

研究基因功能的人建个树,需要找近缘物种、外类群十几至几十个物种,费N天的劲才能做个树。而宏基因组领域的人不用去收集其它物种,因为研究的对像本身就有几百到几千的物种,为了方便阅读或展示主要信息,我们反而会挑选结果中前100以内的物种去分析并展示。这是我们绝对的优势。
文中使用所有文件下载链接:http://pan.baidu.com/s/1hs1PXcw 密码:y33d R代码在文件夹中ggtree.r文件,其它结果数据文件主要位于result目录,具体使用文件见代码部分,需要什么文件单独下载,文件内有整个扩增子分析流程,6G的数据。
本文的分析,是建立在扩增子分析流程基础上,想要了解每个文件的由来,请阅读《2扩增子分析流程:零基础自学-把握分析细节》。
筛选合适数量的物种
正如上面所説,扩增子结果有成千上万的OTU,全画是看清的。需要挑重点,怎么挑,才能数据量即不多,也不少呢?
我们在《扩增子分析解读6进化树》中构建了进化树result/rep_seqs.tree文件。这是基于全部的OTU,用于计算Alpha和Beta多样性的。我们需要筛选高丰度的OTU,构建进化树用于展示,比如丰度大于0.5%或0.1%。《扩增子分析解读7筛选进化树》中采用0.1%丰度筛选获得104条序列,其实还是有点多,因为过百的序列展示过于密集,人类读起来有困难,用于圈图360度展示还可以接受,但是矩形不太适合。本文为了展示多种组合图形,采用OTU丰度大于0.5%的筛选阈值。
- # 选择OTU表中丰度大于0.5%的OTU
- filter_otus_from_otu_table.py --min_count_fraction 0.005 -i result/otu_table4.biom -o temp/otu_table_k5.biom
- # 获得对应的fasta序列
- filter_fasta.py -f result/rep_seqs.fa -o temp/rep_seqs_k5.fa -b temp/otu_table_k5.biom
- # 统计序列数量,28条;30条以字比较大,容易看清标签
- grep -c '>' temp/rep_seqs_k5.fa # 28
- # clusto多序列比对
- clustalo -i temp/rep_seqs_k5.fa -o temp/rep_seqs_k5_clus.fa --seqtype=DNA --full --force --threads=30
- # 使用qiime的脚本调用fastree建树
- make_phylogeny.py -i temp/rep_seqs_k5_clus.fa -o temp/rep_seqs_k5.tree
- # 格式转换为R ggtree可用的树,之前加载报错,后来删除'符号后正常
- sed "s/'//g" temp/rep_seqs_k5.tree > result/rep_seqs_k5.tree # remove '
- # 获得序列ID
- grep '>' temp/rep_seqs_k5_clus.fa|sed 's/>//g' > temp/rep_seqs_k5_clus.id
- # 获得这些序列的物种注释,用于树上着色显示不同分类信息
