

前言
在前面的一系列WGS文章中,我讲述了很多基因数据分析的来龙去脉,虽然许多同学觉得很有帮助,但是却缺了一个重要的环节——没有提供实际可用的数据来实战完成具体的流程,不能得到直观的体会。许多读者也纷纷在后台留言反馈这个问题,特别是在我写了如何入门生物信息学的文章之后情况尤甚。所以我决定要再写一篇文章来解决这个问题,但碰巧今年年末事情稍多,在写作的过程中也曾多次中断,直至今天才完成,各位久等了。本次文章分为上下两篇,这是第一篇,都是WGS第四节的延伸,本意是结合具体的数据,让更多的人能够 更好地理解整个WGS数据的分析和处理过程,我也结合自身的工作经验给出一些做项目过程中的建议,以作参考,希望能够对你有更多的帮助。另外,接下来我将系统写一个关于全基因组关联分析(GWAS)的文章,同时还会有更多全面而且紧扣前沿的技术文章分享出来。
那么,事不宜迟我们马上开始。考虑到实际的数据分析环境,我们只在Linux命令行终端(Terminal)中进行,执行步骤都写在shell,因此不会有窗口式的操作(使用Mac OS的同学可以使用Mac自带的Terminal,与Linux操作一致),在这篇文章中我们会用到以下几个工具。
- sratoolkit
- bgzip
- tabix
- bwa
- samtools
- GATK 4.0
这些软件都可以在github上找到(包括GATK),需要各位自行安装。这里补充一句,目前GATK4.0的正式版本已经发布,它的使用方式与之前相比有着一些差异(变得更加简单,功能也更加丰富了),增加了结构性变异检测和很多Spark、Cloud-Only的功能,并集成了Mutect2和picard的所有功能(以及其他很多有用的工具),这为我们减少了许多额外的工具,更加有利于流程的构建和维护,4.0之后的GATK是一个新的篇章,大家最好是掌握这一个版本!另外,3.x的版本貌似也已经不提供下载通道了,如果你还想使用3.x的话可以在公众号后台回复“GATK3”,我为你准备了一个GATK官方3.7的版本。我们这里则使用最新的4.0版本。
项目目录结构
清晰的目录结构是管理众多项目的有效途径,经久不忘,随时可查。虽然看起来有些原始,但在Linux终端下面,我目前还没有发现更好的文件管理办法。这个项目的目录结构,我的建议是按照时间+项目的规则来命名,下面是我的目录结构:
- ./201802_wgs_practice/
- ├── bin
- ├── input
- └── output
顶层的项目名就是20180203_wgs_practice,下面有三个主目录:
- input:存储所有输入数据
- output:存储所有输出数据
- bin:存放所有执行程序和代码
output只存放结果数据,它是由input和bin中的数据和程序流程生成的。这样做的好处是层次分明,流程逻辑清楚,数据互不干扰。
使用E.coli K12完成比对和变异检测
人类基因组数据很大,参考序列长度是3Gb。而一个人的高深度测序数据往往是这个数字的30倍——100Gb。如果直接用这样的数据来完成本文的分析,那么许多同学需要下载大量的原始数据。除了下载时间很长之外,如果没有合适的集群,只是在自己的桌面电脑上干这样的事情,那么硬盘空间也将很快不够用。而且,要在单机电脑上完成这样一个高深度WGS数据的分析,处理对机器性能有要求之后,跑起来也需要连续花上差不多140个小时——相信大家都等不起呀。
因此,为了解决这个问题,我找了E.coli K12(一种实验用的大肠杆菌)的数据作为代替,用来演示 数据比对和变异检测这两个最消耗计算资源和存储空间的步骤。E.coli K12的特点是数据很小,它的基因组长度只有4.6Mb,很适合大家用来快速学习WGS的数据分析,遇到人类的数据时,再做替换就行了。
下载E.coli K12的参考基因组序列
熟悉的同学应该第一时间能够知道,这些物种的基因组参考序列都可以在NCBI上获取,我们这里也是一样,可以在NCBI网站上直接搜索这个序列,为了简化步骤,我直接给出E.coli K12参考序列的ftp地址给大家下载之用:
- ftp://ftp.ncbi.nlm.nih.gov/genomes/all/GCF/000/005/845/GCF_000005845.2_ASM584v2/GCF_000005845.2_ASM584v2_genomic.fna.gz
