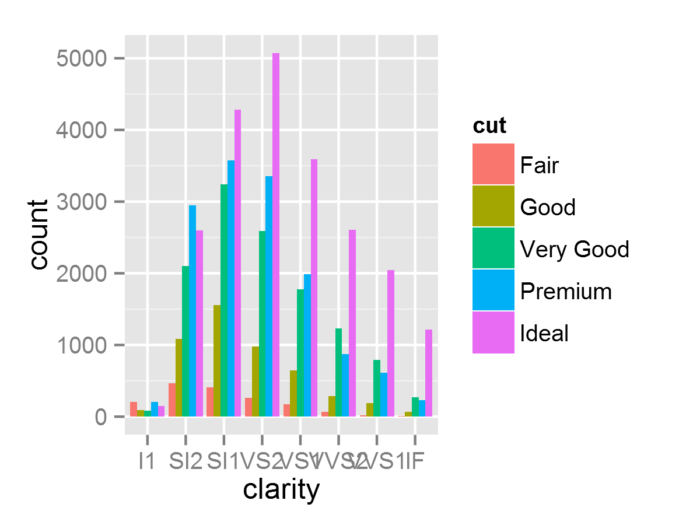
元素位置的调整共有5种包括了(1)dodge:并排方式; (2)fill:堆叠图像元素, 并将高度标准化为1, (3)identity:不做任何调整; (4)jitter:给点增加扰动避免重合和(5)stack:堆叠图像元素。
- d <- ggplot(diamonds, aes(x = clarity, fill = cut ))
- d + geom_histogram(position = "dodge")
- d + geom_histogram(position = "fill")
- d + geom_histogram(position = "stack")
- ggplot(diamonds) + geom_point(aes(color, price/carat), position = "jitter")
jitter使某每一个点在x轴的方向上产生随机的偏移, 从而减少了图形重叠的问题, 另一种介绍重叠的方式是改变点的透明度, 将在实战中的地图讨论。
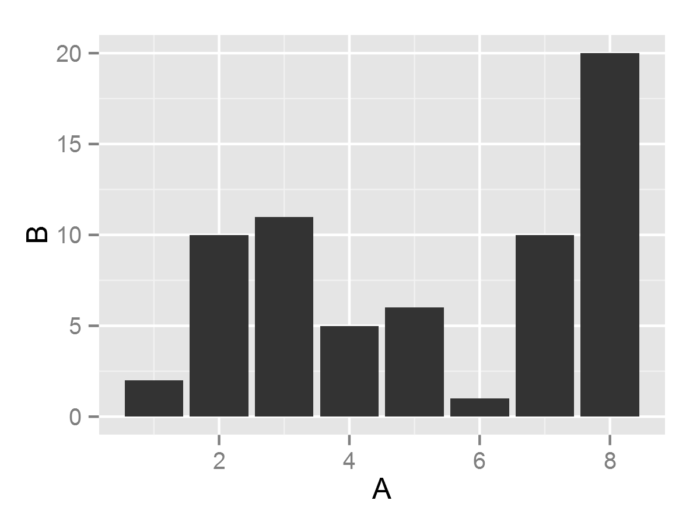
很多情况下, 我们会采用固定的x轴和y轴值来进行作图, 此时需要用stat = “identity” 来申明, 即表示不对数据进行统计变换
- A <- c(1, 2, 3, 4, 5, 6, 7, 8)
- B <- c(2, 10, 11, 5, 6, 1, 10, 20)
- ggplot() + geom_histogram(aes(x = A, y = B), stat = "identity")
(3) geom_smooth()
geom_smooth()用来给数据添加平滑曲线, 所能采用的方法包括了lm, glm, gam, loess, rlm等, 这些方法需要通过加载公式来实现。
- m <- ggplot(mtcars, aes(qsec, wt))
- m + stat_smooth() + geom_point()
- m + stat_smooth(se = FALSE) + geom_point()
- #取消默认的置信区间
- m + stat_smooth(fill = "red", size = 2, alpha = 0.5, color = "green") + geom_point()
- #更改置信区间和线条颜色
- m + stat_smooth(method = "lm") + geom_point()
- #用一元一次线性方程拟合
- m + stat_smooth(method = "lm", formula = y ~ poly(x, 3)) + geom_point()
- #使用一元二次方程拟合
- require(splines)
- require(MASS)
- m + stat_smooth(method = "lm", formula = y ~ ns(x, 3)) + geom_point()
- # 加载splines和MASS包, 使用自由度为3的自然样条来进行拟合
- m <- ggplot(mtcars, aes(y = wt, x = mpg, group = factor(cyl)))
- m + stat_smooth(method = lm, aes(color = factor(cyl), fill = factor(cyl))) + geom_point( aes(color = factor(cyl)))
- #按cyl这个离散变量进行分组, 分别拟合数据

得益于r包的丰富性, 我们可以采用极大似然或最小二乘法, 对多种现有的函数或自编函数来拟合曲线。例如,在对剂量-效应曲线绘图的实战中,采用drc包中的log-logistics四参数方程来拟合剂量-效应曲线。
在这偏不长的博文中, 很难对ggplot2中所有几何对象和统计变换一一详尽, 更详细的内容可以在ggplot2的官方索引找到。但是通过前一小节有关于图层的讲解, 我们已能很容易的通过这些组件整合出一些复杂的图形, 而这些组件的原理也是相同的。
标度(scale)
标度控制着数据到图形属性的映射, 更重要的一点是标度将我们的数据转化为视觉上可以感知的东西, 如大小、颜色、位置和形状。所以通过标度可以修改坐标轴和图例的参数。

按表1所示,所有标度构建器(scale constructor)都拥有一套通用的命名方案。它们以scale_开头, 接下来是图形属性的名称(例如, color_、shape_或x_)最后以标度的名称结尾(例如gradient、hue或manual)。从表中可以发现, 标度是区分离散和连续变量的, 因此再对标度进行调整一定要注意区分。ggplot2中的标度可以粗略的分为4类:(1)位置标度:用于将连续型、离散型和日期-时间型变量映射到绘图区域, 以及构造对应的坐标轴; (2)颜色标度:用于将连续型和离散型变量映射到颜色; (3)手动离散型标度:用于将离散型变量映射到我们选择的符号大小、线条类型、形状或颜色, 以及创建对应的图例; 以及(4)同一型标度:用于直接将变量值绘制为图形属性, 而不去映射他们。