- awk 'BEGIN{OFS="\t";FS="\t"} NR==FNR {a[$1]=$0} NR>FNR {print a[$1]}' result/rep_seqs_tax_assignments.txt temp/rep_seqs_k5_clus.id|sed 's/; /\t/g'|cut -f 1-5 |sed 's/;/\t/g' |cut -f 1-5 > result/rep_seqs_k5.tax
OTU按分类门级别上色
在Rstudio中,设置工作目录为下载测序数据的目录。有三种方法可选: Ctrl+Shift+H,或在Session菜单中选择,或使用setwd()命令设置工作目录。
- # 运行环境R3.4.1,ggtree版本1.8.1
- # 安装ggtree包,末安装者将FALSE改为TRUE即可
- if (FALSE){
- source("https://bioconductor.org/biocLite.R")
- biocLite(c("ggtree"))
- }
- # 设置工作目录:选择 Session - Set working directory - To source file location,
- # 我们的脚本ggtree.r位于测试数据文件夹根本目录,执行上面的操作可调置工作目录为脚本所在文件夹
- rm(list=ls())
- # 设置工作文件夹进入result,我们使用的大部分文件在此目录
- setwd("result")
- # 加载ggtree包
- library("ggtree")
- # 读入分析相关文件
- # 读取树文件
- tree <- read.tree("rep_seqs_k5.tree")
- # 读取树物种注释信息
- tax <- read.table("rep_seqs_k5.tax", row.names=1)
- # 物种注释等级标签,共七级,但细菌末分类物种太多,一般只能在门、纲、目水平比较确定
- colnames(tax) = c("kingdom","phylum","class","order")
- # 按门水平建树并上色
- ## 给每个OTU按门分类分组,此处可以更改为其它分类级别,如纲、目等,即phylum替换为order或class即可
- groupInfo <- split(row.names(tax), tax$phylum) # OTU and phylum for group
- ## 将分组信息添加到树中
- tree <- groupOTU(tree, groupInfo)
- # 画树,按组上色
- ggtree(tree, aes(color=group))+ theme(legend.position = "right")+geom_tiplab(size=3)
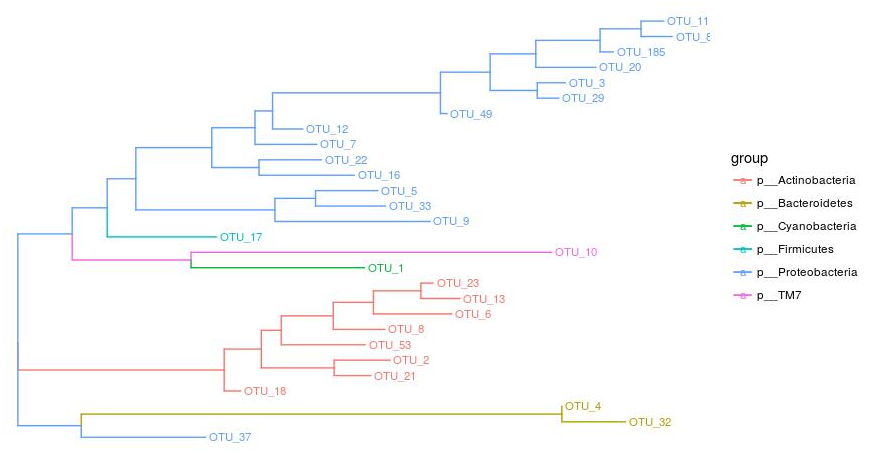
按门水着色的矩形进化树。我们可以看到我们基于V5-V7 rDNA区构建的树与分类学门水平相关性较好,如上面一大枝蓝色为Proteobacteria(变形菌门),下面红色的一大枝为Actinobacteria(放线菌门);也有一些异常结果,如最下面的蓝色变形菌门与黄色拟杆菌门聚在一起,导致分类与进化关系不一致原因很多,如V5-V7甚至rDNA并不能代表菌的真实分类、相同rDNA也可能有不同a功能或新物种等原因。
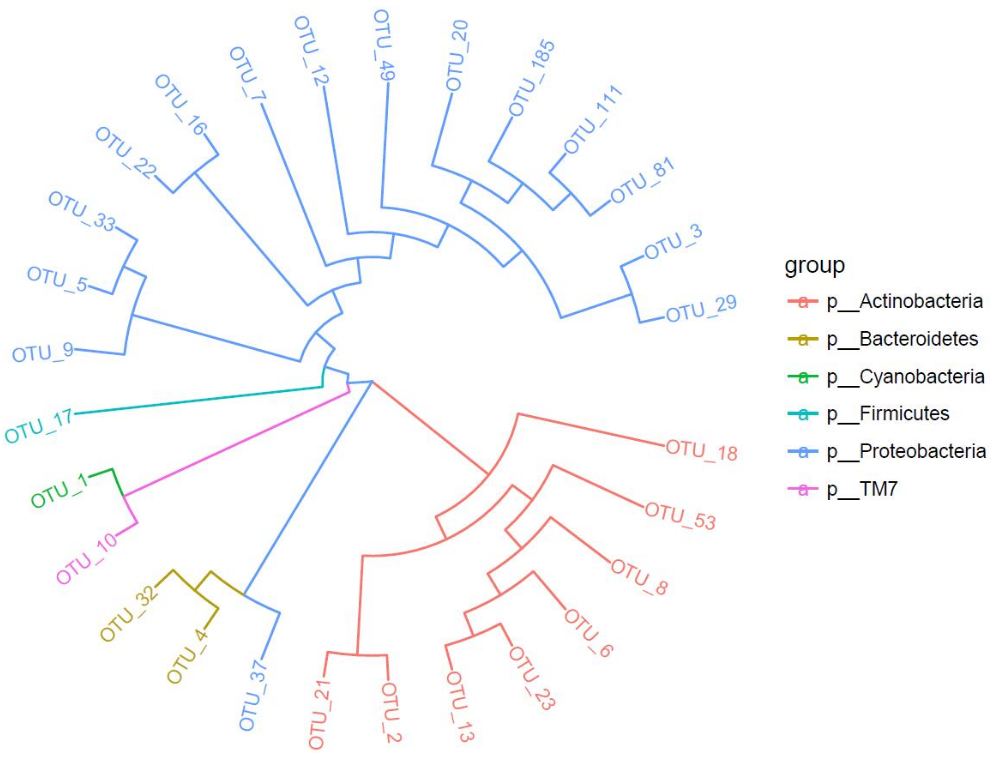
画圈图
- # 画圈图并保存PDF