你可以在Linux(或者Mac OSX)命令行上直接使用wget,将这个fasta下载下来,由于它很小,所以几秒之后我们就可以得到这个fasta序列。
- $ wget ftp://ftp.ncbi.nlm.nih.gov/genomes/all/GCF/000/005/845/GCF_000005845.2_ASM584v2/GCF_000005845.2_ASM584v2_genomic.fna.gz
为了接下来表达上的清晰和操作上的方便,我们使用bgzip将这个序列文件进行解压并把名字重命名为E.coli_K12_MG1655.fa,这样就一目了然了。
- $ gzip -dc GCF_000005845.2_ASM584v2_genomic.fna.gz > E.coli_K12_MG1655.fa
E.coli K12只有一条完整的染色体,你打开文件后将会看到和我一样的内容:
- >NC_000913.3 Escherichia coli str. K-12 substr. MG1655, complete genome
- AGCTTTTCATTCTGACTGCAACGGGCAATATGTCTCTGTGTGGATTAAAAAAAGAGTGTCTGATAGCAGCTTCTGAACTG
- GTTACCTGCCGTGAGTAAATTAAAATTTTATTGACTTAGGTCACTAAATACTTTAACCAATATAGGCATAGCGCACAGAC
接着,我们用samtools为它创建一个索引,这是为方便其他数据分析工具(比如GATK)能够快速地获取fasta上的任何序列做准备。
- $ /Tools/common/bin/samtools faidx E.coli_K12_MG1655.fa
这时会生成一份E.coli_K12_MG1655.fa.fai文件。除了方便其他工具之外,我们可以通过这样的索引来获取fasta文件中任意位置的序列或者任意完整的染色体序列。可以很方便地完成对参考序列(或者任意fasta文件)特定区域序列的提取。举个例子:
- $ samtools faidx E.coli_K12_MG1655.fa NC_000913.3:1000000-1000200
我们就获得了E.coli K12参考序列上的这一段序列:
- >NC_000913.3:1000000-1000200
- GTGTCAGCTTTCGTGGTGTGCAGCTGGCGTCAGATGACAACATGCTGCCAGACAGCCTGA
- AAGGGTTTGCGCCTGTGGTGCGTGGTATCGCCAAAAGCAATGCCCAGATAACGATTAAGC
- AAAATGGTTACACCATTTACCAAACTTATGTATCGCCTGGTGCTTTTGAAATTAGTGATC
- TCTATTCCACGTCGTCGAGCG
这个小技巧在特定的时候非常实用。
下载E.coli K12的测序数据
基因组参考序列准备好之后,接下来我们需要下载它的测序数据。E.coli K12作为一种供研究使用的模式生物,自然已经有许多的测序数据在NCBI上了,在这里我们选择了其中的1个数据——SRR1770413。这个数据来自Illumina MiSeq测序平台(不用担心平台的事情),read长度是300bp,测序类型Pair-End(没了解过PE read同学可以参考我前面WGS系列的第四节文章)。你可以在NCBI上直接搜到:这里
在NCBI给出的信息页面中,我们可以清楚地看到这个数据的大小(如下图)——差不多200MB,一般家庭网速也能够较快下载完成。
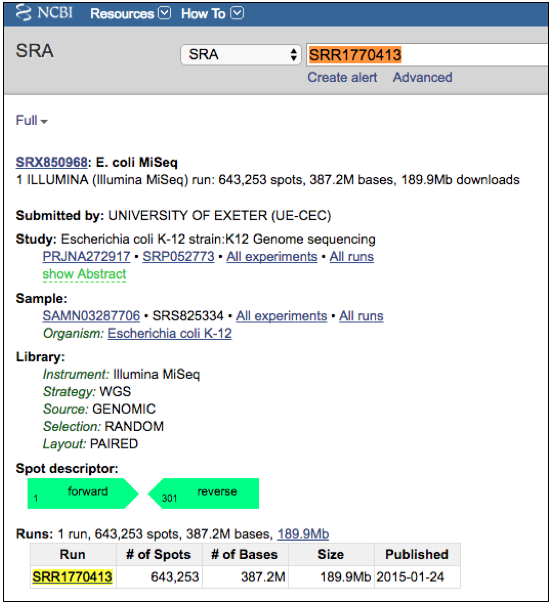
从NCBI上下载下来的测序数据,不是我们熟悉的fastq格式,而是SRA(一种NCBI自己设计的测序数据存储格式,具较高的压缩率),我们需要对其进行转换,下文详述。现在我们先下载,有两个下载方式(我在这里告诉大家的方法同样适用于其他类型的数据),第一个是如上面所说搜索到SRR1770413这个数据的ftq地址,然后直接在命令行中执行wget进行下载,如下:
- $ wget ftp://ftp-trace.ncbi.nlm.nih.gov/sra/sra-instant/reads/ByRun/sra/SRR/SRR177/SRR1770413/SRR1770413.sra