实际应用中修改标度最长用的有3个方面(1)修改图例和(2)修改图形属性和(3)修改坐标轴, 介于内容的复杂性, 建议详细的参考如下链接:
(1)索引中有关scale的内容:http://docs.ggplot2.org/current/index.html
(2)cookbook中有关图例的修改:
http://www.cookbook-r.com/Graphs/Legends_(ggplot2)/
(3)cookbook中有关坐标轴的修改:
http://www.cookbook-r.com/Graphs/Axes_(ggplot2)/
(4)ColorBrewers配色方案:
在后面的实例中, 每一张完美的图都需要对其标度进行细致的修改。
分面(facet)
即在一个页面上自动摆放多幅图形, 这一过程先将数据划分为多个子集, 然后将每个子集依次绘制到页面的不同面板中。ggplot2提供两种分面类型:网格型(facet_grid)和封面型(facet_wrap)。网格分面生成的是一个2维的面板网格, 面板的行与列通过变量来定义, 本质是2维的; 封装分面则先生成一个1维的面板条块, 然后再分装到2维中, 本质是1维的。
在很多情况下, 我们可能需要绘制有两个y轴的坐标系, 而在ggplot2中, 这种做法特别不提倡(stackover的讨论), 可解决的方法要么是把变量归一化, 要么便是采用分面方法。
- p <- ggplot(mtcars, aes(mpg, wt)) + geom_point()
- p + facet_grid(. ~ cyl) #以cyl为分类变量
- p + facet_wrap( ~ cyl, nrow = 3) #wrap与grid的区别
- p + facet_grid(cyl ~ .) #以cyl为分类变量
- p + facet_wrap( ~ cyl, ncol = 3) #wrap与grid的区别
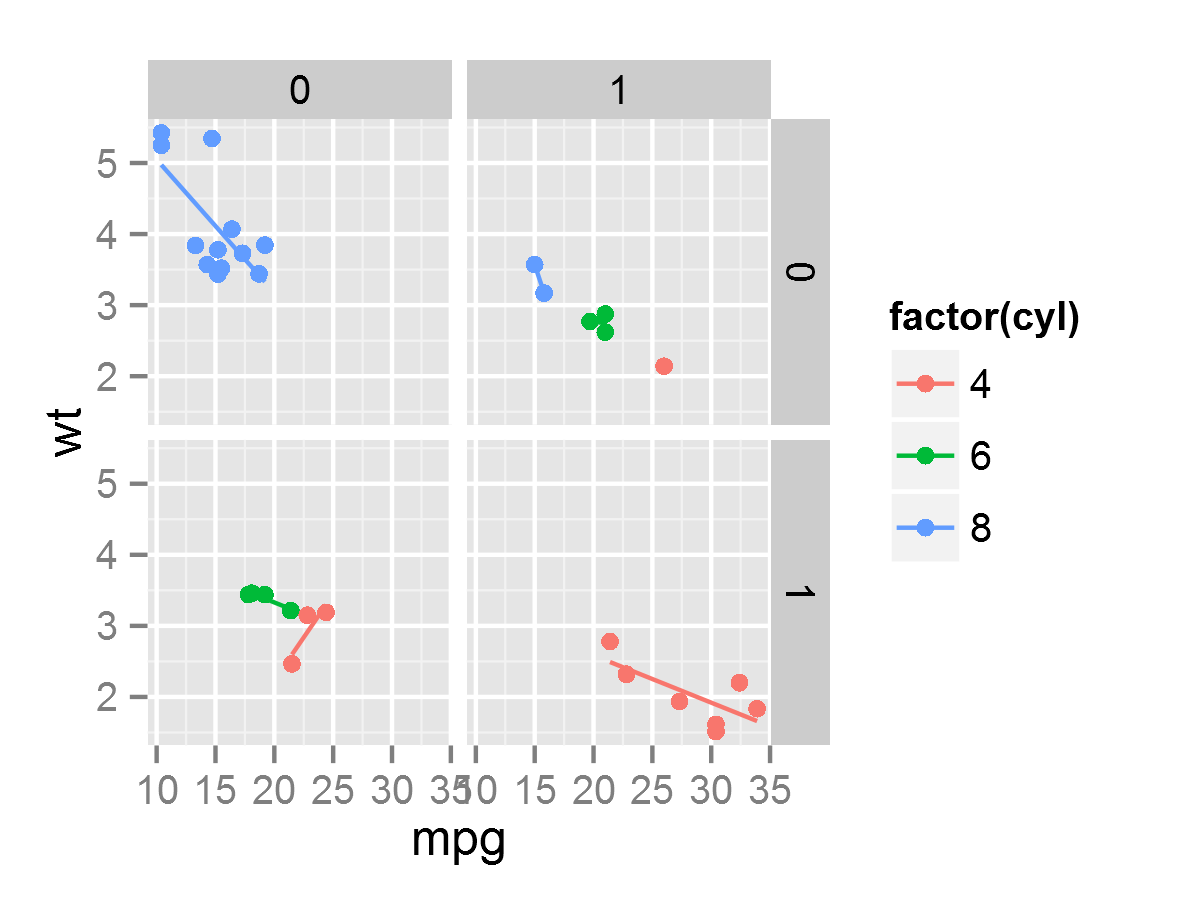
- p + facet_grid(vs ~ am) #以vs和am为分类变量
- p + facet_wrap(vs ~ am, ncol = 2) #wrap与grid 的区别
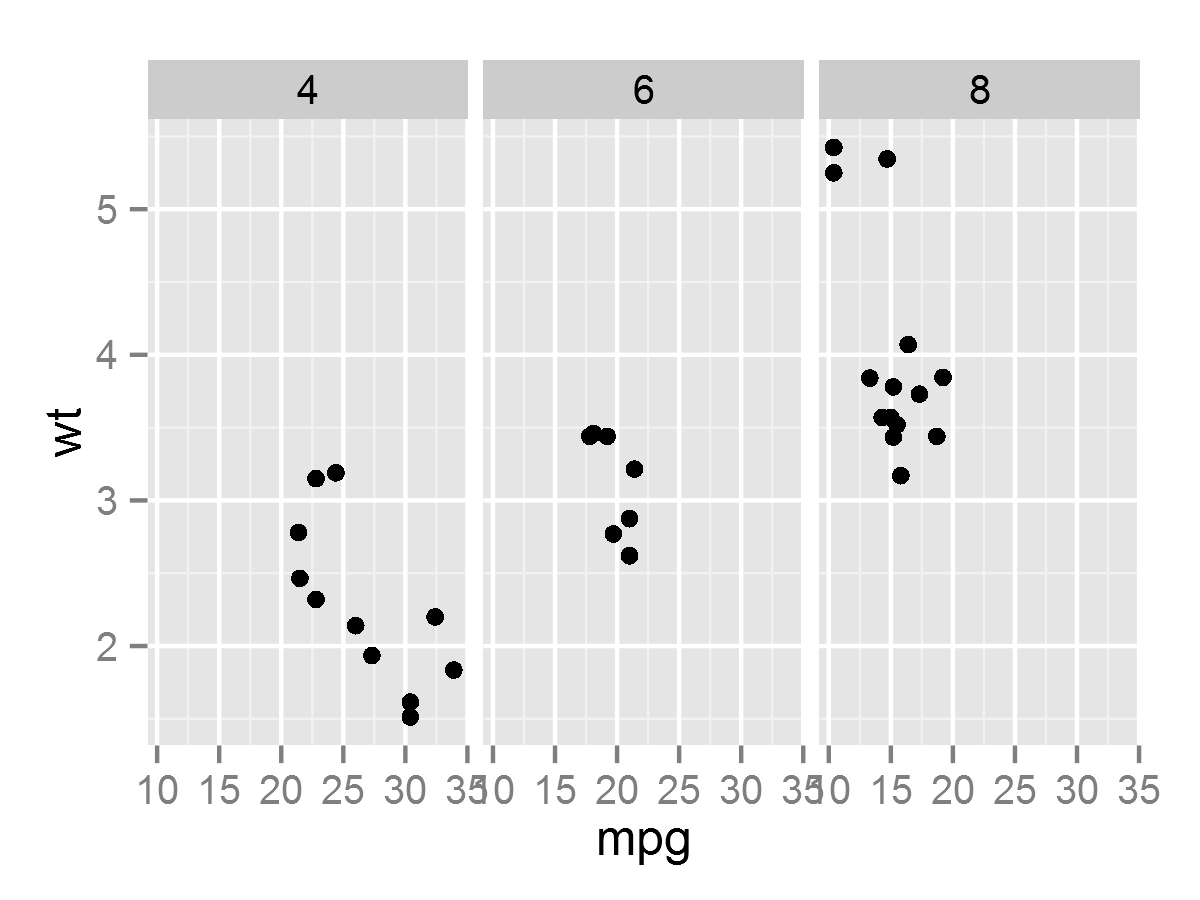
- p <- p + geom_smooth(method = "lm", se =F, aes(color = factor(cyl))) + geom_point(aes(color = factor(cyl)))
- p + facet_grid(vs ~ am)
- p + facet_grid(vs ~ am, margins = T) #使用margins来描述边际图
- p + facet_grid( ~ cyl, scales = "free")
- p + facet_grid( ~ cyl, scales = "free_x")
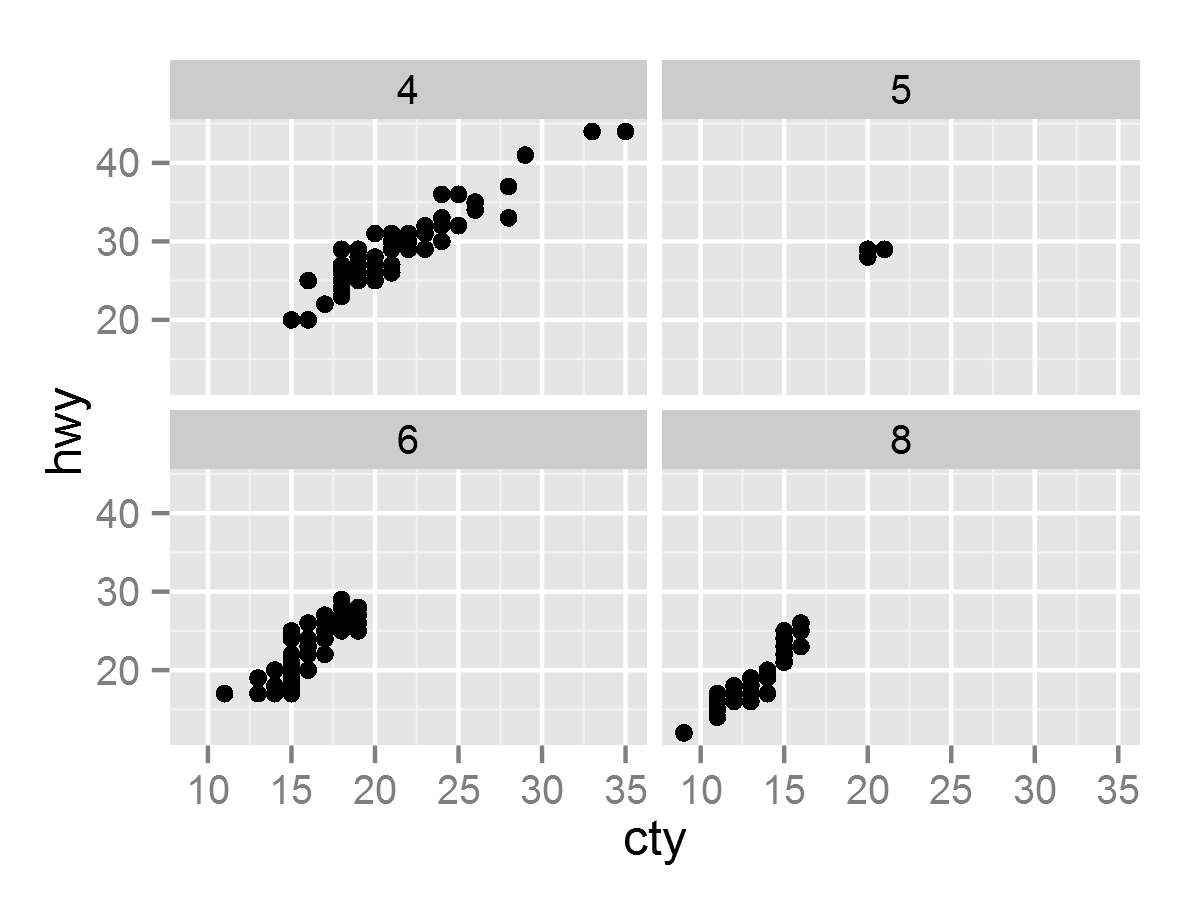
- p <- ggplot(aes(cty, hwy), data = mpg) + geom_point()
- p + facet_wrap( ~ cyl)
- #调整scales的标度, 共有fixed, free, free_x和free_y四种变换
- p + facet_wrap( ~ cyl, scales = "free") # 这里标度更改为free
- p + facet_grid(. ~ cyl, scales = "free", space = "free")
- #space设置为free时, 每列的宽度与该列的标度范围成比例
- ##使用自由标度来替代<strong>双坐标轴</strong>的实战的一个例子中
主题(theme)
主题系统控制着图形中的非数据元素外观, 它不会影响几何对象和标度等数据元素。主题修改是一个对绘图精雕细琢的过程, 主要对标题、坐标轴标签、图例标签等文字调整, 以及网格线、背景、轴须的颜色搭配。
- p <- ggplot(movies, aes(x = rating)) + geom_histogram(bin = 1)
- p + theme_bw() #白色背景
- p + theme_grey() #默认浅灰色背景

主题由控制图形外观的多个元素组成, 详见官方索引
- ##element_text()修改标签和标题
- p <- p + labs(title = "histogram")
