


大数据文摘作品
编译:寒小阳、蒋宝尚、Sheila、赖小娟、钱天培
假设你有一个包含数百个特征(变量)的数据集,却对数据所属的领域几乎没有什么了解。 你需要去识别数据中的隐藏模式,探索和分析数据集。不仅如此,你还必须找出数据中是否存在模式--用以判定数据是有用信号还是噪音?
这是否让你感到不知所措?当我第一次遇到这种情况,我简直全身发麻。想知道如何挖掘一个多维数据集? 这是许多数据科学家经常问的问题之一。 该篇文章中,我将带你通过一个强有力的方式来实现这一点。用PCA怎么样?
现在,一定会有很多人心里想着“我会使用PCA来降维和可视化”。 好吧,你是对的!PCA绝对是具有大量特征的数据集的降维和可视化的不错选择。 但是,假如你能使用比PCA更先进的东西将会怎样呢?
如果你可以很容易地找出非线性的模式呢? 在本文中,我将告诉你一个比PCA(1933)更有效、被称为t-SNE(2008)的新算法。 首先我会介绍t-SNE算法的基础知识,然后说明为什么t-SNE是非常适合的降维算法。
你还将获得在R代码和Python语句中使用t-SNE的实践知识。
来吧来吧!
目录
1.什么是t-SNE?
2.什么是降维?
3.t-SNE与其他降维算法
4.t-SNE的算法细节
4.1 算法
4.2 时间和空间复杂性
5.t-SNE实际上做什么?
6.用例
7.t-SNE与其他降维算法相比
8.案例实践
8.1 使用R代码
-超参数调试
-代码
-执行时间
-结果解读
8.2 使用python语句
-超参数调试
-代码
-执行时间
9.何时何地去使用
9.1 数据科学家
9.2 机器学习竞赛爱好者
9.3 数据科学爱好者
10.常见误区
1.什么是t-SNE

(t-SNE)t-分布式随机邻域嵌入是一种用于挖掘高维数据的非线性降维算法。 它将多维数据映射到适合于人类观察的两个或多个维度。 在t-SNE算法的帮助下,你下一次使用高维数据时,可能就不需要绘制很多探索性数据分析图了。
2.什么是降维?
为了理解t-SNE如何工作,让我们先了解什么是降维?
简而言之,降维是在2维或3维中展现多维数据(具有多个特征的数据,且彼此具有相关性)的技术。
有些人可能会问,当我们可以使用散点图、直方图和盒图绘制数据,并用描述性统计搞清数据模式的时候为什么还需要降低维度。
好吧,即使你可以理解数据中的模式并将其呈现在简单的图表上,但是对于没有统计背景的人来说,仍然很难理解它。 此外,如果你有数百个特征值,你必须研究数千张图表,然后才能搞懂这些数据。
在降维算法的帮助下,您将能够清晰地表达数据。
3. t-SNE与其他降维算法
现在你已经了解什么是降维,让我们看看我们如何使用t-SNE算法来降维。
以下是几个你可以查找到的降维算法:
1.主成分分析(线性)
2.t-SNE(非参数/非线性)
3.萨蒙映射(非线性)
4.等距映射(非线性)
5.局部线性嵌入(非线性)
6.规范相关分析(非线性)
7.SNE(非线性)
8.最小方差无偏估计(非线性)
9.拉普拉斯特征图(非线性)
好消息是,你只需要学习上述算法中的其中两种,就可以有效地在较低维度上使数据可视化 - PCA和t-SNE。
PCA的局限性
PCA是一种线性算法。 它不能解释特征之间的复杂多项式关系。 另一方面,t-SNE是基于在邻域图上随机游走的概率分布,可以在数据中找到其结构关系。
线性降维算法的一个主要问题是它们集中将不相似的数据点放置在较低维度区域时,数据点相距甚远。 但是为了在低维、非线性流型上表示高维数据,我们也需要把相似的数据点靠近在一起展示,这并不是线性降维算法所能做的。
现在,你对PCA应该有了一个简短的了解。
局部方法寻求将流型上的附近点映射到低维表示中的附近点。 另一方面,全局方法试图保留所有尺度的几何形状,即将附近的点映射到附近的点,将远处的点映射到远处的点