注意,下载下来的这个SRA文件虽然只有一份,但是里面其实存了read1和read2的测序数据,我们要把它解出来,转换成为我们所需的fastq格式。这个时候,我们就需要用到NCBI的官方工具包sratoolkit,大家下载对应系统的版本,直接解压之后就可以使用了。
sratoolkit是一个工具包,所有的执行程序都在它解压后的bin文件夹下,我们要把SRA转换为fastq,只需直接通过工具包中的fastq-dump即可完成。
- $ /Tools/sratoolkit/2.8.2/bin/fastq-dump --split-files SRR1770413.sra
然后我们就会得到这个E.coli K12数据的read1和read2了:
- SRR1770413_1.fastq
- SRR1770413_2.fastq
另一个数据下载的方法就是用上面说到的sratoolkit,我也比较推荐这个方法,操作很简单。同样是使用fastq-dump(没错,与上面一样,区别在于下载的时候,输入的是数据的SRA编号),它可以在我们下载的过程中就直接将SRA转换为两个fastq。
- $ /Tools/sratoolkit/2.8.2/bin/fastq-dump --split-files SRR1770413
下载完成后,我们最好用bgzip(不推荐gzip)将其压缩为.gz文件,这样可以节省空间,而且也不会对接下来的数据分析产生影响。
- $ /Tools/common/bin/bgzip -f SRR1770413_1.fastq
- $ /Tools/common/bin/bgzip -f SRR1770413_1.fastq
至此,E.coli K12相关的数据我们就都准备好了,先看一眼我现在的目录结构。
- ./201802_wgs_practice/
- ├── bin
- ├── input
- │ ├── E.coli
- │ ├── fasta
- │ │ ├── E.coli_K12_MG1655.fa
- │ │ ├── E.coli_K12_MG1655.fa.fai
- │ │ └── work.log.sh
- │ └── fastq
- │ ├── SRR1770413_1.fastq.gz
- │ ├── SRR1770413_2.fastq.gz
- │ └── work.log.sh
- ├── output
- └── work.log.sh
其中各个目录下的 work.log.sh记录了我在该目录下的所有重要操作——这是我的个人习惯,目的是方便以后反查数据的需要。
数据准备完毕之后,接下来就可以进行具体的分析了。
质控
质控是必须做的,我们需要完整认识原始的测序数据质量到底如何,该步骤不能省略。我专门为此单独写了一篇文章(WGS系列第三节),在正式的数据分析过程中,大家可以参考它来完成数据的质控,然后再进行接下来的分析。本篇文章为了控制篇幅和尽可能扣住核心内容,就不再对此深入展开。
比对
首先是比对。所谓比对就是把测序数据定位到参考基因组上,确定每一个read在基因组中的位置。这里,我们依然用目前使用最广的BWA来完成这个工作。在正式比对之前,需要先为参考序列构建BWA比对所需的FM-index(比对索引)。
- $ /Tools/common/bin/bwa index E.coli_K12_MG1655.fa
由于这个序列很短,只需几秒就可以完成这个索引文件的构建(对于人类基因组则需要3个小时的时间)。创建完毕之后,将多出5份以E.coli_K12_MG1655.fa为前缀的序列索引文件。
- E.coli_K12_MG1655.fa.amb
- E.coli_K12_MG1655.fa.ann
- E.coli_K12_MG1655.fa.bwt
- E.coli_K12_MG1655.fa.pac
- E.coli_K12_MG1655.fa.sa
现在我们使用bwa完成比对,用samtools完成BAM格式转换、排序并标记PCR重复序列。步骤分解如下:
- #1 比对