- p + theme(plot.title = element_text(size = 20, color = "red",
- hjust = 0, face = "bold",
- angle = 180))

内置元素共有四个基础类型:文本(text), 线条(line)、矩形(rectangle)、空白(blank), text与其他类型操作相类似, 具体的例子可参考索引, 此处用element_blank()来去除灰色背景。
- p + theme(panel.background = element_blank()) #blank是去掉某种绘图元素
输出(ggsave)
ggsave()是ggplot2种特有的输出函数, 是一种极为方便的出图方式
- p <- ggplot(mtcars, aes(x = mpg, y = disp)) + geom_point()
- ggsave( file = "mtcars_plot.png", width = 5, height = 6, type = "cairo", dpi = 600)
- #cairo为抗锯齿包, ggplot默认输出即为cairo处理
ggplot2支持eps矢量图输出, 其他可以支持的格式包括png, jpg, pdf等, 并通过ggsave可以方便的进行修改。
ggplot2作图实战
时间序列
- #用excel导入数据, 格式为csv
- ori.data <- read.csv("lesson8.csv", header = F)
- #以矩阵的方式读入数据, 按行排列, 每三列换一行
- data <- matrix(as.matrix(ori.data), nrow(ori.data) / 3, 3, byrow = TRUE)
- #关闭区域特定的时间编码方式
- Sys.setlocale("LC_TIME", "C")
- #用as.POSIXlt()读入字符串数据并转化为date数据, 赋值给date, 或as.Date()
- date <- as.POSIXlt(data[, 1], tz = "", "%a %b %d %H:%M:%S HKT %Y")
- #对ip和pv所在的列转化为数值型
- IP <- as.numeric(data[, 2])
- PV <- as.numeric(data[, 3])
- head(data)
- #恢复区域特地的时间编码方式
- Sys.setlocale("LC_TIME", "")
- #用ggplot2绘图
- require(ggplot2)
- #用reshape包中的melt函数分解数据
- require(reshape2)
- p.data <- data.frame(date, IP, PV)
- meltdata <- melt(p.data, id = (c("date")))
- #用对IP和PV做分页处理, y轴刻度自由变化
- graphic <- ggplot(data = meltdata, aes(x = date, y = value, color = variable)) + geom_line() + geom_point()
- graphic <- graphic + facet_grid(variable ~ ., scales = "free_y")
- #美化, 添加标题, 坐标, 更改图例
- graphic<- graphic + labs(x = "日期", y = "人次", title = "某网站7月至10月IP/PV统计") +
- theme(plot.title = element_text(size = 20, face = "bold")) +
- scale_colour_discrete(name = "",labels = c("IP","PV")) +
- theme(strip.text.y = element_text(angle = 0))

地图
- require(maps)
- require(ggplot2)
- #用直方图看下pop整体的分布
- #可以发现数据分布较变化较大, 所以对pop做log转化
- qplot(pop, data = us.cities, binwidth = 0000, geom = "histogram")
- qplot(log(pop), data = us.cities, binwidth = 0.03, geom = "histogram")
- #绘制背景地图
- USA.POP <- ggplot(us.cities, aes(x = long, y = lat)) + xlim(-130, -65) + borders("state", size=0.5)+
- geom_point(aes(size = log(pop), color = factor(capital), alpha = 1/50))+