要知道,除t-SNE之外的大多数非线性技术都不能同时保留数据的局部和全局结构。
4. t-SNE的算法细节(选读)
该部分是为有兴趣深入理解算法的人准备的。 如果您不想了解数学上面的细节,可以放心地跳过本节。
4.1算法
步骤1
随机邻近嵌入(SNE)首先通过将数据点之间的高维欧几里得距离转换为表示相似性的条件概率。数据点![]() 与数据点
与数据点![]() 的相似性是条件概率
的相似性是条件概率![]() ——如果邻域被选择与在以
——如果邻域被选择与在以![]() 为中心的正态分布的概率密度成比例,
为中心的正态分布的概率密度成比例,![]() 将选择
将选择![]() 作为其邻域的概率。
作为其邻域的概率。
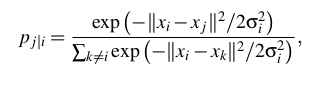
其中![]() 是以数据点
是以数据点![]() 为中心的正态分布的方差,如果你对数学不感兴趣,以这种方式思考它,算法开始于将点之间的最短距离(直线)转换成点的相似度的概率。 其中,点之间的相似性是: 如果在以
为中心的正态分布的方差,如果你对数学不感兴趣,以这种方式思考它,算法开始于将点之间的最短距离(直线)转换成点的相似度的概率。 其中,点之间的相似性是: 如果在以![]() 为中心的高斯(正态分布)下与邻域的概率密度成比例地选取邻域,则
为中心的高斯(正态分布)下与邻域的概率密度成比例地选取邻域,则![]() 会选择
会选择![]() 作为其邻居的条件概率。
作为其邻居的条件概率。
步骤2
对于低维数据点![]() 和
和![]() 的高维对应点
的高维对应点![]() 和
和![]() ,可以计算类似的条件概率,其由
,可以计算类似的条件概率,其由![]() 表示。
表示。
需要注意的是,pi | i和pj | j被设置为零,因为我们只想对成对的相似性进行建模。
简单来说,步骤1和步骤2计算一对点之间的相似性的条件概率。这对点存在于:
1.高维空间中
2.低维空间中
为了简单起见,尝试详细了解这一点。
让我们把3D空间映射到2D空间。 步骤1和步骤2正在做的是计算3D空间中的点的相似性的概率,并计算相应的2D空间中的点的相似性的概率。
逻辑上,条件概率![]() 和
和![]() 必须相等,以便把具有相似性的不同维空间中的数据点进行完美表示。即,
必须相等,以便把具有相似性的不同维空间中的数据点进行完美表示。即,![]() 和
和![]() 之间的差必须为零,以便在高维和低维中完美复制图。
之间的差必须为零,以便在高维和低维中完美复制图。
通过该逻辑,SNE试图使条件概率的这种差异最小化。
步骤3
现在讲讲SNE和t-SNE算法之间的区别。
为了测量条件概率SNE差值的总和的最小化,在全体数据点中使用梯度下降法使所有数据点的Kullback-Leibler散度总和减小到最小。 我们必须知道,K-L散度本质上是不对称的。
换句话说,SNE代价函数重点在映射中保留数据的局部结构(为了高斯方差在高维空间的合理性,![]() )。
)。
除此之外,优化该代价函数是非常困难的(计算效率低)。
因此,t-SNE也尝试最小化条件概率之差的总和值。 但它通过使用对称版本的SNE代价函数,使用简单的梯度。此外,t-SNE在低维空间中采用长尾分布,以减轻拥挤问题(参考下面译者解释)和SNE的优化问题。
*译者注:
拥挤问题是提出t-SNE算法的文章(Visualizing Data using t-SNE,08年发表在Journal of Machine Learning Research,大神Hinton的文章)重点讨论的问题(文章的3.2节)。译者的理解是,如果想象在一个三维的球里面有均匀分布的点,如果把这些点投影到一个二维的圆上一定会有很多点是重合的。所以在二维的圆上想尽可能表达出三维里的点的信息,把由于投影所重合的点用不同的距离(差别很小)表示,这样就会占用原来在那些距离上的点,原来那些点会被赶到更远一点的地方。t分布是长尾的,意味着距离更远的点依然能给出和高斯分布下距离小的点相同的概率值。从而达到高维空间和低维空间对应的点概率相同的目的。