- time /Tools/common/bin/bwa mem -t 4 -R '@RG\tID:foo\tPL:illumina\tSM:E.coli_K12' /Project/201802_wgs_practice/input/E.coli/fasta/E.coli_K12_MG1655.fa /Project/201802_wgs_practice/input/E.coli/fastq/SRR1770413_1.fastq.gz /Project/201802_wgs_practice/input/E.coli/fastq/SRR1770413_2.fastq.gz | /Tools/common/bin/samtools view -Sb - > /Project/201802_wgs_practice/output/E.coli/E_coli_K12.bam && echo "** bwa mapping done **"
- #2 排序
- time /Tools/common/bin/samtools sort -@ 4 -m 4G -O bam -o /Project/201802_wgs_practice/output/E.coli/E_coli_K12.sorted.bam /Project/201802_wgs_practice/output/E.coli/E_coli_K12.bam && echo "** BAM sort done"
- rm -f /Project/201802_wgs_practice/output/E.coli/E_coli_K12.bam
- #3 标记PCR重复
- time /Tools/common/bin/gatk/4.0.1.2/gatk MarkDuplicates -I /Project/201802_wgs_practice/output/E.coli/E_coli_K12.sorted.bam -O /Project/201802_wgs_practice/output/E.coli/E_coli_K12.sorted.markdup.bam -M /Project/201802_wgs_practice/output/E.coli/E_coli_K12.sorted.markdup_metrics.txt && echo "** markdup done **"
- #4 删除不必要文件(可选)
- rm -f /Project/201802_wgs_practice/output/E.coli/E_coli_K12.bam
- rm -f /Project/201802_wgs_practice/output/E.coli/E_coli_K12.sorted.bam
- #5 创建比对索引文件
- time /Tools/common/bin/samtools index /Project/201802_wgs_practice/output/E.coli/E_coli_K12.sorted.markdup.bam && echo "** index done **"
从上面的命令大家也可以看到,我严格按照上文提到的项目目录规范来执行(步骤中涉及到的数据路径也都尽可能使用全路径),这个比对的shell存放在bin目录下,名称是bwa_and_markdup.sh,从名称也能够一眼可以看出是要做什么的。
简单解释一下这个shell所做的事情:首先利用bwa mem比对模块将E.coli K12质控后的测序数据定位到其参考基因组上(我们这里设置了4个线程来完成比对,根据电脑性能可以适当调大),同时通过管道(’|’ 操作符)将比对数据流引到samtools转换为BAM格式(SAM的二进制压缩格式),然后重定向(‘>’操作符)输出到文件中保存下来。
-R 设置Read Group信息,虽然我在以前的文章中已经反复强调过它的重要性,但这里还是再说一次,它是read数据的组别标识,并且其中的ID,PL和SM信息在正式的项目中是不能缺少的(如果样本包含多个测序文库的话,LB信息也不要省略),另外由于考虑到与GATK的兼容关系,PL(测序平台)信息不能随意指定,必须是:ILLUMINA,SLX,SOLEXA,SOLID,454,LS454,COMPLETE,PACBIO,IONTORRENT,CAPILLARY,HELICOS或UNKNOWN这12个中的一个。
接着用samtools对原始的比对结果按照参考序列位置从小到大进行排序(同样是4个线程),只有这个步骤完成之后才可以继续往下。
然后,我们使用GATK标记出排完序的数据中的PCR重复序列。这个步骤完成后,如无特殊需要,我们就可以直接删除前面那两个BAM文件了(原始比对结果和排序后的结果)——后续几乎不会再用到那两份文件了。关于标记PCR重复序列的操作比较简单,不再细说(如果希望了解更多有关重复序列特征的信息可以回看WGS系列第四节中的内容)。
