

首先向大家简单介绍下GEO数据库,它是为了共享基因表达数据而建立的一个在线数据库。很多文章发表都需要上传到GEO数据库,还不赶紧学习下,(*^__^*)。
如果要上传GEO数据库,首先要建立一个NCBI的账号,再建立一个GEO的账号。可以从https://www.ncbi.nlm.nih.gov/geo/的LogintoSubmit进入创建。

创建完成后,再点击Submission Guidelines进入GEO主页。
接下来,选择你要上传的数据类型,这里只介绍上传转录组测序数据。
点击High-throughput sequence submissions
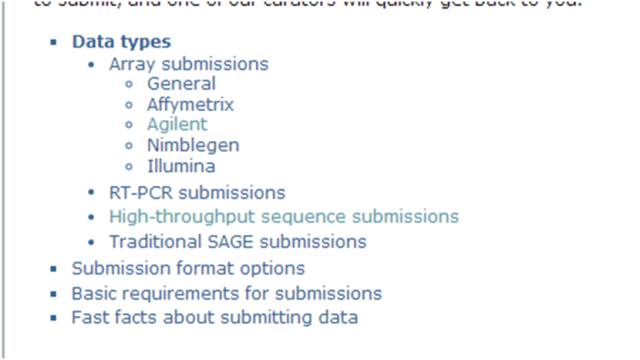
上传总共需要3类文件,
1.Metadata spreadsheet(上传所需要填写的表格,比较麻烦,后面详细介绍)
2.Processed datafiles(基因表达量文件,也就是FPKM)
如下图所示。因为这里有Novel类基因(预测基因),所以需要提供:
Chromosome(染色体号)Strand(链的正负)start(起始位置)length(长度)。
如果没有Novel类基因,只需要提供A、B列即可。

3.Raw data files(原始的测序数据)
Metadata spreadsheet详细介绍
进入High-throughput sequence submissions页面后,下载Metadata spreadsheet,
![]()
1SERIES:跟文章相关的内容:标题,摘要,实验设计,参与者(根据自己情况填写);

2SAMPLES:跟样本信息相关的内容:样本名称,物种,特征,及对应的表达值数据和原始数据;

3PROTOCOLS:样本的实验准备和文库构建的描述;

4DATAPROCESSINGPIPELINE:数据处理方面的描述,如数据预处理,数据比对,采用的基因组版本等;

5PROCESSEDDATAFILES:处理后数据名称,格式,及MD5码。即FPKM文件,其中file type一列可以统一写成abundance measurements。file checksum列即为MD5码(MD5码生成软件可以直接百度下载)。

6RAWFILES:原始数据名称,格式,MD5码,平台类型,测序读长及单双端信息;

7PAIRED-END EXPERIMENTS:如果是双端测序,还需要填写双端原始数据的名称,插入片段长度及插入长度的标准偏差。

到这里METADATA TEMPLATE算是填写完成了,接下来就可以进行上传数据啦!
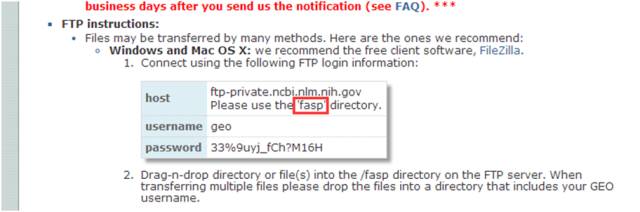
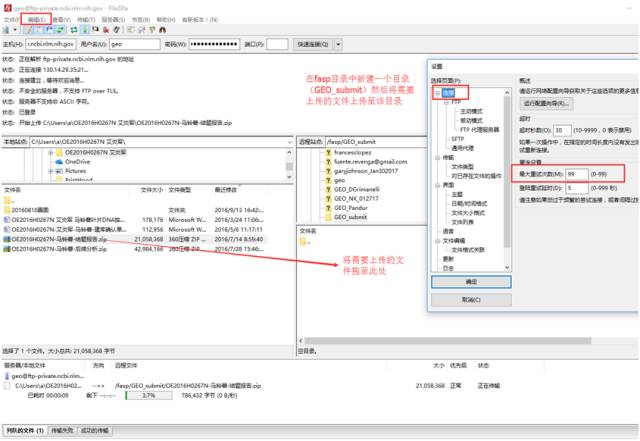
首先需要下载Filezilla软件,然后在Filezilla中输入GEO地址:ftp-private.ncbi.hlm.nih.gov并登陆(用户名和密码可进入High-throughput sequence submissions页面中寻找,有
可能定期更新),即可连接GEO数据库进行上传了。
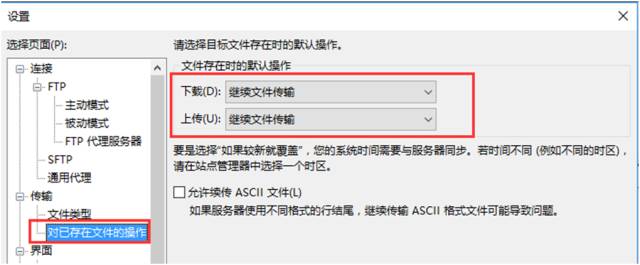
注:Filezilla软件的设置一定要根据下图重新设置,不然可能会一直中断
等待数据都上传完成后就可以写邮件告诉GEO数据上传完成了。邮件内容可以写成如下格式(仅供参考^_^)
Dear sir,
We had finished the raw data uploading.Please check according to the following information:
GEOaccount;你的GEO用户名
Path of the directory deposited;(存放数据的路径,例如/fasp/12345)
Public release date;例如2017/2/21(根据情况填写数据需要公开的日期)
Our data files were named as follows:
GX2_1.clean.fq.gzGX2_2.clean.fq.gzGX3_1.clean.fq.gzGX3_2.clean.fq.gzGX4_1.clean.fq.gzGX4_2.clean.fq.gzGX5_1.clean.fq.gzGX5_2.clean.fq.gzGX6_1.clean.fq.gzGX6_2.clean.fq.gz
Our processed data files were named as follows:
GX2.txt,GX3.txt,GX4.txt,GX5.txt,GX6.txt
And METADATA TEMPLATE was named as: seq_template_v2.1.xls
最后,就大功告成啦,接下来两天内应该会收到邮件,如果上传成功就会给你GEO的登录号,不然也会告诉你哪里有错误,需要重新修改。