步骤4
如果我们看到计算条件概率的方程,我们忽略了现在的讨论的方差。要选择的剩余参数是学生的t-分布的方差![]() ,其中心在每个高维数据点
,其中心在每个高维数据点![]() 的中心。不可能存在对于数据集中的所有数据点最优的单个值
的中心。不可能存在对于数据集中的所有数据点最优的单个值![]() ,因为数据的密度可能变化。在密集区域中,较小的值
,因为数据的密度可能变化。在密集区域中,较小的值![]() 通常与较稀疏的区域相比更合适。任何特定值
通常与较稀疏的区域相比更合适。任何特定值![]() 在所有其他数据点上诱发概率分布
在所有其他数据点上诱发概率分布![]() 。 这个分布有一个
。 这个分布有一个
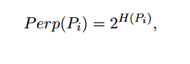
该分布具有随着![]() 增加而增加的熵。 t-SNE对
增加而增加的熵。 t-SNE对![]() 的值执行二进制搜索,产生具有由用户指定具有困惑度的
的值执行二进制搜索,产生具有由用户指定具有困惑度的![]() 2。 该困惑度定义为
2。 该困惑度定义为
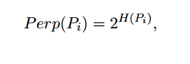
其中H(![]() )是以比特字节测量的香农熵
)是以比特字节测量的香农熵
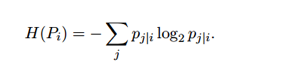
困惑度可以被解释为对邻域的有效数量的平滑测量。 SNE的性能对于茫然性的变化是相当稳固的,并且典型值在5和50之间。
代价函数的最小化是使用梯度下降法来执行的。并且从物理上,梯度可以被解释为由图上定位点![]() 和所有其他图上定位点
和所有其他图上定位点![]() 之间的一组弹簧产生的合力。所有弹簧沿着方向(
之间的一组弹簧产生的合力。所有弹簧沿着方向(![]() -
- ![]() )施加力。弹簧在
)施加力。弹簧在![]() 和
和![]() 定位点之间的排斥或吸引,取决于图中的两点之间的距离是太远还是太近 (太远和太近都不能表示两个高维数据点之间的相似性。)由弹簧在
定位点之间的排斥或吸引,取决于图中的两点之间的距离是太远还是太近 (太远和太近都不能表示两个高维数据点之间的相似性。)由弹簧在![]() 和
和![]() 之间施加的力与其长度成比例,并且还与其刚度成比例,刚度是数据的成对相似性之间的失配(pj | i-qj | i + pi | j-qi | j) 点和地图点 。
之间施加的力与其长度成比例,并且还与其刚度成比例,刚度是数据的成对相似性之间的失配(pj | i-qj | i + pi | j-qi | j) 点和地图点 。
*译者补充:
步骤3和4都在讲述SNE 与t-SNE之间的区别,总结如下:
区别一:将不对称的代价函数改成对称的代价函数。
将代价函数修改为![]() ,其中
,其中![]() ,
,
则可避免上述不对称的代价函数所带来的问题。
区别二:在低维空间中使用学生t-分布而不是高斯分布来计算点与点之间的相似度。
t-SNE在低维空间中采用长尾的学生t-分布,
![]() ,
,
以减轻拥挤问题和SNE的优化问题。
4.2 时间和空间复杂度
现在我们已经了解了算法,是分析其性能的时候了。 正如你可能已经观察到的,该算法计算成对的条件概率,并试图最小化较高和较低维度的概率差的总值。 这涉及大量的运算和计算。 所以该算法对系统资源相当重要。
t-SNE在数据点的数量上具有二次时间和空间复杂性。 这使得它应用于超过10,000个观察对象组成的数据集的时候特别慢和特别消耗资源。
5. t-SNE 实际上做了什么?
