

本文出自Bin的专栏blog.csdn.net/xbinworld。 技术交流QQ群:433250724,欢迎对算法、技术感兴趣的同学加入。我的博客写一些自己用得到东西,并分享给大家,如果有问题欢迎留言与我讨论:)
Kmeans聚类方法是(我认为)最广泛使用以及稳定、有效的聚类方法。聚类是无监督学习方法,不需要对数据本身的标签有任何了解。如果你不是很理解kmeans算法本身,建议随便找一本数据挖掘/机器学习的书来看一看,或者看下baidu[1]的内容基本就能理解。
Kmeans算法基本描述
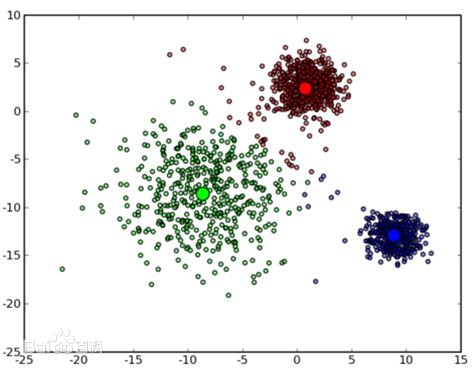
基本算法这里只做最为简单的描述,供读者理解,下图是一个聚类后的示意图。
(1) 从 n个数据对象任意选择 k 个对象作为初始聚类中心点;
(2) 根据每个聚类对象的均值(中心点),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分;
(3) 重新计算每个(有变化)聚类的均值(中心点)
(4) 循环(2)到(3)直到每个聚类不再发生变化为止
用Parametric Bootstrap方法确定K的取值
我们知道,在实际应用中,我们并不知道数据应该被聚类成几类(K=?),因为数据往往是高维的且交杂在一起。如何确定一个好的K,本身是一个值得研究的课题,也有不少人提出过不少方法,在本文中,我具体描述一下用Parametric Bootstrap方法来确定K值,主要参考的是[2],看下来感觉方法简单实用,在这里用自己的话描述一遍,并做适当衍生。
假设下图是我们的数据样本集合(每一个点表示一个样本),打印在二维平面上:
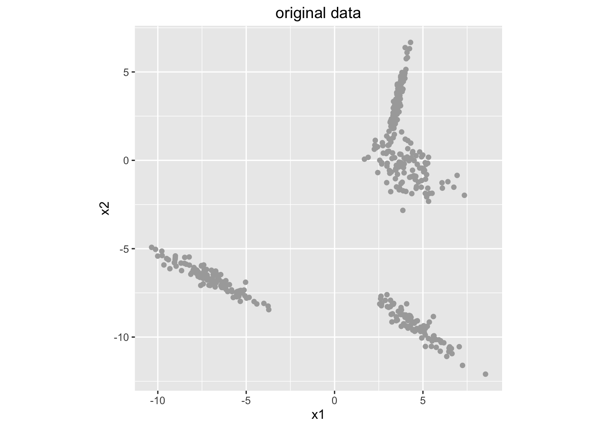
首先,我们并不知道数据应该聚成几类(实际中我们是不太可能看得到高维数据有很明显的分割的。在这个例子中乍一看好像是3类,但是实际上,我们的数据是通过4个混合高斯分布生成的。),所以假设数据应该分成k=2类,结果是:
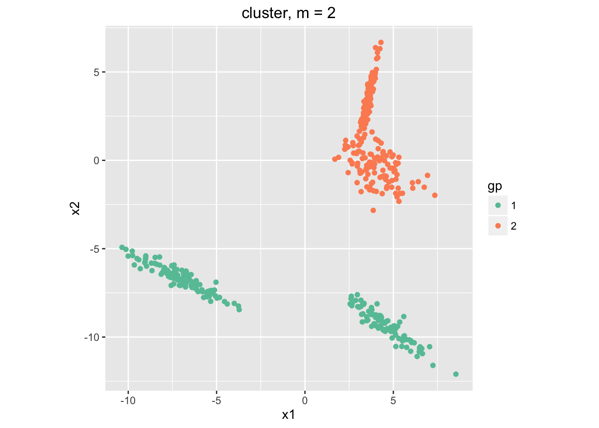
这样,我们通过kmeans(k=2)把数据分为两类——橘色和绿色。我们可以得到两类的均值和协方差矩阵。假设原始数据是从高斯分布中随机生成的,那我们就可以用具有所求均值和协方差矩阵的高斯分布来重新生成数据样本集合,两类,和源数据的两类size一样,结果是:
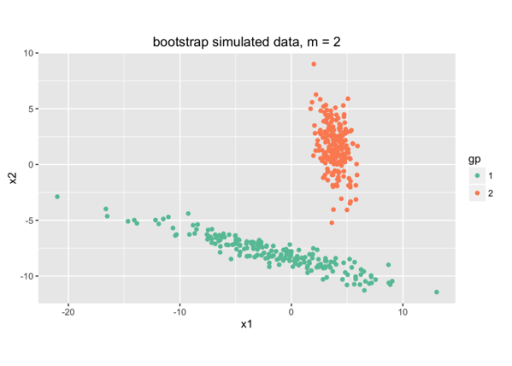
这些模拟生成的点集合 称为”bootstrap simulation“。
接下来,我们我们考察k=3的情况下聚类是否比k=2更好。我们需要一个指标来评估聚类的效果好坏,在这里简单地使用总体类内误差——total within-sum-of-squares (total WSS) ——来评估。直觉上来说,一个好的聚类它的总体类内误差WSS要比一个坏的聚类WSS值低;但是实际上,如果我们在k=2用kmeans聚类得到的WSS值,总是比k=3得到的WSS值要高,因为我们k变大以后每一个类变得更紧凑,因此WSS更低。下图是kmeans,k=3的聚类情况和WSS值,上半图是原始数据,下半图是用之前一样的方法模拟生成出来的。