- #对size标度的调整参考http://docs.ggplot2.org/0.9.3.1/scale_size.html
- scale_size(range=c(0, 7), name = "log(City population)")+
- #对离散型颜色变量的标度调整参考http://docs.ggplot2.org/0.9.3.1/scale_manual.html
- #对连续型颜色标量的标度调整参考http://docs.ggplot2.org/0.9.3.1/scale_brewer.html
- #和http://docs.ggplot2.org/0.9.3.1/scale_gradient2.html
- scale_color_manual(values = c("black", "red"), labels = c("state capital", "city"))+
- #调整图例
- guides(color = guide_legend(title=NULL)) + scale_alpha(guide = FALSE)+
- #绘制标题和坐标轴
- labs(x = "longtitude", y = "latitude", title = "City Population in the United States")+
- theme(plot.title = element_text(size=20))
- #输出图像 并用cairo包进行抗锯齿处理
- ggsave(USA.POP, file = "USA_POP.png", type = "cairo", width = 10, height = 6.75)
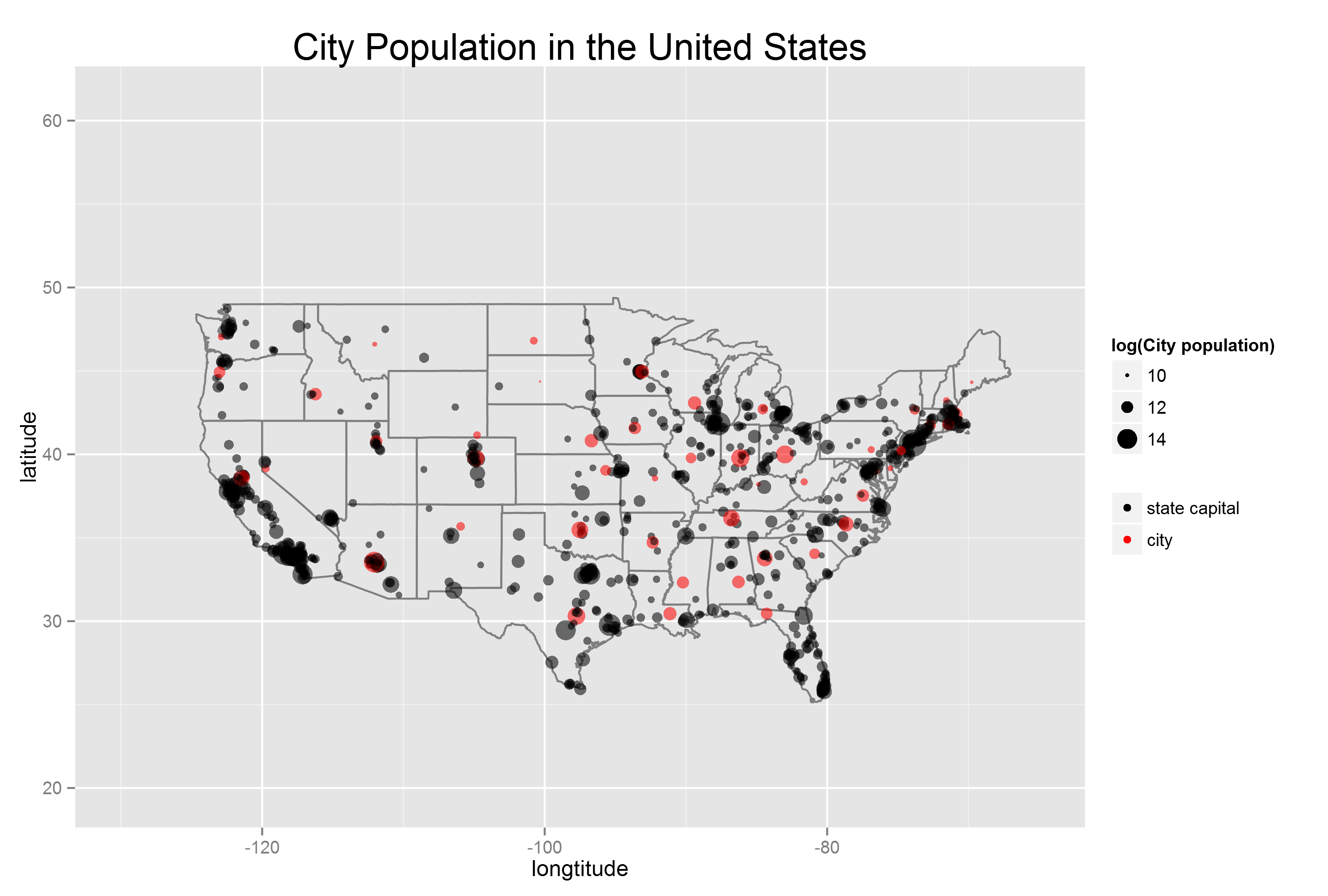
当然, 这只是简单的地图绘制方法,统计之都上也有很多大牛来用R绘制各种各样精美的地图(1, 2)。
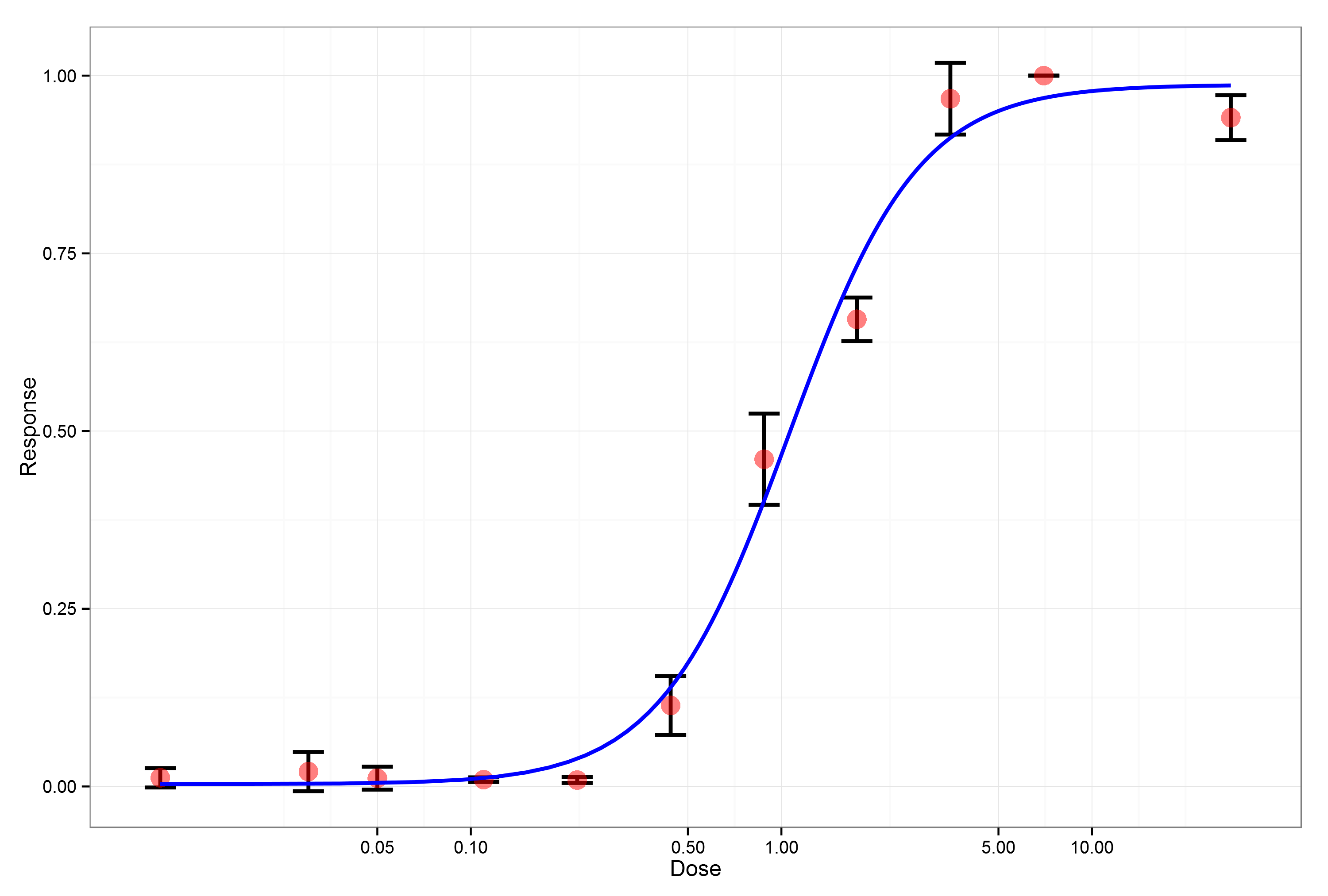
剂量-效应曲线
R中的drc包很容易对各种剂量-效应曲线进行绘图,此处采用较为常用的log-logistic四参数方程拟合了剂量-效应曲线。
- ori.data <- read.csv("D-R curve.csv")
- require(drc)
- require(reshape2)
- #把数据融合
- melt.data <- melt(ori.data, id = c("dose"), value.name = "response")[, -2]
- #用drc包中的log-logistic四参数方程进行拟合建模
- model <- drm(response ~ dose, data = melt.data, fct = LL.4(names = c("Slope", "Lower Limit", "Upper Limit", "EC50")))
- #确定x轴范围并构建数据集
- min <- range(ori.data$dose)[1]
- max <- range(ori.data$dose)[2]
- line.data <- data.frame(d.predict = seq(min, max, length.out = 1000))
- #用模型预测数据构建数据集
- line.data$p.predict <- predict(model, newdata = line.data)
- #构建绘图数据, 能够计算误差棒
- require(plyr)
- p.data <- ddply(melt.data, .(dose), colwise(mean))
- p.data$sd <- ddply(melt.data, .(dose), colwise(sd))[,2]
- require(ggplot2)
- p <- ggplot() +
- geom_errorbar(data = p.data, width = 0.1, size = 1,
- aes(ymax = response + sd, ymin = response - sd, x = dose)) +
- geom_point(data = p.data, aes(x = dose, y = response),
- color = "red", alpha = 0.5, size = 5) +
- geom_line(data = line.data, aes(x = d.predict, y = p.predict),
- size = 1, color = "blue") +
- #改变坐标轴间隔
- scale_x_log10(name = "Dose",
- breaks=c(0.05, 0.1, 0.5, 1, 5, 10, 50, 100)) +
