

生存分析是医学领域常见的分析方法,也可以拓展到其他专业领域。这篇帖子的目的就是介绍怎么做生存分析,希望能对临床医学的同学提供一定帮助。
简明扼要地讲,生存分析的目的无外乎六个字:描述、比较、关系。
1.描述:是指对研究群体生存时间的分布情况进行描述、刻画。类似的,描述特定人群的身高状况时,需要采用均数和标准差来分别衡量数据分布的集中程度和离散程度,在做生存分析时,描述生存时间的分布情况也是十分有必要的和有意义的。但是生存时间的数据资料和身高、体重等常规数据资料不一样,因为含有“截尾”数据,所以就需要变换思路来描述这类数据,经典的也是被大家所接受的解决方法就是生存曲线了。而绘制生存曲线的方法有两种,即K-M法和寿命表法,分别对应不同的数据源。很多软件(如SAS、SPSS)都可以绘制生存曲线,这个过程还是比较简单的,我会在后面介绍如何使用SAS绘制生存曲线。
2.比较:是指比较不同组别之间生存分布的差异。大多数情况下,研究的兴趣点在于比较两组或者多组之间的差别,比如使用A药和B药时,病人的生存时间是否有差异,从而判断A药与B药哪个疗效好。你可以类比样本均数的比较,比如研究学校里面男生和女生的身高是否有差异时,通过抽样获得两组样本均数,然后根据假设检验(H0和H1)在统计学上进行检验,得出统计量(t、F、Z、卡方值之类的)和p值,最后做出统计推断和得出结论。没有学过统计理论的同学对这个检验的过程似懂非懂,不明白其中的道理,所以觉得难以理解,在这里举个不是特别恰当的例子:比如某美女正在纠结本周末是否去逛街,因为需要考虑气温、阳光、心情等等很多因素。我们假定只考虑气温吧,她心说,“如果气温低于5度就不去逛街”。那么无效假设H0就可以是:这周末气温低于5度;择备假设为H1:这周末气温不低于5度。这样就可以根据历史气温数据的分布情况,推算出本周末气温低于5度的概率,发现这种情况出现的可能性极低(p<0.05),所以她就得出了结论,本周末可以出去逛街。统计检验的道理就是这么一回事,即首先给出一个假设条件,然后在这个条件下通过计算推理来证明这个假设是合理的或者不合理的,从而做出理性决策。
3.关系:即研究生存时间与某些因素之间的关系。这些因素你可以称呼它们“协变量”、“预测变量”、“自变量”、“预测因子”,whatever,我暂且简单直白地称呼它们为”Xi”。怎样研究生存时间与Xi之间的关系呢?回归分析,或者叫拟合模型。涉及到模型拟合,这里有太多的内容需要深入学习和理解,如果对模型分析感兴趣,建议先学习一下线性代数和数理统计的理论知识。不管怎样,拟合模型的过程可以简单的看做“挑选模子-模拟数据-验证模子-解释结果”的过程。我个人觉得,最重要的两个环节是首尾两个环节,第一个环节是说要根据数据资料的类型选择合适的模型,比如生存时间资料就不适合一般线性回归模型,需要采用COX风险比例模型或者其他模型;第四个环节是解释结果,因为很多情况下“结果没意义”,导致研究人员纠结到死,死活不知道怎么解释与专业知识冲突或者不符合预期的统计结果,最后放出大招——篡改原始数据,得到想要的结果。如果P值都很好,那很有可能被怀疑造假。记得我老板的一句话是:一篇好的论文在于讨论部分。即使统计结果不是特别理想,那么讨论部分就可以看出文章作者的功底了。
下面就开始“执行”生存分析的“六字诀”。限于篇幅,在此就不罗列原始数据了,数据集(rawdata)包括生存时间变量time、截尾指示变量censor、分组变量group、还有后面用于COX分析的协变量--性别sex。
1.描述
对生存时间进行描述时一般采用中位生存时间并绘制生存曲线。中位生存时间的概念就不需多说了,关键是怎么绘制出漂亮的生存曲线。SAS9.3软件增强了ODS图形功能,很多统计分析过程都可以自动输出合适的统计图形。比如LIFETEST过程就可以自动输出生存曲线,只需要提交如下代码:
- proc lifetest data=rawdata;
- time time*censor(0);
- strata group;
- run;
输出的图形结果如下:
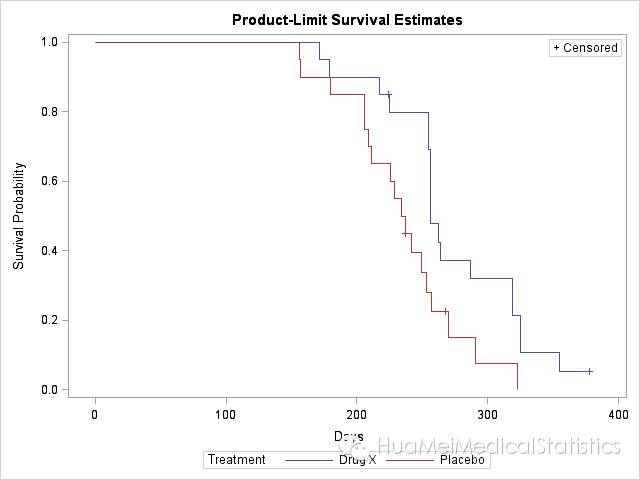
图形结果还算不错哦。但如果想要对这个图形进行局部修改:比如修改标题、调整线型的粗细,改变截尾符号,图例位置等等,就可以用GTL语言对这个图形进行适当调整,代码如下:
- /*STEP 1建立模板*/
- proc template;