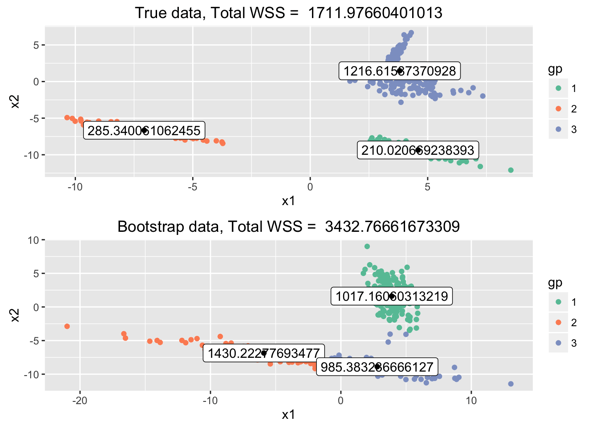
在k=3情况下,我们可以画出100次模拟(100 bootstrap simulations,每次生成一样size的一个集合)的WSS密度函数(有点类似于直方图,但是是连续的,函数和x轴围成的总面积是1,在有效范围内某一个WSS值点之前的总面积是表示小于等于该值的概率,或者比例)。红线是指在真实数据下总体类内误差。
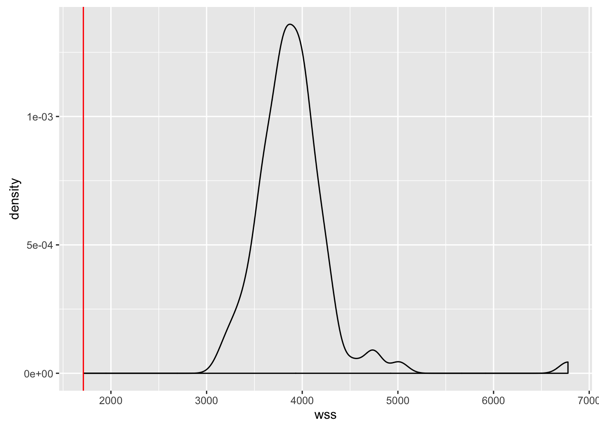
(这里稍稍延生一下,关于画这样的密度图,在R语言工具包里面有很简单的指令,见http://www.plob.org/2014/05/11/7264.html,ggplot()+geom_density(),这个网页上写的非常清楚,如果用R的同学可以参考,虽然我没用过R,=.=)
前面已经说过了,一般来说,相比k类,k+1类时kmeans得到更紧凑的聚类,使得Total WSS值降低。所以我们设计这样的策略,只要k+1类的真实数据kmeans聚类计算的Total WSS,至少比k类的模拟点(bootstrap simulations)下的Total WSS的95%要小,那么我们就接受k+1类;后面依次增加k,直到不满足小于等于的条件。下面就是在我们数据集下的每一步结果:
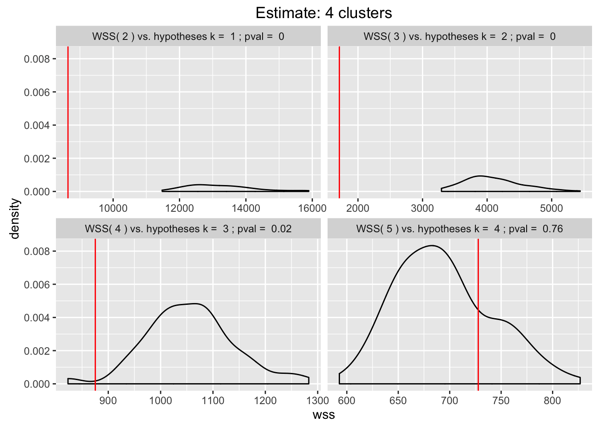
红线是k+1在真实数据下计算得到,密度分布曲线是k类模拟点数据的WSS密度分布,我们看到当K+1=5的时候就不满足我们的条件了,因此k=4是最好的,和真实也是相符的。
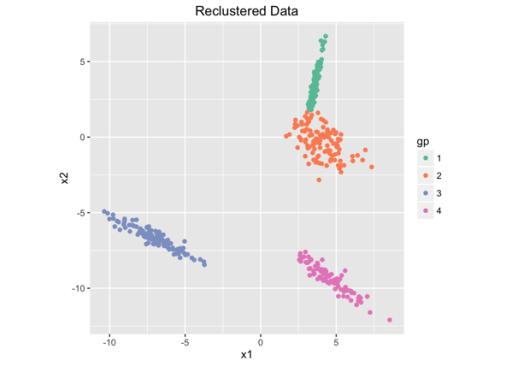
到这里就可以选择出相对合理的k值了,当然,在复杂数据下的有效性还需要验证,不过我觉得还是有一定道理的。唯一的问题是95%是人为设定的,希望可以有更合理的解释。我理解为假设检验下,显著度p=0.05的情况。
重抽样Bootstrapping方法
Bootstrapping(Bootstrap)是统计里面的方法概念[3],也是本文第二个想特别讲一讲的东西。
In statistics, bootstrapping can refer to any test or metric that relies on random sampling with replacement.
如果我们要estimate一个集合的某个统计特征,如mean,用最基本的bootstrap方法,就是从一个已知的N大小的原始数据集(称为sample)中”有放回的随机抽取样本”,直至有同样size。这个抽取得到的集合称为一个bootstrap sample,或者resample。当N足够大的时候,基本上就不能得到和原来数据完全一样的resample了。这样的重抽取过程被重复很多次,比如1000次或者更多的10000次,每一次我们可以计算resample的mean(其他统计特征都是一样的),于是我们可以得到mean的histogram,就可以看到mean的变化和分布形状。