- scale_y_continuous(name = "Response") +
- theme_bw()
- #查看拟合模型参数
- summary(model)
邪恶之图
绘图参数来自知乎, 此处亦有3D版本赠送
- ##用ggplot2来画函数
- library(ggplot2)
- #确定x轴区域
- f <- ggplot(data.frame(x = c(0.00001, 1)), aes(x, color="pink", size=2))
- test <- function(x) {(1/36)*exp(-((36*x-36/2.71828182845905)^4))-3*x*log10(x)}
- f <- f + stat_function(fun = test)+theme(legend.position="none") +
- #旋转坐标轴
- coord_flip()
- f

注:封面图片来自facebook社交数据可视化
更多实战
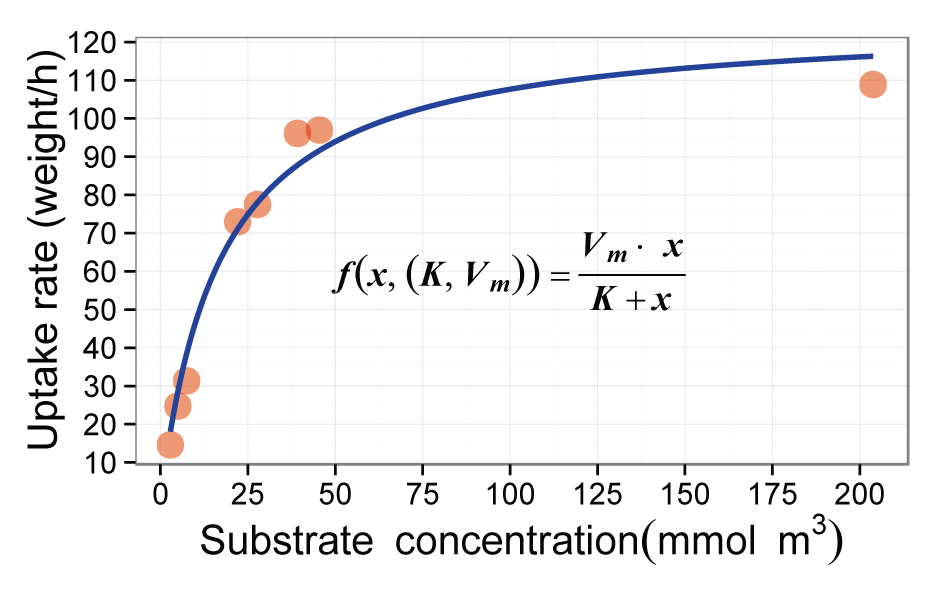
例一 Michaelis-Menten动力学方程
这个例子中采用出自文献中的一组有关于浮萍氮摄取的数据,共2两个变量8个观测值,其中底物浓度与浮萍的氮取速率之间可以通过M-M动力学方程来进行描述。在这个例子中首先通过nls()根据M-M动力学方程进行模型拟合,然后用预测值进行了ggplot2绘图,主要采用了R里面的数学表示方法plotmath在图中展示了公式,并通过ggplot2种的theme对图像进行了修饰。需要注意的在geom_text()并不能直接使用expression,需要开启parse = TURE,且用字符串表示。
- conc <- c(2.856829, 5.005303, 7.519473, 22.101664, 27.769976, 39.198025, 45.483269, 203.784238)
- rate <- c(14.58342, 24.74123, 31.34551, 72.96985, 77.50099, 96.08794, 96.96624, 108.88374)
- L.minor <- data.frame(conc, rate)
- L.minor.m1 <- nls(rate ~ Vm * conc/(K + conc), data = L.minor, #采用M-M动力学方程
- start = list(K = 20, Vm = 120), #初始值设置为K=20,Vm=120
- trace = TRUE) #占线拟合过程
- #确定x轴范围并构建数据集
- min <- range(L.minor$conc)[1]
- max <- range(L.minor$conc)[2]
- line.data <- data.frame(conc = seq(min, max, length.out = 1000))
- #用模型预测数据构建数据集
- line.data$p.predict <- predict(L.minor.m1, newdata = line.data)
- require(ggplot2)
- M_Mfunction <- ggplot() +
- geom_point(aes(x = conc, y = rate), data = L.minor,
- alpha = 0.5, size = 5, color = "red") +
- geom_line(aes(x = conc, y = p.predict), data = line.data,
- size = 1, color = "blue") +
- scale_x_continuous(
- name = expression(Substrate ~~ concentration(mmol ~~ m^3)),#采用expression来表示数学公式
- breaks = seq(0, 200, by = 25)) +
- scale_y_continuous(
- name = "Uptake rate (weight/h)",
- breaks = seq(0, 120, by = 10)) +
- geom_text(aes(x = 100, y = 60),
- label = "bolditalic(f(list(x, (list(K, V[m])))) == frac(V[m]%.%x, K+x))",
- #注意 geom_text中如果用expression()来进行表达,必须开启parse = TRUE
- #同时以字符串""的形式表示,不能使用expression
- parse = TRUE,
- size = 5, family = "times"
- ) +
- theme_bw() +
- theme(