了解了 t-SNE 算法的数学描述及其工作原理之后,让我们总结一下前边学过的东西。以下便是t-SNE工作原理的简述。
实际上很简单。 非线性降维算法t-SNE通过基于具有多个特征的数据点的相似性识别观察到的模式来找到数据中的规律。它不是一个聚类算法,而是一个降维算法。这是因为当它把高维数据映射到低维空间时,原数据中的特征值不复存在。所以不能仅基于t-SNE的输出进行任何推断。因此,本质上它主要是一种数据探索和可视化技术。
但是t-SNE可以用于分类器和聚类中,用它来生成其他分类算法的输入特征值。
6. 应用场景
你可能会问, t-SNE有哪些应用场景呢?它几乎可以用于任何高维数据。不过大部分应用集中在图像处理,自然语言处理,基因数据以及语音处理。它还被用于提高心脑扫描图像的分析。以下维几个实例:
6.1 人脸识别
人脸识别技术已经取得巨大进展,很多诸如PCA之类的算法也已经在该领域被研究过。但是由于降维和分类的困难,人脸识别依然具有挑战性。t-SNE被用于高维度数据降维,然后用其它算法,例如 AdaBoostM2, 随机森林, 逻辑回归, 神经网络等多级分类器做表情分类。
一个人脸识别的研究采用了日本女性脸部表情数据库和t-SNE结合AdaBoostM2的方法。其实验结果表明这种新方法效果优于诸如PCA, LDA, LLE及SNE的传统算法。
以下为实现该方法的流程图:

6.2 识别肿瘤亚群(医学成像)
质谱成像(MSI)是一种同时提供组织中数百个生物分子的空间分布的技术。 t-SNE,通过数据的非线性可视化,能够更好地解析生物分子肿瘤内异质性。
以无偏见的方式,t-SNE可以揭示肿瘤亚群,它们与胃癌患者的存活和乳腺癌患者原发性肿瘤的转移状态具有统计相关性。 对每个t-SNE簇进行的存活分析将提供非常有用的结果。[3]
6.3 使用wordvec的文本比较
词向量表示法捕获许多语言属性,如性别,时态,复数甚至语义概念,如“首都城市”。 使用降维,可以计算出使语义相似的词彼此临近的2D地图。 这种技术组合可以用于提供不同文本资料的鸟瞰图,包括文本摘要及其资料源。 这使用户能够像使用地图一样探索文本资料。[4]
7. t-SNE与其它降维算法的对比
下边我们将要比较t-SNE和其它算法的性能。这里的性能是基于算法所达到的准确度,而不是时间及运算资源的消耗与准确度之间的关系。
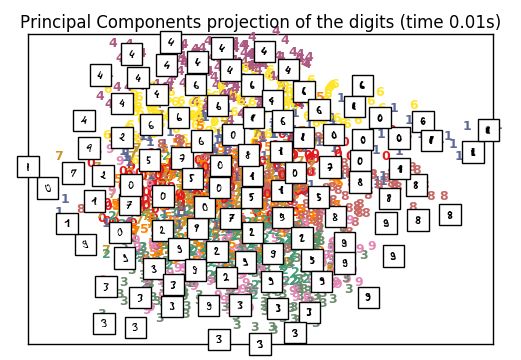
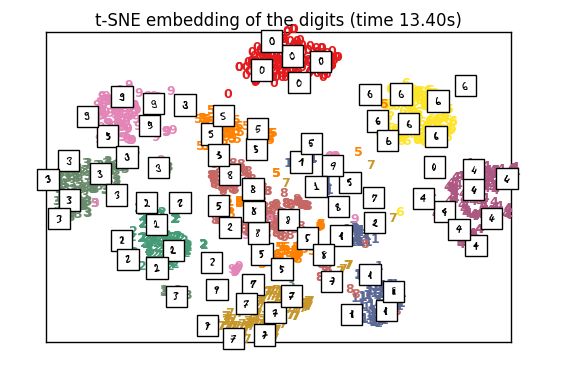
t-SNE产生的结果优于PCA和其它线性降维模型。这是因为诸如经典缩放的线性方法不利于建模曲面的流型。 它专注于保持远离的数据点之间的距离,而不是保留临近数据点之间的距离。
t-SNE在高维空间中采用的高斯核心函数定义了数据的局部和全局结构之间的软边界。对于高斯的标准偏差而言彼此临近的数据点对,对它们的间隔建模的重要性几乎与那些间隔的大小无关。 此外,t-SNE基于数据的局部密度(通过强制每个条件概率分布具有相同的困惑度)分别确定每个数据点的局部邻域大小[1]。 这是因为算法定义了数据的局部和全局结构之间的软边界。 与其他非线性降维算法不同,它的性能优于其它任何一个算法。
8. 案例实践
让我们用MNIST手写数字数据库来实现t-SNE算法。 这是最被广泛探索的图像处理的数据集之一。
81.使用R代码
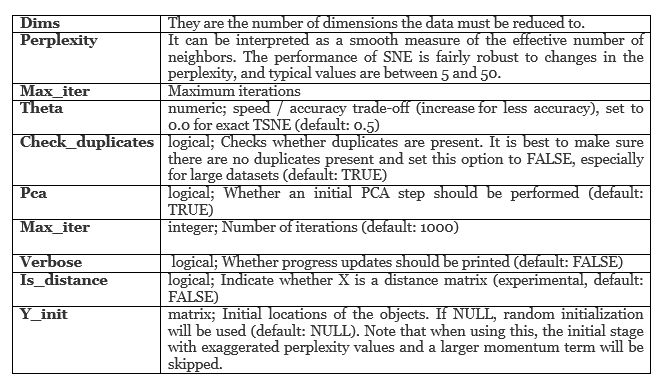
“Rtsne”包具有t-SNE在R语言中的实现。“Rtsne”包可以通过在R控制台中键入以下命令安装:
install.packages(“Rtsne”)
• 超参数调试
• 代码
MNIST数据可从MNIST网站下载,并可用少量代码转换为csv文件。对于此示例,请下载以下经过预处理的MNIST数据。
- ## calling the installed package
- train<- read.csv(file.choose()) ## Choose the train.csv file downloaded from the link above
