

针对不同的变异类型,HGVS制定了相应的变异描述规则。本篇文章针对DNA水平不同变异类型进行命名格式介绍。
置换Substitution
HGVS定义:
a sequence change where, compared to a reference sequence, one nucleotide is replaced by one other nucleotide.
描述格式:
“prefix”“position_substituted”“reference_nucleotide””>”new_nucleotide”
如:g.123A>G
“prefix” =参考序列 = g.
“position_substituted” = 被置换碱基位置= 123
“reference_nucleotide” = 被置换的碱基= A
”>” = 置换为= >
“new_nucleotide” = 置换后新的碱基= G
有些注意的点:
1. predix:参考序列可以是g.(基因组)、m.(线粒体)、c.(编码DNA)、n.(非编码DNA)。
2. 碱基数:置换不局限于单碱基之间的置换,可以是多个碱基,可以描述为delins。涉及多个碱基发生变异时,若是两个变异,则这个变异单独描述而不用delins进行合并描述。例外的情况:涉及的多个变异的碱基共同影响了一个氨基酸,则需要合并描述,使用delins,如c.142_144delinsTGG (p.Arg48Trp)。
多态性位点不能描述为:c.76A/G,尽管过去使用此形式描述多态性位点,但现在的观点是要客观中立的描述碱基的变化,而不应该带有任何预测或已知功能的信息。
举个栗子:
- NC_000023.10:g.33038255C>A
33038255位置的C被A取代。
- NG_012232.1(NM_004006.1):c.93+1G>T
编码DNA序列的c.93+1位置的G被T取代。(上篇文章中介绍了编码DNA位置描述,此处不再赘述。)
- LRG_199t1:c.79_80delinsTTor c.[79G>T;80C>T]
一般情况下,推荐使用c.79_80delinsTT形式,在c.79G>T和c.80C>T两个变异中其中一个为已知的高频变异的情况下,推荐使用c.[79G>T;80C>T]。
注意:根据碱基置换的定义,是一个碱基被置换为另一个碱基,因此,下列的描述方式是错误的:c.79_80GC>TT或c.79GC>TT。
- NM_004006.1:c.[145C>T;147C>G]
上述也可描述为NM_004006.1:c.145_147delinsTGG,除非c.145C>T 和 c.147C>G其中一个为已知的高频变异情况下,必须使用c.[145C>T;147C>G]。
- LRG_199t1:c.54G>H
c.54位置的G碱基被A、C或T取代。
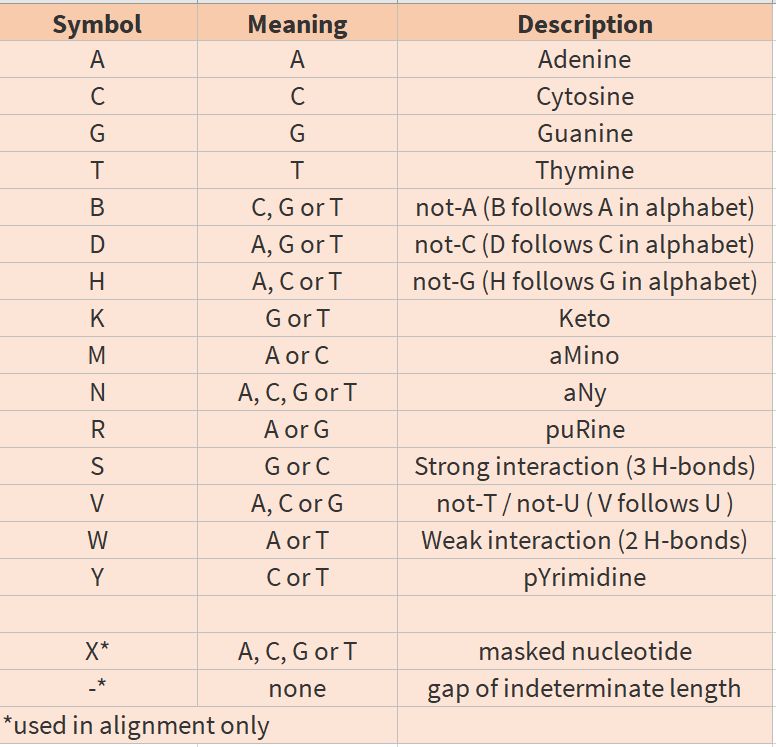
- NM_004006.1:c.123=
c.123位置没有氨基酸变化。
- LRG_199t1:c.85=/T>C
在c.85位置上,即发现了与参考序列一致的碱基T,也发现了被C取代的情况。
注意:不论上述两种情况的比例如何,都需要把参考序列一致的碱基列于第一位。
- NM_004006.1:c.85=//T>C
嵌合体情况,包括c.85=的细胞,也包括c.85T>C的细胞。
注意:不论上述两种情况的比例如何,都需要把参考序列一致的碱基列于第一位。
缺失Deletion
HGVS定义:
a sequence change where, compared to a reference sequence, one or more nucleotides are not present (deleted).