- axis.title.x=element_text(size=16),
- axis.title.y=element_text(size=16),
- axis.text.x=element_text(size=12),
- axis.text.y=element_text(size=12))
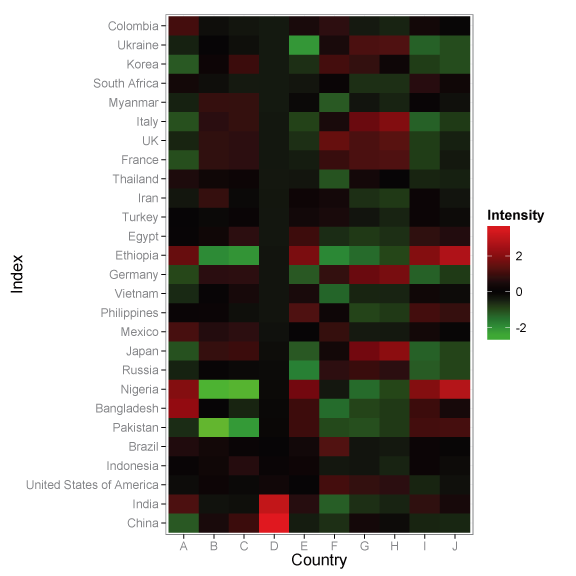
例二 热图
热图是一种极好的数据可视化方式,能够清楚的显示出多维数据之间的关联性和差异性,糗世界已经为我们展现了R里面所常用的heatmap,ggplot2和lattice3种热图绘制方式,当然随着R的不断进步,已经有多种包提供了更丰富和更简单的热图绘制方式,例如gplots中的heatmap.2,pheatmap,heatmap.plus等等。ggplot2进行热图的绘制也十分方便,热图的关键是聚类,两个可行的方案是对聚类结果进行排序和将聚类结果因子化后固定,通过结合plyr包,可以很方便的实现。这里采用一组来源于WHO国家数据来对热图的绘制进行,首先数据标准化和正态化后按Index的D(为各国的人口数据)进行排序,再将其因子化后固定,用geom_tile()进行热图的绘制,在ggplot2种已能通过scale_fill_gradient2在三种基本色进行渐变。
- WHO<-read.csv("WHO.csv", header = TRUE)
- require(plyr)
- #按总人口数排列数据
- WHO<-arrange(WHO, desc(D))
- #将数据的名字转换为因子,并固定已拍好的country,
- #同理可以按照聚类的结果进行排列
- WHO<- transform(WHO, Country = factor(Country, levels = unique(Country)))
- require(reshape2)
- require(ggplot2)
- require(scales)
- require(grid)
- #melt数据
- m.WHO <- melt(WHO)
- #标准化,每排数据映射到按最小值和最大值映射到(0,1)区间
- m.WHO <- ddply(m.WHO, .(variable), transform, rescale = rescale(value))
- #标准化并正态化数据
- s.WHO <- ddply(m.WHO, .(variable), transform, rescale = scale(value))
- require(ggplot2)
- p<-ggplot(s.WHO, aes(variable, Country)) +
- #用tile来进行绘热力图
- geom_tile(aes(fill=rescale)) +
- scale_fill_gradient2(mid="black", high="red", low="green", name = "Intensity") +
- labs(x="Country", y="Index", face = "bold") +
- theme_bw() +
- theme(
- axis.title.x=element_text(size=16),
- axis.title.y=element_text(size=16),
- axis.text.x=element_text(size=12, colour="grey50"),
- axis.text.y=element_text(size=12, colour="grey50"),
- legend.title=element_text(size=14),
- legend.text=element_text(size=12),
- legend.key.size = unit(0.8, "cm"))#需要载入grid包来调整legend的大小
例三 动态图
相信很多人都被Hans Rosling在TED和BCC展现的动态散点图所惊艳到,这是一种多维数据展现方式,并成功的加入了时间这一维度,各路牛人都用不同的手段进行了实现,精彩的作品例如d3.js,和基于google charts API的googlevis。统计之都的魔王大人也用ggplot2结合animation包和ffmpeg进行了绘制。但ggplot2生成动态图比较简陋,主要的原理是一次输出多张按年份排列的图片,再将这些图片按顺序结合生成视频或动态图。在dataguru的课程上我使用循环并结合paste循环输出了如下的动态图,详细的代码请移步
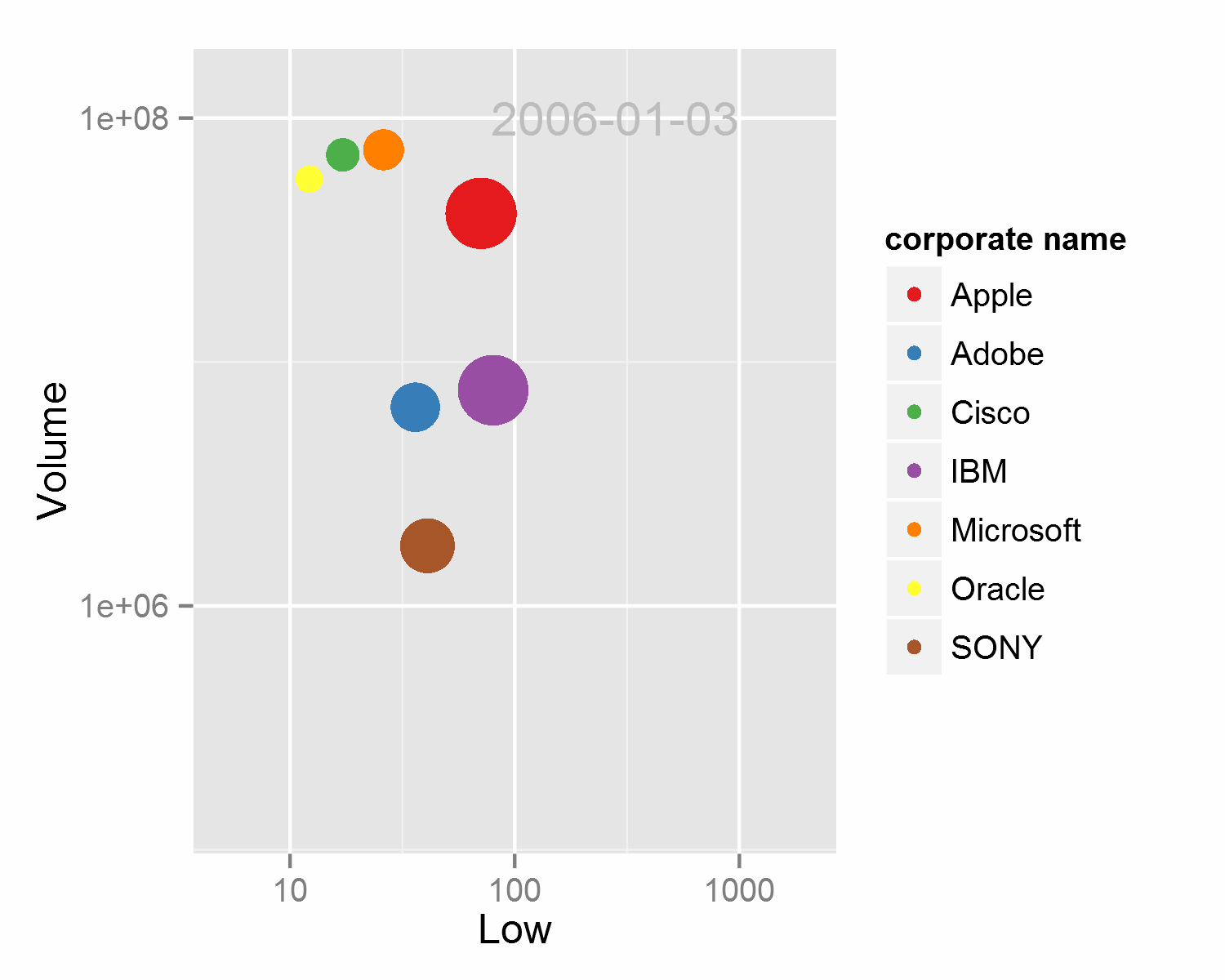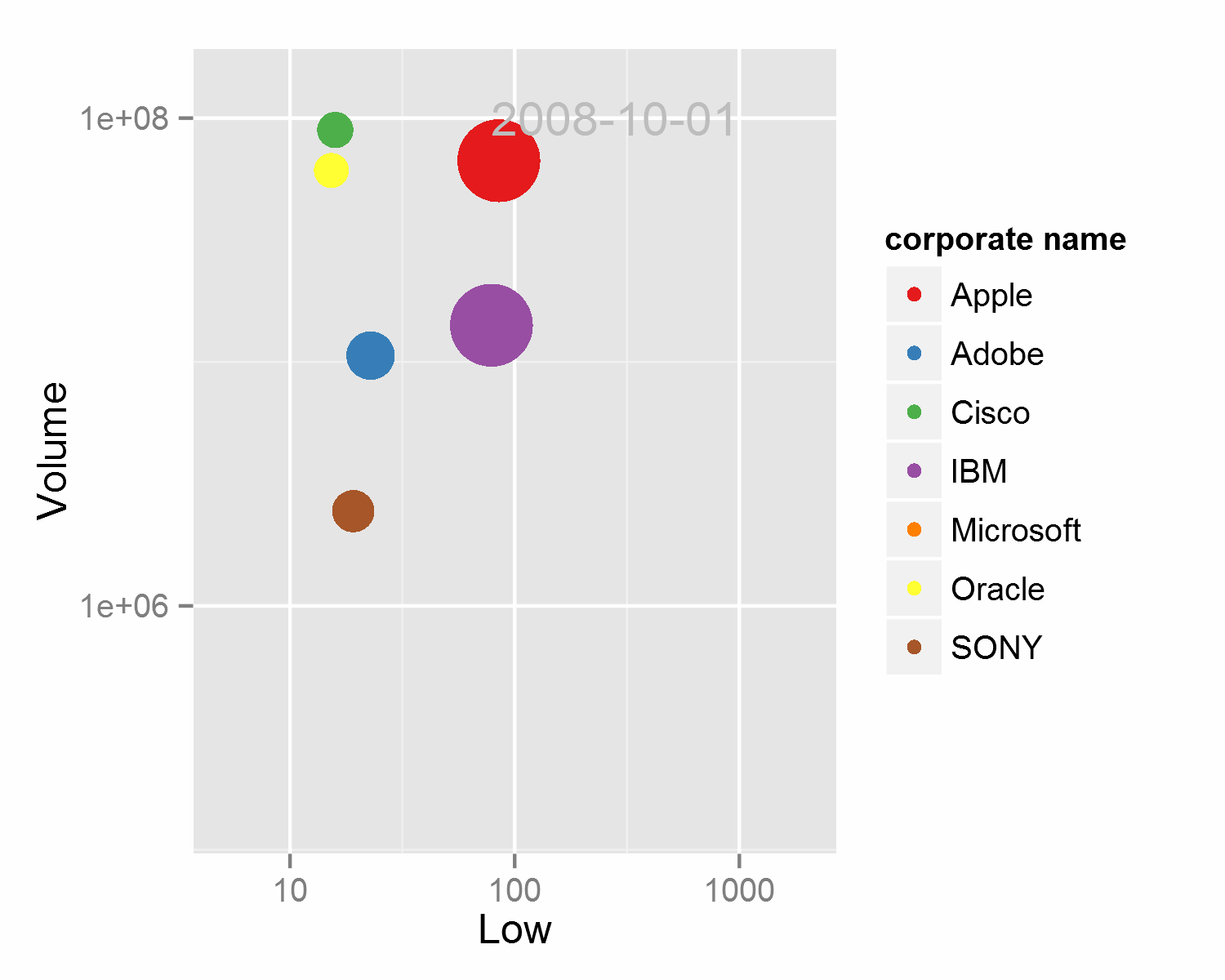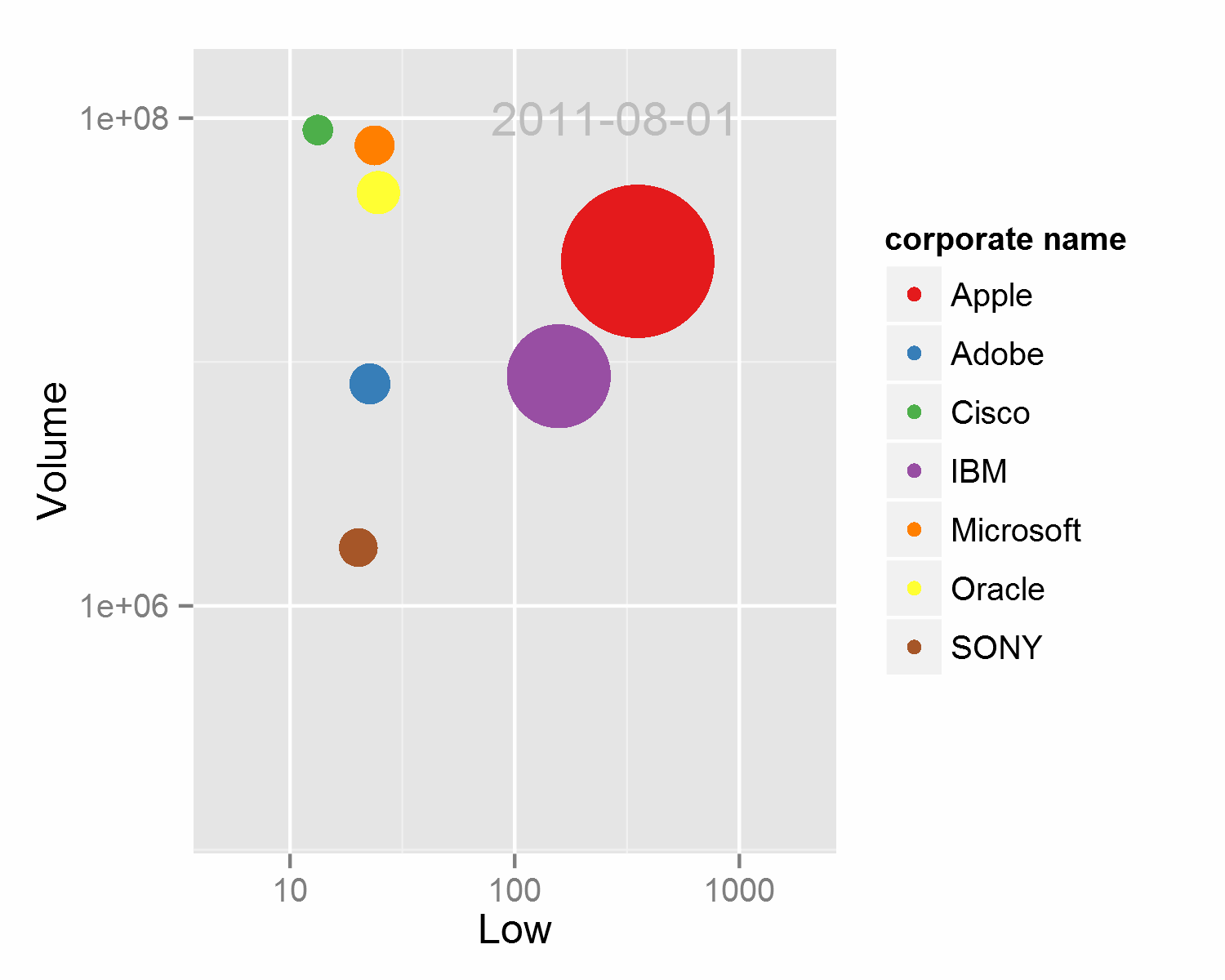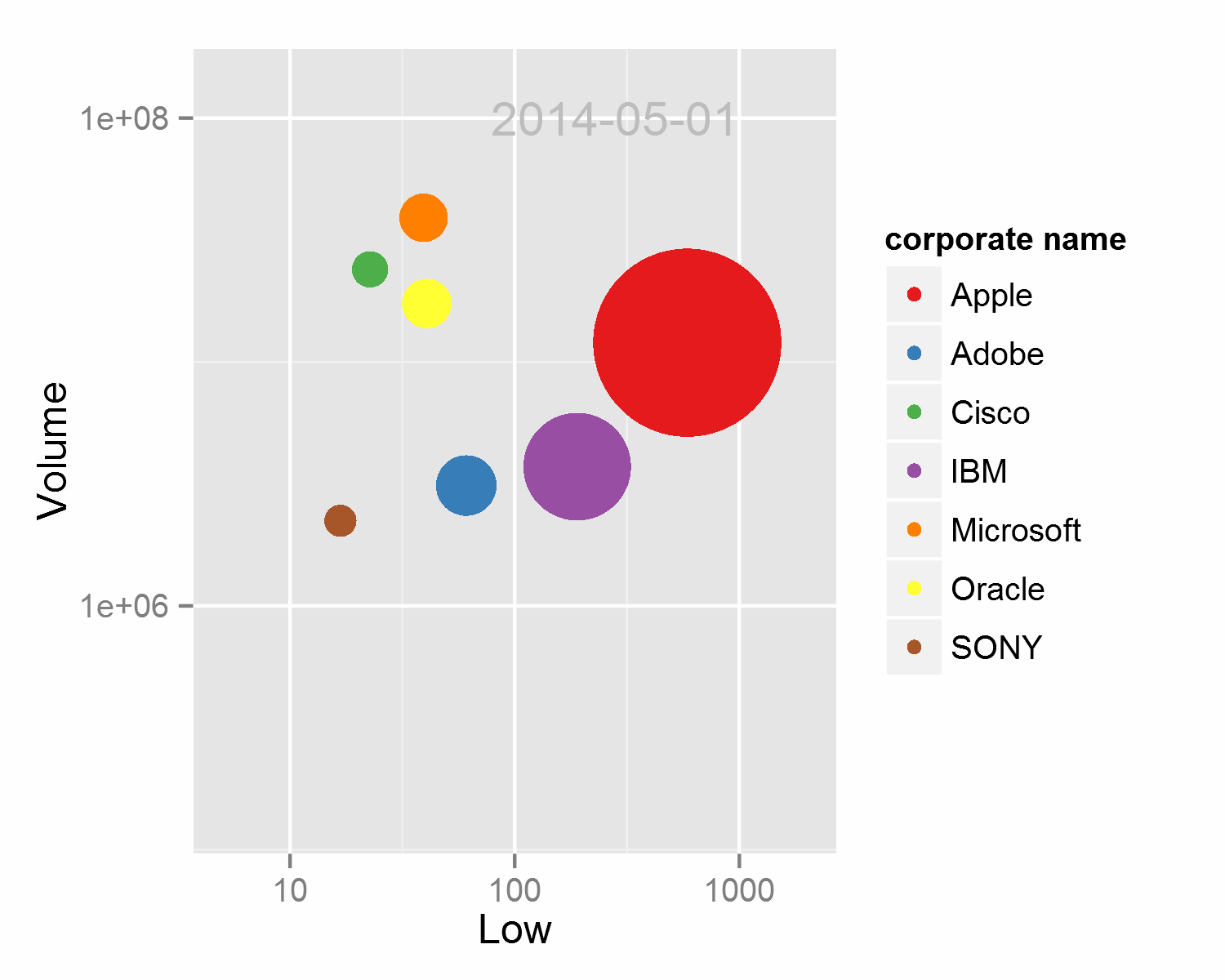