- library(Rtsne)
- ## Curating the database for analysis with both t-SNE and PCA
- Labels<-train$label
- train$label<-as.factor(train$label)
- ## for plotting
- colors = rainbow(length(unique(train$label)))
- names(colors) = unique(train$label)
- ## Executing the algorithm on curated data
- tsne<- Rtsne(train[,-1], dims = 2, perplexity=30, verbose=TRUE, max_iter = 500)
- exeTimeTsne<- system.time(Rtsne(train[,-1], dims = 2, perplexity=30, verbose=TRUE, max_iter = 500))
- ## Plotting
- plot(tsne$Y, t='n', main="tsne")
- text(tsne$Y, labels=train$label, col=colors[train$label])
• 执行时间
- exeTimeTsne
- user system elapsed
- 118.037 0.000 118.006
- exectutiontimePCA
- user system elapsed
- 11.259 0.012 11.360
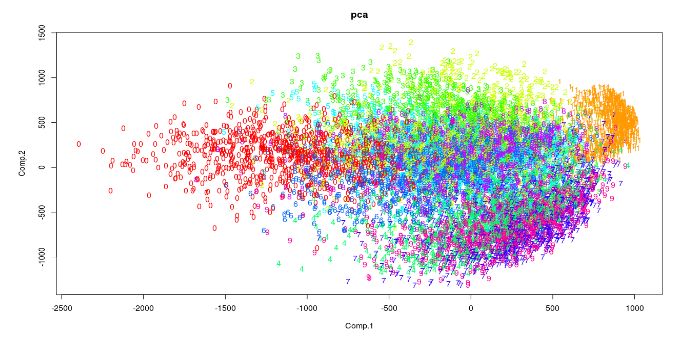
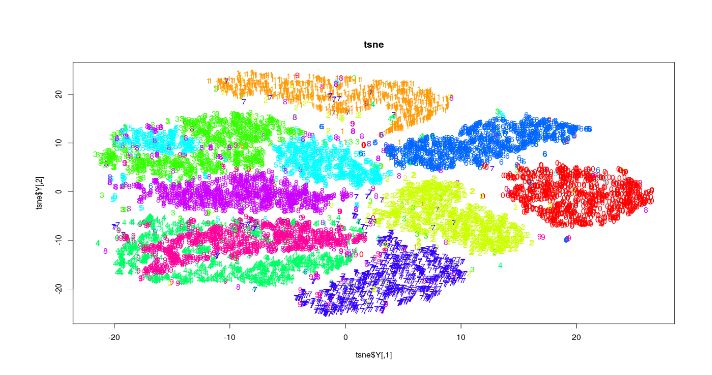
可以看出,运行于相同样本规模的数据,与PCA相比t-SNE所需时间明显更长。
• 解读结果
这些图可用于探索性分析。 输出的x和y坐标以及成本代价值可以用作分类算法中的特征值
8.2使用Rython语句
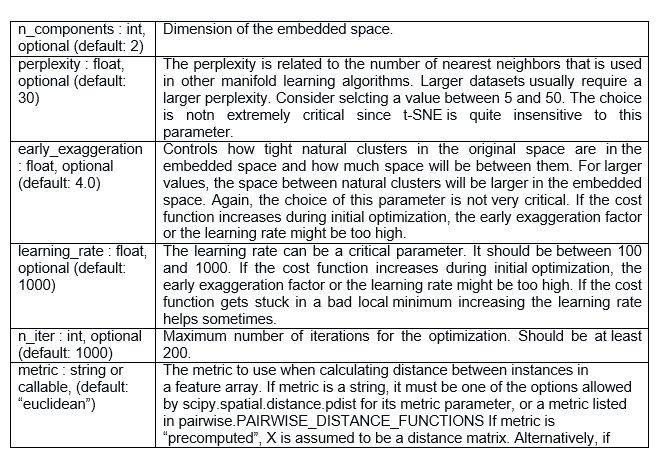
一个重要的事情要注意的是“pip install tsne”会产生错误。 不建议安装“tsne”包。 t-SNE算法可以从sklearn包中访问。
• 超参数调试
•代码
以下代码引自sklearn网站的sklearn示例。
- ## importing the required packages
- from time import time
- import numpy as np
- importmatplotlib.pyplot as plt
- from matplotlib import offsetbox
- from sklearn import (manifold, datasets, decomposition, ensemble,
- discriminant_analysis, random_projection)
- ## Loading and curating the data
- digits = datasets.load_digits(n_class=10)
- X = digits.data
- y = digits.target
- n_samples, n_features = X.shape
- n_neighbors = 30
- ## Function to Scale and visualize the embedding vectors
- defplot_embedding(X, title=None):
- x_min, x_max = np.min(X, 0), np.max(X, 0)
- X = (X - x_min) / (x_max - x_min)
- plt.figure()
- ax = plt.subplot(111)
- fori in range(X.shape[0]):
- plt.text(X[i, 0], X[i, 1], str(digits.target[i]),