- pdf(file="ggtree_circle_color.pdf", width=9, height=5)
- ## tiplab2保证标签自动角度,默认无图例,要显示需要+theme
- ggtree(tree, layout="fan", ladderize = FALSE, branch.length = "none",aes(color=group))+geom_tiplab2(size=3)+ theme(legend.position = "right")
- dev.off()
树+样品丰度热图
我们最常用的是高丰度、或差异OTU的树图,结合各样品的表达热图,来展示各样品间的重复性好坏、以及组间的差异。
- # 树+丰度热图
- # 思路:矩形树右端添加每个样品的表达丰度。
- ## 读取OTU表
- otu_table = read.delim("otu_table.txt", row.names= 1, header=T, sep="\t")
- ## 读取实验设计
- design = read.table("design.txt", header=T, row.names= 1, sep="\t")
- ## 取实验设计和OTU表中的交集:样本可能由于实验或测序量不足而舍弃掉,每次分析都要筛选数据
- idx=intersect(rownames(design),colnames(otu_table))
- sub_design=design[idx,]
- ## 按实验设计的样品顺序重排列
- otu_table=otu_table[,idx]
- ## 将OTU表count转换为百分比
- norm = t(t(otu_table)/colSums(otu_table,na=T)) * 100 # normalization to total 100
- ## 筛选树中OTU对应的数据
- tax_per = norm[rownames(tax),]
- ## 保存树图于变量,align调置树OTU文字对齐,linesize设置虚线精细
- p = ggtree(tree, aes(color=group))+ theme(legend.position = "right")+geom_tiplab(size=3, align=TRUE, linesize=.5)
- p
- pdf(file="ggtree_heat_sample.pdf", width=9, height=5)
- ## 添加数字矩阵
- ## offset设置两者间距,用于解决图重叠问题;width设置热图相对树图的宽度,解决热图和树图大小关系;font.size设置热图文字大小,解决文字过大重叠;colnames_angle调整热图标签角度,解决文字重叠问题;hjust调整热图标签位置,解决文字与热图重叠问题。
- gheatmap(p, tax_per, offset = .15, width=3, font.size=3, colnames_angle=-45, hjust=-.1)
- dev.off()
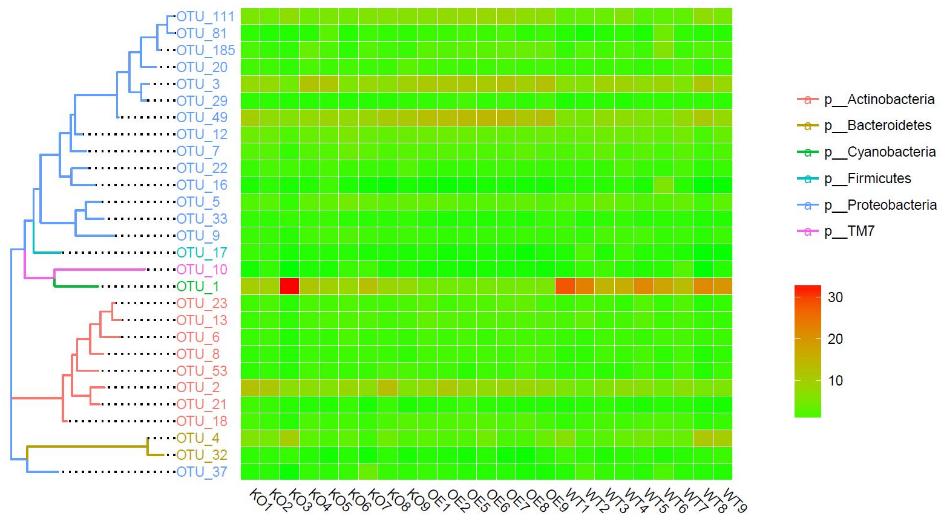
现在我们看到了所有高丰度OTU的进化树,结合所有样品的相对丰度热图。树图为了让标签同时作为右侧热图的标签,采用了添加虚线左对齐的方式;热图展示样品中每个OTU的相对丰度百分比,我们可以看到各组内样品间的重复情况,也能看到各组间是否有差别,比如OTU_1在WT中整体偏高,而OTU_111却在WT中整体偏低。样品名为了显示全采用倾斜45度角,右侧还有门分类学、相对丰度百分比的图例。