描述格式:
prefix”“position(s)_deleted”“del”
如g.123_127del
“prefix” = 参考序列= g.
“position(s)_deleted” = 缺失碱基的位置或缺失碱基起始位置= 123_127
“del” = 缺失= del
3. 最靠近3’端法则:缺失的碱基认为是靠近3’端,而不是5’端。如,ACTTTGTGCC变成了ACTTGCC,缺失了三个碱基,是ACTTTGTGCC还是ACTTTGTGCC?也就是说从5’端开始出现不一致的序列算起,还是从3’端出现不一致的序列算起?根据最靠近3’端法则,TGT比TTG更靠近3’端,因此,变异描述应认为缺失了TGT(c.5_7del),而不是TTG(c.4_6del)。
或者,我们可以这么理解,比对参考序列和变异后的序列时,从5’端开始比对至出现第一个不一致的碱基,被认为是变异的起始位置。
但也有例外的情况,缺失的多个碱基跨越内含子和外显子的边界,基于缺失的碱基对外显子的影响要大于对内含子的影响。如CAGgtg变成CAgtg,应描述为c.3+1delG,而不是c.3delG。
举个栗子:
- NG_012232.1:g.19_21del
原始序列 AGAATCACA ,缺失后的序列AGAA___CA,也可以将缺失的碱基列出,如NG_012232.1:g.19_21delTCA。
- NG_012232.1(NM_004006.1):c.183_186+48del
缺失范围跨越了外显子和内含子的边界。
- NG_012232.1(NM_004006.1):c.4072-1234_5155-246del
此种情况为跨越内含子的外显子缺失,即exon30(c.4072起始)到exon36(c.5154为止)。此种情况下,由于缺失碱基数目较多,缺失的碱基便不应该列出来了。
- NG_012232.1(NM_004006.1):c.(4071+1_4072-1)_(5154+1_5155-1)del
缺失的break point 还无法确定。
- NG_012232.1(NM_004006.1):c.(?_-245)_(31+1_32-1)del
缺失的起始位点位于基因上游某位点,已确定的最近的位点在c.-244。
重复Duplication
HGVS定义:
a sequence change where, compared to a reference sequence, a copy of one or more nucleotides are inserted directly 3' of the original copy of that sequence.
描述格式:
“prefix”“position(s)_duplicated”“dup”
如:g.123_345dup
“prefix” = 参考序列 = g.