- color=plt.cm.Set1(y[i] / 10.),
- fontdict={'weight': 'bold', 'size': 9})
- ifhasattr(offsetbox, 'AnnotationBbox'):
- ## only print thumbnails with matplotlib> 1.0
- shown_images = np.array([[1., 1.]]) # just something big
- fori in range(digits.data.shape[0]):
- dist = np.sum((X[i] - shown_images) ** 2, 1)
- if np.min(dist) < 4e-3:
- ## don't show points that are too close
- continue
- shown_images = np.r_[shown_images, [X[i]]]
- imagebox = offsetbox.AnnotationBbox(
- offsetbox.OffsetImage(digits.images[i], cmap=plt.cm.gray_r),
- X[i])
- ax.add_artist(imagebox)
- plt.xticks([]), plt.yticks([])
- if title is not None:
- plt.title(title)
- #----------------------------------------------------------------------
- ## Plot images of the digits
- n_img_per_row = 20
- img = np.zeros((10 * n_img_per_row, 10 * n_img_per_row))
- for i in range(n_img_per_row):
- ix = 10 * i + 1
- for j in range(n_img_per_row):
- iy = 10 * j + 1
- img[ix:ix + 8, iy:iy + 8] = X[i * n_img_per_row + j].reshape((8, 8))
- plt.imshow(img, cmap=plt.cm.binary)
- plt.xticks([])
- plt.yticks([])
- plt.title('A selection from the 64-dimensional digits dataset')
- ## Computing PCA
- print("Computing PCA projection")
- t0 = time()
- X_pca = decomposition.TruncatedSVD(n_components=2).fit_transform(X)
- plot_embedding(X_pca,
- "Principal Components projection of the digits (time %.2fs)" %
- (time() - t0))
- ## Computing t-SNE
- print("Computing t-SNE embedding")
- tsne = manifold.TSNE(n_components=2, init='pca', random_state=0)
- t0 = time()
- X_tsne = tsne.fit_transform(X)
- plot_embedding(X_tsne,
- "t-SNE embedding of the digits (time %.2fs)" %
- (time() - t0))
- plt.show()
• 执行时长
- Tsne: 13.40 s
- PCA: 0.01 s
PCA结果图(时长0.01s)
t-SNE结果图
9.何时何地使用t-SNE?