最后,我们再用samtools为E_coli_K12.sorted.markdup.bam创建索引。我认为不论是否有后续分析,为BAM文件创建索引应该作为一个常规步骤,它可以让我们快速地访问基因组上任意位置的比对情况,这一点非常有助于我们随时了解数据。
至于每个步骤最前面的time,则是用于记录执行时间的,有助于我们清楚地知道每一个分析过程都花了多少时间,当需要优化流程的时候这个信息会很有用。
变异检测
接下来是用GATK完成变异检测。但在开始之前之前我们还需要先为E.coli K12的参考序列生成一个.dict文件,这可以通过调用CreateSequenceDictonary模块来完成(这是原来picard的功能)。
- $ /Tools/common/bin/gatk/4.0.1.2/gatk CreateSequenceDictionary -R E.coli_K12_MG1655.fa -O E.coli_K12_MG1655.dict && echo "** dict done **"
唯一需要注意的是.dict文件的名字前缀需要和fasta的一样,并跟它在同一个路径下,这样GATK才能够找到。
OK,现在我们就可以进行变异检测了,同样使用GATK 4.0的HaplotypeCaller模块来完成。由于我们只有一个样本,要完成这个工作其实很简单,直接输入比对文件和参考序列就行了,但是考虑到实际的情况,我想告诉大家一个更好的方式(虽然这会多花些时间),就是:先为每个样本生成一个GVCF,然后再用GenotypeGVCFs对这些GVCF进行joint calling,如下 ,我把命令都写在gatk.sh中,并执行。
- #1 生成中间文件gvcf
- time /Tools/common/bin/gatk/4.0.1.2/gatk HaplotypeCaller \
- -R /Project/201802_wgs_practice/input/E.coli/fasta/E.coli_K12_MG1655.fa \
- --emit-ref-confidence GVCF \
- -I /Project/201802_wgs_practice/output/E.coli/E_coli_K12.sorted.markdup.bam \
- -O /Project/201802_wgs_practice/output/E.coli/E_coli_K12.g.vcf && echo "** gvcf done **"
- #2 通过gvcf检测变异
- time /Tools/common/bin/gatk/4.0.1.2/gatk GenotypeGVCFs \
- -R /Project/201802_wgs_practice/input/E.coli/fasta/E.coli_K12_MG1655.fa \
- -V /Project/201802_wgs_practice/output/E.coli/E_coli_K12.g.vcf \
- -O /Project/201802_wgs_practice/output/E.coli/E_coli_K12.vcf && echo "** vcf done **"
很快我们就获得了E.coli K12这个样本初步的变异结果——E_coli_K12.vcf。之所以非要分成两个步骤,是因为我想借此告诉大家,变异检测不是一个样本的事情,有越多的同类样本放在一起joint calling结果将会越准确,而如果样本足够多的话,在低测序深度的情况下也同样可以获得完整并且准确的结果,而这样的分步方式是应对多样本的好方法。
最后,我们用bgzip对这个VCF进行压缩,并用tabix为它构建索引,方便以后的分析。
- #1 压缩
- time /Tools/common/bin/bgzip -f /Project/201802_wgs_practice/output/E.coli/E_coli_K12.vcf
- #2 构建tabix索引
- time /Tools/common/bin/tabix -p vcf /Project/201802_wgs_practice/output/E.coli/E_coli_K12.vcf.gz
bgzip压缩完成之后,原来的VCF文件会被自动删除。
为了保持一致,现在再看一下完成到这里之后我们的目录长什么样了,供大家对照。