例四 火山图
火山图是散点图的一种,能够快速的辨别出大型数据集重复变量之间的差异,具体的介绍可以参考wiki和Colin Gillespie的博客,下面的代码和图是使用ggplot2的实现方式。
- require(ggplot2)
- ##change theme##
- old_theme <- theme_update(
- axis.ticks=element_line(colour="black"),
- panel.grid.major=element_blank(),
- panel.grid.minor=element_blank(),
- panel.background=element_blank(),
- axis.line=element_line(size=0.5)
- )
- ##Highlight genes that have an absolute fold change > 2 and a p-value < Bonferroni cut-off
- a <- read.table("flu.txt",header=TRUE,sep="\t",)
- P.Value <- c(a$P.Value)
- FC <- c(a$FC)
- df <- data.frame(P.Value, FC)
- df.G <- subset(df, log2(FC) < -1& P.Value < 0.05) #define Green
- df.G <- cbind(df.G, rep(1, nrow(df.G)))
- colnames(df.G)[3] <- "Color"
- df.B <- subset(df, (log2(FC) >= -1 & log2(FC) <= 1) | P.Value >= 0.05) #define Black
- df.B <- cbind(df.B, rep(2, nrow(df.B)))
- colnames(df.B)[3] <- "Color"
- df.R <- subset(df, log2(FC) > 1 & P.Value < 0.05) #define Red
- df.R <- cbind(df.R, rep(3, nrow(df.R)))
- colnames(df.R)[3] <- "Color"
- df.t <- rbind(df.G, df.B, df.R)
- df.t$Color <- as.factor(df.t$Color)
- ##Construct the plot object
- ggplot(data = df.t, aes(x = log2(FC), y = -log10(P.Value), color= Color )) +
- geom_point(alpha = 0.5, size = 1.75) +
- theme( legend.position = "none") +
- xlim(c(-5, 5)) + ylim(c(0, 20)) +
- scale_color_manual(values = c("green", "black", "red")) +
- labs(x=expression(log[2](FC)), y=expression( -log[10](P.Value))) +
- theme(axis.title.x=element_text(size=20),
- axis.text.x=element_text(size=15)) +
- theme(axis.title.y=element_text(size=20),
- axis.text.y=element_text(size=15))

再说高质量图片输出
绘图完成后最后一步便是图片输出,高质量的图片输出让人赏心悦目,而不正确的输出方式或者直接采用截图的方式从图形设备中截取,得到的图片往往是低劣的。一幅高质量的图片应当控制图片尺寸和字体大小,并对矢量图进行高质量渲染,即所谓的抗锯齿。R语言通过支持Cairo矢量图形处理的类库,可以创建高质量的矢量图形(PDF,PostScript,SVG) 和 位图(PNG,JPEG, TIFF),同时支持在后台程序中高质量渲染。在ggplot2我比较推荐的图片输出格式为经过Cairo包处理的PDF,因为PDF格式体积小,同时可以储存为其他任何格式,随后再将PDF储存为eps格式并在Photoshop中打开做最终的调整,例如调整比例、色彩空间和dpi(一般杂志和出版社要求dpi=300以上)等。额外需要注意的是ggplot2中的字体大小问题,在cookbook-r一书中指出,在ggplot2中绝大多数情况下,size的大小以mm记,详细的讨论也可以参考stackover的讨论,而在theme()中对element_text()里的size进行调整,此时的size是以磅值(points, pts)来进行表示。