Bootstrap另外还有很多变化,其中Parametric bootstrap和smooth bootstrap比较常见。
- Parametric bootstrap:用于比较小的sample size;不是从原始集合抽样本,而是fit一个特定的model,比如我们上面kmeans的例子,我们认为每一个类都是由一个高斯分布产生的,那么我们就求出mean和variance来fit高斯分布model。然后resample的样本是 drawn from this fitted model,并且一样的size。这样的过程可以重复很多次,得到很多simulations。
- smooth bootstrap:其他情况下smooth bootstrap方法可能更好。A convolution-method of regularization reduces the discreteness of the bootstrap distribution, by adding a small amount of N(0,σ2) random noise to each bootstrap sample. A conventional choice is σ=1/n−−√ for sample size n。在基本的Bootstrap方法上加上一个随机噪音,使得分布更平滑。有些统计特征,比如一个集合的median,往往只有比较少的几个值,这样分布看起来就比较稀疏了。下面是一个例子,展示了Histograms of the bootstrap distribution and the smooth bootstrap distribution。
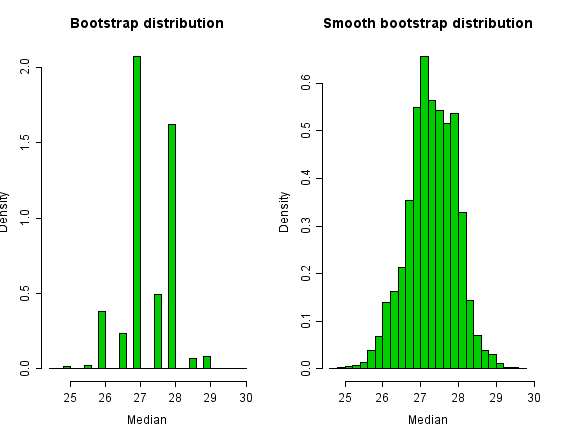
好,差不多讲完了今天的内容。本篇介绍了聚类如何选择K的一种方法(实际上,除了kmeans以外,还可以用于很多其他的聚类方法,如果他们也要确定k。)。该方法使用的Parametric bootstrap来抽样,是统计中bootstrap方法的一种类型。我们还介绍了基本的bootstrap方法,有放回的抽取,以及更平滑的smooth bootstrap方法,这些算法都是简单而有道理,我喜欢简单的算法。希望看完了的朋友喜欢就顶一下哈。
参考资料
[1] http://baike.baidu.com/view/3066906.htm
[2] http://www.win-vector.com/blog/2016/02/finding-the-k-in-k-means-by-parametric-bootstrap/
[3] https://en.wikipedia.org/wiki/Bootstrapping_(statistics)