- ./201802_wgs_practice/
- ├── bin
- │ ├── bwa_and_markdup.sh
- │ └── gatk.sh
- ├── input
- │ └── E.coli
- │ ├── fasta
- │ │ ├── E.coli_K12_MG1655.dict
- │ │ ├── E.coli_K12_MG1655.fa
- │ │ ├── E.coli_K12_MG1655.fa.amb
- │ │ ├── E.coli_K12_MG1655.fa.ann
- │ │ ├── E.coli_K12_MG1655.fa.bwt
- │ │ ├── E.coli_K12_MG1655.fa.fai
- │ │ ├── E.coli_K12_MG1655.fa.pac
- │ │ ├── E.coli_K12_MG1655.fa.sa
- │ │ └── work.log.sh
- │ └── fastq
- │ ├── SRR1770413_1.fastq.gz
- │ ├── SRR1770413_2.fastq.gz
- │ └── work.log.sh
- ├── output
- │ └── E.coli
- │ ├── E_coli_K12.g.vcf
- │ ├── E_coli_K12.g.vcf.idx
- │ ├── E_coli_K12.sorted.markdup.bam
- │ ├── E_coli_K12.sorted.markdup.bam.bai
- │ ├── E_coli_K12.sorted.markdup_metrics.txt
- │ ├── E_coli_K12.vcf
- │ └── E_coli_K12.vcf.idx
- └── work.log.sh
如果大家仔细看过WGS系列第四节的话,会发现我这里缺少了两个步骤:重比对和BQSR。没有执行BQSR是因为E.coli K12没有那些必须的known变异集(或者有但我没找到),所以无法进行;但没有重比对,则是因为我在GATK 4.0中没发现IndelRealigner这个功能,虽然我们使用GATK HaplotypeCaller或者Mutect2的话确实可以省略这个步骤,但如果是其他软件来进行变异检测那么该步骤依然十分重要,我目前不太清楚为何GATK 4.0没有将这个功能单独分离出来。
后面要谈到的就是变异的质控了。很遗憾我们这个E.coli K12的变异结果并不适合通过VQSR来进行过滤,原因上面也提到了一些,它不像人类的基因组数据,有着一套适合用来训练过滤模型的已知变异集(dbSNP,1000G,Hapmap和omini等)。其实这种情况有时候我们在工作中也会碰到,比如有些捕获测序(Panel测序数据,甚至外显子测序)的数据,由于它的区域较小,获得的变异也不多,导致最终没法满足VQSR进行模型训练时所需的最低变异数要求,那时你也不能通过这个方式协助变异质控。那么碰到这种情况的时候该怎么办?我将这部分的内容放在了下一篇文章中,在那里我们再来讨论这个问题。我也会告诉大家变异质控的基本逻辑,而不是简单罗列一个命令,同时也会再用NA12878这个人的数据来进一步告诉大家如何比较和评估变异结果。
小结
至此,这个篇文章的上半部分就到此为止了。除了那些重要的内容之外,在上文中,你会看到我反复提到了创建“索引”这个事情,比如为fasta,为BAM,为VCF。我为什么非要反复强调这个事情不可呢?因为我发现许多初学者并不知道索引的作用,当被问到如何从巨大的比对文件或者变异文件中提取某个信息时,总是要走弯路——努力写程序去提取,既慢又费力,结果还不一定好,甚至有些有一定经验的同学也不知道使用bgzip和tabix的好处,因此我才反复在文章里提及。
1F
请问转载了我大量的文章,不需要经过我同意的吗?另外在文章开头注明了我的链接和出处了吗?
B1
@ 请输入您的QQ号 请问您将这些文章发在哪里了,我读过之后觉得非常收益,想多了解一些,可惜没有注明出处。
B2
@ Zhiyong hi,你可以关注我的公众号:解螺旋的矿工,我的文章都是在这个公众号上首发的~
2F
之前看到的这篇文章,内容很清晰,现在再看有个建议,可以把各个路径设成一个变量,下面用的时候直接$ 就可以了。
B1
@ Zhiyong 😆是的,我后来在公众号中专门更新了一个综合的流程,你可以了解一下~
3F
赞
来自外部的引用