

人工智能很大程度上是对未知输入的分类判别, 聚类是一种将数据点按一定规则分群的机器学习技术。 这里介绍5种常见的聚类方法:
▌K-均值聚类
k均值聚类是最著名的划分聚类算法,由于简洁和效率使得他成为所有聚类算法中最广泛使用的。
K均值聚类算法是先随机选取K个对象作为初始的聚类中心。然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心
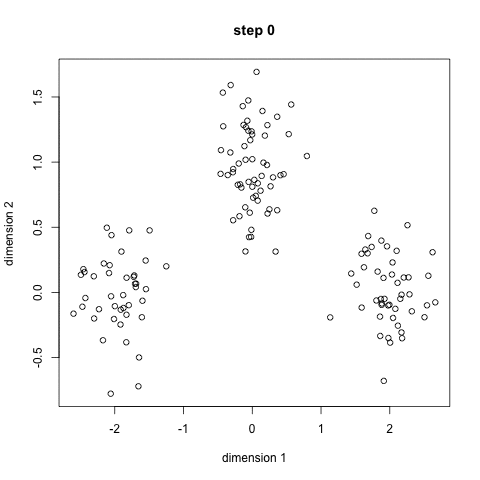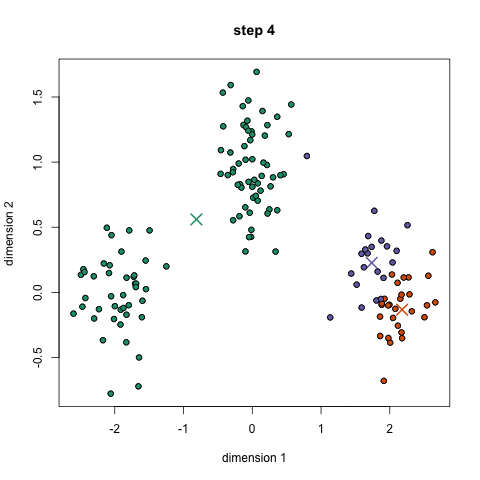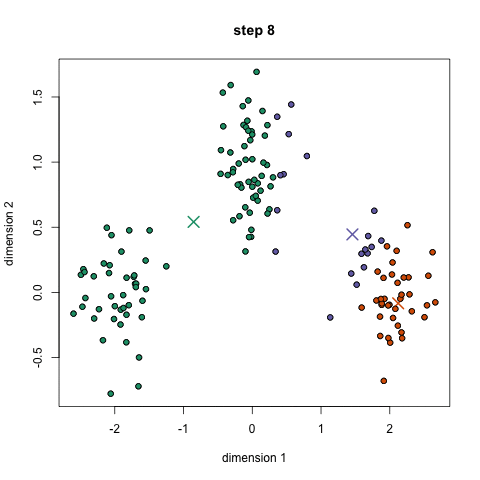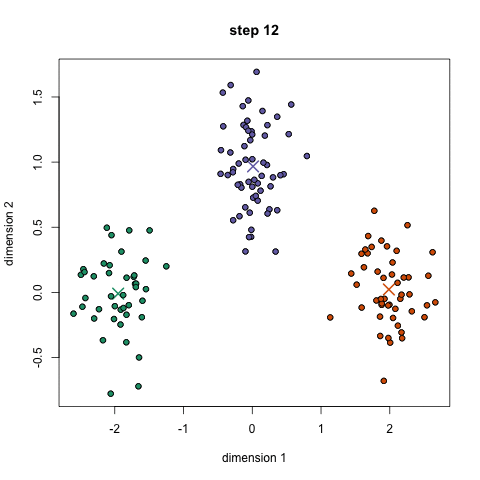
▌Mean-Shift聚类算法
MeanShift算法是一个非参数聚类技术,它不要求预先知道聚类的类别个数,对聚类的形状也没有限制。Mean Shift算法在聚类,图像平滑、分割以及视频跟踪等方面有广泛的应用。
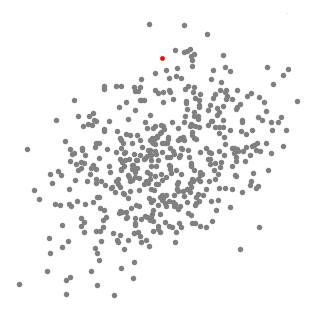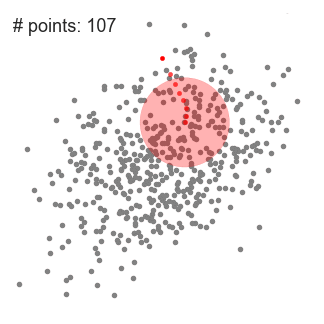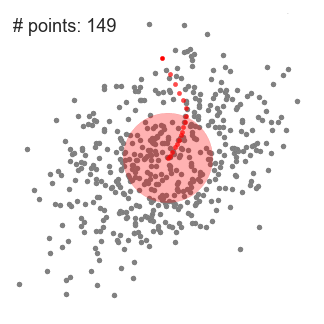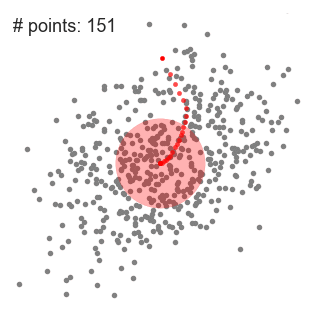