树+组均值热图
- # 树+ 组均值热图
- ## 有时样本过多也无法展示和阅读,需要求各组均值展示:需要将分组信息添加至样品相对丰度表,再分类汇总
- ## 提取实验设计中的分组信息
- sampFile = as.data.frame(sub_design$genotype,row.names = row.names(sub_design))
- colnames(sampFile)[1] = "group"
- ## OTU表转置,让样品名为行
- mat_t = t(tax_per)
- ## 合并分组信息至丰度矩阵,并去除样品名列
- mat_t2 = merge(sampFile, mat_t, by="row.names")[,-1]
- ## 按组求均值
- mat_mean = aggregate(mat_t2[,-1], by=mat_t2[1], FUN=mean) # mean
- ## 去除非数据列并转置
- mat_mean_final = do.call(rbind, mat_mean)[-1,]
- ## 重命名列名为组名
- colnames(mat_mean_final) = mat_mean$group
- ## 按组均值热图
- pdf(file="ggtree_heat_group.pdf", width=7, height=5)
- gheatmap(p, mat_mean_final, offset = .05, width=1, font.size=3, hjust=-.1)
- dev.off()
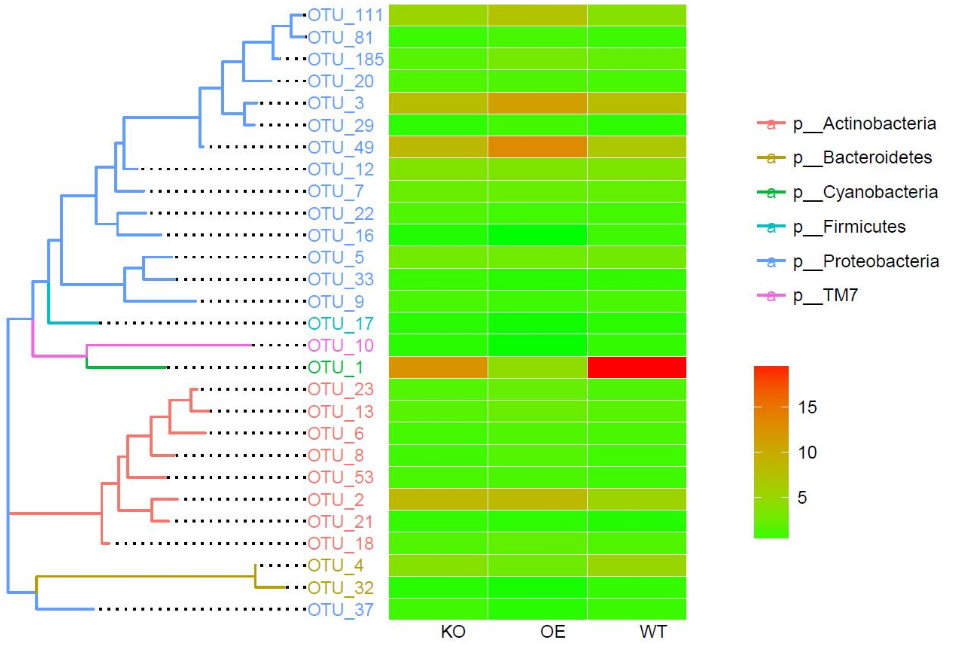
按组显示,是不是清爽了许多。
Reference
- ggtree官方文档 https://www.bioconductor.org/packages/release/bioc/vignettes/ggtree/inst/doc/ggtree.html
- ggtree美化 https://www.bioconductor.org/packages/release/bioc/vignettes/ggtree/inst/doc/advanceTreeAnnotation.html
- facet_plot: 关联数据和进化树的通用方法 http://mp.weixin.qq.com/s/FlrnY9GeV5fHa6EZpZhTJA
- 软件原文 G Yu, DK Smith, H Zhu, Y Guan, TTY Lam. ggtree: an R package for visualization and annotation of phylogenetic trees with their covariates and other associated data. *Methods in Ecology and Evolution. doi:10.1111/2041-210X.12628.
1F
您好,非常感谢您的文章,让我受益匪浅,我想跟着您的脚步好好学习,原来的那个失效了,您能否再发一下那个百度网盘链接,非常感谢!! :smile:
2F
您好!不知道能不能更新一下网盘里的资料,非常感谢!
3F
能否更新一下您的百度网盘链接呢,多谢多谢