- /*定义一个绘图模板stepplot */
- define statgraph stepplot;
- begingraph;
- /*标题*/
- entrytitle"Kaplan-MeierSurvival Plot by Samarih";
- /*布局*/
- layout overlay /yaxisopts=(linearopts=(viewmin=0 viewmax=1));
- /*绘图语句stepplot和scatterplot*/
- stepplot x=Timey=Survival / LINEATTRS=(THICKNESS=3)
- group=Stratum name="step";
- scatterplot x=Timey=Censored / name="scat"
- legendlabel="Censored"markerattrs=(symbol=circlefilled size=10color=black);
- /*图例语句*/
- discretelegend"step" /location=inside
- halign=right valign=top across=1;
- discretelegend"scat" /
- location=inside halign=leftvalign=bottom;
- endlayout;
- endgraph;
- end;
- run;
- /*STEP2 实现模板*/
- proc sgrender data=plotdata template=stepplot;
- run;
调整好的图形如下:
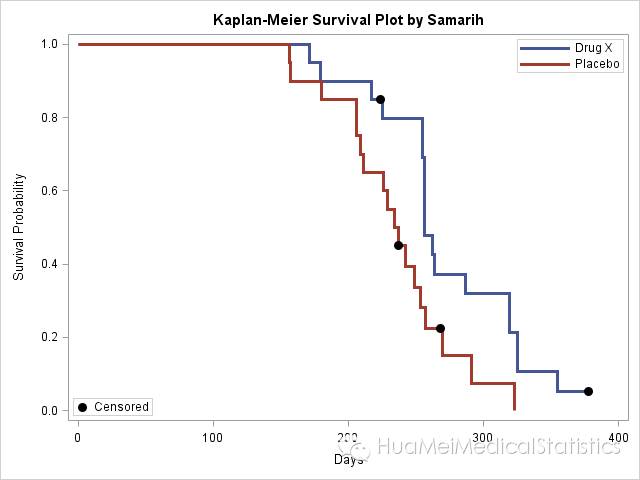
在这里需要注意,生存曲线的绘图语句在GTL里面是STEPPLOT语句,X轴是生存时间,Y轴是计算出的生存率。那么如果只有原始数据,还需要自己计算生存率吗?!当然不需要,请注意proc sgrender语句,使用的数据集是plotdata,这个就是绘图用的数据集了,和原始数据集不一样的。怎么来的?原来SAS可以把原始数据集的分析结果导出,便于日后使用,比如绘图。所以只需要在lifetest过程前加上ods output语句就OK了,输出一个数据集叫做plotdata。代码如下:
- ods output survivalplot=plotdata;
- proc lifetest data=rawdata ;
- time time*censor(0);
- strata Treatment;
- run;
如果想要了解GTL绘图的原理,可以打开生成的plotdata数据集,看看每条语句的含义,也可以通过调试检查各选项的功能具体是什么,在此不作介绍。
2.比较
通过观察生存曲线,药物X组比安慰剂组的效果看似要好,使用药物X可以延长病人的生存时间。但是要做出这个结论仍然需要“证据”支持,这就是通过假设检验来比较两组病人的生存时间分布是否真的不同。我们在上一步调用了lifetest过程,并且用strata语句指定比较不同的treatment组,所以SAS给出了如下的检验结果:
| Test | Chi-Square | DF | Pr > Chi-Square |
| Log-Rank | 5.6485 | 1 | 0.0175 |
| Wilcoxon | 5.0312 | 1 | 0.0249 |
| -2Log(LR) | 0.1983 | 1 | 0.6561 |
如果这三种检验方法的P值都小于0.05就很好解释了,但为什么前两行的结果很理想,而最后一行的P值却大于0.05呢?直接一点,因为-2Log(LR)检验方法不合适,结果不可信。至于怎么判断,不深入讨论。从这个例子也可以看出来,做统计分析时,需要找对合适的方法,如果对自己的数据都不了解,就不要着急进入下一个环节。
结果显示,药物X组和安慰剂组病人的中位生存时间分别是256天和235.5天,上面的检验P值证实两组之间的生存时间的确是不同的,故可以认为药物X有较为良好的效果,能够延长病人的生存时间。
到此,“比较”分析就结束了,但要解释统计分析的结果仍然需要进行大量的文献工作,比如有没有类似的研究或者医学理论来支持你的研究结论等等,这个要比P值重要得多的多。
3.关系:
研究生存时间与某些影响因素(自变量Xi)之间的联系,最常见的是建立COX比例风险模型。经过慎重考虑,还是不要把COX比例风险模型的公式拿出来了,日后再详细介绍其中原理。你只需明白一点,一旦求出Xi对应的回归系数ßi,而与OR、RR类似的测量指标HR(风险比值)就等于exp(ßi)。
还是用上面的数据,调用phreg过程进行COX分析,代码如下:
- proc phreg data=rawdata;
- class treatment(ref='Placebo') sex(ref='F');
- model time*censor(0) = treatment sex;
- run;
需要注意的是class语句,不仅指定了分类变量包括treatment和sex变量,而且指定了参照组分别是'Placebo'和'F'。这样做的好处是可以人工明确参照是哪个分类水平,避免出现混乱。我们先看一下SAS的分类变量编码(哑变量化)的结果,如下表:
| Class Level Information | ||
| Class | Value | Design Variables |
| Treatment | Drug X | 1 |
| Placebo | 0 | |
| Sex | F | 0 |
| M | 1 | |
可以看出,分类变量的参照水平(Treatment='Placebo', Sex='F')对应的Design Variables的值为0,很多人觉得这和哑变量的结果不一致,但这就是哑变量化的结果。例如treatment变量,有两个水平,分别是“Drug X”和“Placebo”,只需要1个哑变量就可以表示treatment变量,sex变量也只需要1个哑变量表示,所以Design Variables这一列只有1列。假设还有个分类变量x有三个水平,那么Design Variables这一列就应该用两列表示x,哑变量化的结果就会像下面一样了:
| Class Level Information | |||
| Class | Value | Design Variable1 | Design Variable2 |
| Treatment | Drug X | 1 | |
| Placebo | 0 | ||
| Sex | F | 0 | |
| M | 1 | ||
| X | 1 | 1 | 0 |
| 2 | 0 | 1 | |
| 3 | 0 | 0 | |
这里,x变量就是以x=3为参照了。
COX风险比例模型的检验结果显示模型具有统计学意义,两个系数也有意义。我们重点看系数是多少以及HR的结果,如下表:
| Analysis of Maximum Likelihood Estimates | |||||||
| Parameter | DF | Parameter Estimate | Standard Error | Chi-Square | Pr > ChiSq | Hazard Ratio | |
| Treatment | Drug X | 1 | -1.18409 | 0.39943 | 8.7879 | 0.0030 | 0.306 |
| Sex | M | 1 | -2.40592 | 0.52229 | 21.2194 | <.0001 | 0.090 |
最大似然估计的结果显示ß(treatment='Drug X')=-1.18409, ß(sex='M')=-2.40592,p值分别为0.0030和<.0001,说明treatment和sex对生存时间都有影响。平衡其他因素的影响后,相比Placebo,服用Drug X能够降低病人的死亡风险(HR=0.306);同理,在其他条件相同的情况下,男性(sex=’M’)比女性(sex=’F’)的死亡风险要低(HR=0.090)。说到Hazard Ratio (HR),其实HR=exp(ß)。至于为什么是这种关系其实不难理解,按照模型的公式就能推算出来,当然也可以计算使用药物X的男性与使用安慰剂的女性之间的风险比值。
写到这里,我必须停下来了,已经敲了3000多字,字太多没人看的。最后提几点需要注意的地方。1)研究数据资料的适宜性,医学的方法也可以用到其他专业,生存分析并不必然与疾病之流挂钩,比如汽车发动机的“生存“时间。2)明确想要做什么,你不一定非要把以上三个环节一一历遍,但描述分析总归是有意义的。3)重点讨论并解释统计结果。这适用于一切关于统计分析的作业。
1F
怎么找视频呢