下面以3种ggplot2种常用的图片输出方式,输出一幅主标题为20pts,横纵坐标标题为15pts,长为80mm(3.15in),宽为60mm(2.36in)的图为例。
- require(ggplot2)
- require(Cairo)
- ggplot() +
- geom_text(aes(x = 16, y = 16), label = "ABC", size = 11.28) + #尺寸为11.28mm,即为32磅
- geom_text(aes(x = 16, y = 14.5), label = "ABC", size = 32) + #尺寸为32mm
- labs( x = "x axis", y = "y axis") +
- ylim( c(14, 16.5)) +
- xlim( c(15.75, 16.25)) +
- theme(
- axis.title.x = element_text(size = 32),#尺寸为32磅
- axis.title.y = element_text(size = 32))#尺寸为32磅
- x <- seq(-4,4, length.out = 1000)
- y <-dnorm(x)
- data <- data.frame(x, y)
- #用Cairo包输出
- require(Cairo)
- CairoPDF("plot1.pdf", 3.15, 3.15) #单位为英寸
- ggplot(data, aes(x = x, y = y)) + geom_line(size = 1) +
- theme_bw()
- dev.off() #关闭图像设备,同时储存图片
- plot2 <- ggplot(data, aes(x = x, y = y)) + geom_line(size = 1) +
- theme_bw()
- #用ggsave输出,默认即以用Cairo包进行抗锯齿处理
- ggsave("plot2.pdf", plot2, width = 3.15, height = 3.15)
- #RStudio输出
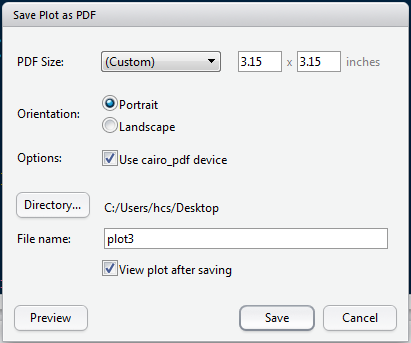
更改默认字体或者采用中文输出图片是十分恼人的一件事情,好在我们还有各种拓展包和功能强大的Rstudio来实现。
用extrafont输出英文字体
extrafont包能够直接调用字体文件,再通过Ghostscript(需要安装)将写入的字体插入生成的PDF中,具体代码可参考了作者说明
好玩的showtext
邱怡轩大神写了一个好玩的showtext,确实好好玩~
简单易用的RStudio输出
最简单实用的输出方法还是使用RStudio输出,直接调用系统字体(我的是win7,mac和linux下还没有试过)并输出即可
- #showtext
- require(showtext)
- require(ggplot2)
- require(Cairo)
- font.add("BlackoakStd", "C://Windows//Fonts//BlackoakStd.otf")
- font.add("BrushScriptStd", "C://Windows//Fonts//BrushScriptStd.otf")
- font.add("times", "C://Windows//Fonts//times.ttf")
- font.add("STHUPO", "C://Windows//Fonts//STHUPO.ttf")
- CairoPDF("showtext_output", 8, 8)
- showtext.begin()
- ggplot() +
- geom_text(aes(x = 16, y = 16.25), label = "Blackoak Std", size = 8,
- family = "BlackoakStd") +
- geom_text(aes(x = 16, y = 16), label ="Brush Script Std", size = 16,
- family = "BrushScriptStd") +
- geom_text(aes(x = 16, y = 15.75), label = "Times New Roman", size = 16,
- family = "times") +
- geom_text(aes(x = 16, y = 15.50), label = "华文琥珀", size = 16,
- family = "STHUPO") +
- ylim(c(15.25, 16.50)) +
- labs(x = "", y = "") +
- theme_bw() #在用RStudio输出

1F
链接和数据下载不了啦
2F
数据下载不了