“position(s)_duplicated” = 发生重复的碱基或碱基起始位置= 123_345
“dup” = 重复 = dup
有些注意的点:
1. 描述碱基重复的位置同样也必须遵循“最靠近3’端法则”。
2. 根据碱基重复的定义,重复的碱基是直接位于被重复的碱基3’端,而不是在其他地方(插入)。当不知道重复的碱基是直接位于重复的碱基3’端还是插入到了别的地方,不能被描述为dup,而应描述为插入(insertion)。
3. 当重复的次数大于等于2个拷贝时,需要引用中括号,列出重复的次数,如[3]代表重复了3次,可参照重复序列的命名规则(http://varnomen.hgvs.org/recommendations/DNA/variant/repeated/)。
举个栗子:
- NM_004006.2:c.20dup(NC_000023.10:g.33229410dup)
一个碱基的重复,也可以描述为c.20dupT,错误的描述为c.19_20insT,被重复的碱基为单个碱基,因此不能描述成范围的形式。
- NM_004006.2:c.20_23dup(NC_000023.10:g.33229407_33229410dup)
多个碱基的重复,需要列出被重复碱基的起始位置,因此需要描述成范围的形式。
插入Insertion
HGVS定义:
a sequence change where, compared to the reference sequence, one or more nucleotides are inserted and where the insertion is not a copy of a sequence immediately 5'
描述格式:
“prefix”“positions_flanking”“ins”“inserted_sequence”
如:g.123_124insAGC
“prefix” = 参考序列= g.
“positions_flanking” = 被插入碱基的起始位置 = 123_124
“ins” = 插入 = ins
“inserted_sequence” = 插入的碱基序列= AGC
有些注意的点:
1. 被插入碱基的起始位置是指在这两个碱基之间插入了别的序列,因此,123_124表示的是在123位碱基和124位碱基之间插入了AGC。
2. 所描述的插入的位置一定是有下划线连接起来的范围,而非单个位点。
3. 描述被插入碱基的位置同样也必须遵循“最靠近3’端法则”。
举个栗子:
- NC_000023.10:g.32867861_32867862insT(NM_004006.2:c.169_170insA)
c.169和c.170之间插入了碱基A。
- NM_004006.2:c.(222_226)insG(p.Asn75fs)
不确定插入位置时,用括号括起来,表示不确定是在c.222到c.226之间的那个位置插入了碱基G。
- NC_000004.11:g.(3076562_3076732)ins(12)
在g.3076562与 g.3076732 之间的某个位置,插入了12个碱基。
- NC_000023.10:g.32717298_32717299insNN(NM_004006.2:c.761_762insNN)
在c.761与c.762之间插入了一个碱基,但不确定插入碱基的序列。
- NM_004006.2:c.761_762insNNNNN(or NM_004006.1:c.761_762ins(5))
若插入的碱基很多,可以在括号内用数字表示。
重复序列Repeated Sequences
这种类型常见于动态突变。
HGVS定义:
a sequence where, compared to a reference sequence, a segment of one or more nucleotides (the repeat unit) is present several times, one after the other.
描述格式(重复单元):
“prefix”“position_first_nucleotide_first_repeat_unit”“repeat_sequence”[“copy_number”]
如:g.123CAG[16]
“prefix” =参考序列 = g.
“position_first_nucleotide_first_repeat_unit” = 重复单元的第一个碱基位置 = 123
“repeat_sequence” =重复单元 = CAG
[ =重复数目使用中括号 = [
“copy_number” = 重复单元数目 = 16
] = 重复数目使用中括号= ]
举个栗子:
- NC_000014.8:g.101179660TG[14]
双碱基TG重复14次
- NC_000014.8:g.101179660TG[14];[18]
双碱基TG,一个allele上重复了14次,另一个allele上重复了18次。
- NM_002024.5:c.-128_-69GGC[10]GGA[1]GGC[9]GGA[1]GGC[10]
在c.-128至c.-69这个范围内,GGC重复了10次,GGA重复了1次,GGC重复了9次,GGA重复了1次,GGC重复了10次。
上述罗列了比较常用的DNA水平的变异命名,还有一些其他的类型未列在其中,比如倒位(inversion)、转换(conversion)、易位(translocation)等。