9.1 数据科学家
对于数据科学家来说,使用t-SNE的主要问题是算法的黑盒类型性质。这阻碍了基于结果提供推论和洞察的过程。此外,该算法的另一个问题是它不一定在连续运行时永远产生类似的输出。
那么,你怎么能使用这个算法?最好的使用方法是用它进行探索性数据分析。 它会给你非常明确地展示数据内隐藏的模式。它也可以用作其他分类和聚类算法的输入参数。
9.2机器学习竞赛爱好者
将数据集减少到2或3个维度,并使用非线性堆栈器将其堆栈。 使用保留集进行堆叠/混合。 然后你可以使用XGboost提高t-SNE向量以得到更好的结果。
9.3数据科学爱好者
对于才开始接触数据科学的数据科学爱好者来说,这种算法在研究和性能增强方面提供了最好的机会。已经有一些研究论文尝试通过利用线性函数来提高算法的时间复杂度。但是尚未得到理想的解决方案。针对各种实施t-SNE算法解决自然语言处理问题和图像处理应用程序的研究论文是一个尚未开发的领域,并且有足够的空间范围。
10.常见错误
以下是在解释t-SNE的结果时要注意的几个点:
1.为了使算法正确执行,困惑度应小于数据点数。 此外,推荐的困惑度在(5至50)范围内
2.有时,具有相同超参数的多次运行结果可能彼此不同。
3.任何t-SNE图中的簇大小不得用于标准偏差,色散或任何其他诸如此类的度量。这是因为t-SNE扩展更密集的集群,并且使分散的集群收缩到均匀的集群大小。 这是它产生清晰的地块的原因之一。
4.簇之间的距离可以改变,因为全局几何与最佳困惑度密切相关。 在具有许多元素数量不等的簇的数据集中,同一个困惑度不能优化所有簇的距离。
5.模式也可以在随机噪声中找到,因此在决定数据中是否存在模式之前,必须检查具有不同的超参数组的多次运算结果。
6.在不同的困惑度水平可以观察到不同的簇形状。
7.拓扑不能基于单个t-SNE图来分析,在进行任何评估之前必须观察多个图。
参考资料
[1] L.J.P. van der Maaten and G.E. Hinton. Visualizing High-Dimensional Data Using t-SNE. Journal of Machine Learning Research 9(Nov):2579-2605, 2008
[2] Jizheng Yi et.al. Facial expression recognition Based on t-SNE and AdaBoostM2.
IEEE International Conference on Green Computing and Communications and IEEE Internet of Things and IEEE Cyber,Physical and Social Computing (2013)
[3] Walid M. Abdelmoulaa et.al. Data-driven identification of prognostic tumor subpopulations using spatially mapped t-SNE of mass spectrometry imaging data.
12244–12249 | PNAS | October 25, 2016 | vol. 113 | no. 43
[4] Hendrik Heuer. Text comparison using word vector representations and dimensionality reduction. 8th EUR. CONF. ON PYTHON IN SCIENCE (EUROSCIPY 2015)
结束语:
看完这篇文章,相信你一定很想去进一步探索t-SNE算法并使用它。如果你有使用t-SNE算法的经验,欢迎给我们留言分享~
原文链接:
https://www.analyticsvidhya.com/blog/2017/01/t-sne-implementation-r-python/