▌基于密度的噪声应用空间聚类(DBSCAN)
是一种基于密度的空间聚类算法。该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
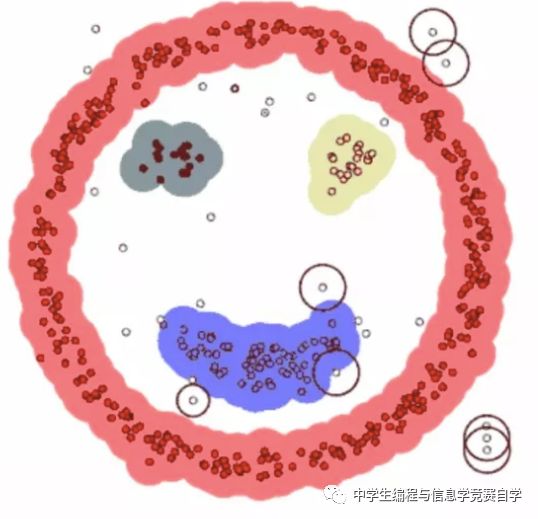
▌使用高斯混合模型(GMM)的期望最大化(EM)聚类
K-Means算法的主要缺点之一就是它对于聚类中心平均值的使用太单一,下图是K-Means失败的例子;

相较于K-means算法,高斯混合模型(GMMs)能处理更多的情况。每个聚类中心都是不同的高斯分布,也就是不同形状和选择度的椭圆。
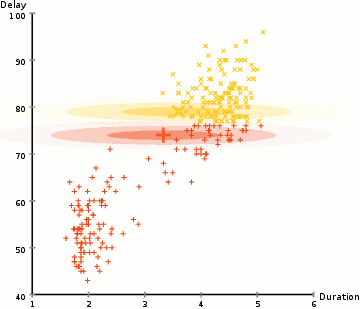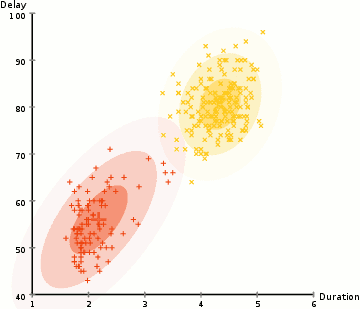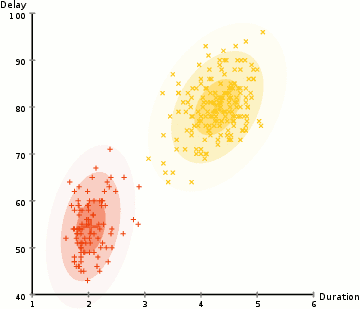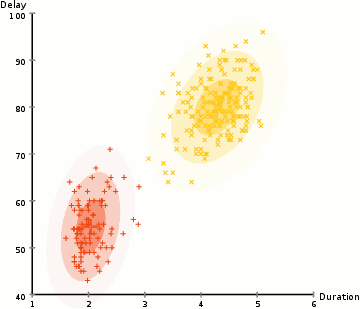
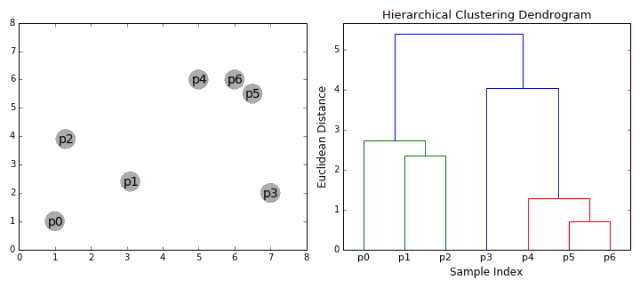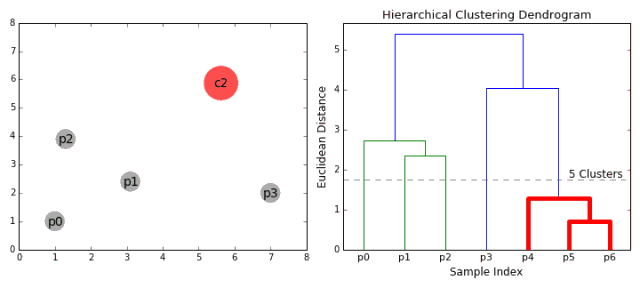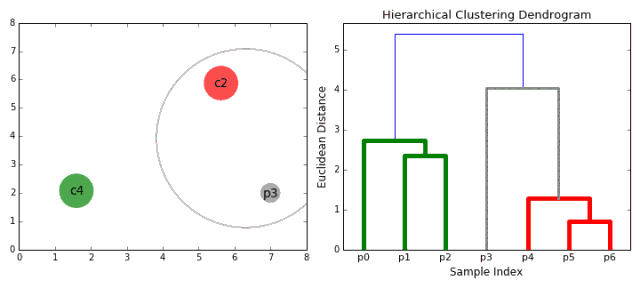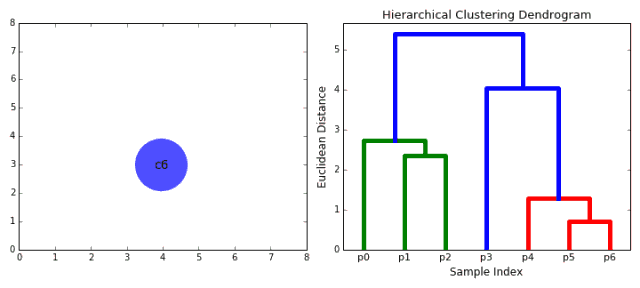
▌凝聚层次聚类
凝聚层次聚类的层次可以用树(或树状图)表示
作者| George Seif