

FASTQ文件格式和命名
高通量测序之后用于下游分析的数据一般存储在FASTQ文件中。为了节省空间,又不影响下游使用,也一般用gzip压缩的格式。
单端测序每个文库只返回一个FASTQ文件,双端测序两个FASTQ文件,左端一般命名为_1或R1,右端命名为_2或R2。
假如样品名字为ehbio,双端测序三个重复。习惯命名为ehbio_1_1.fq.gz ehbio_1_2.fq.gz, ehbio_2_1.fq.gz ehbio_2_2.fq.gz, ehbio_3_1.fq.gz ehbio_3_2.fq.gz. (第一个下划线后面的数字为重复,第二个下划线后面的数字指定哪一端)
FASTQ文件内容如下图所示: 第一行以
第一行以@开头,后面是reads的ID以及其他信息。
第二行为read的序列。
第三行以+开头,一般后面没有内容;若有则为序列的名字,与第一行相同。
第四行代表reads的质量值。质量值的计算方式为 (e是错误率,estimated probability of the base call being wrong)。如果该碱基测序出错的概率(e)为0.001,则Q应该为30。现在测序数据多采用Phred33编码,那么30+33=63,那么63对应的ASCii码为?,则在第四行中该碱基对应的质量代表值即为?。一般地,碱基质量从0-40, 即ASCii码为从 !(0+33)到I(40+33)。
+ FASTQ文件一般比较大,传输过程中可能会出现不完整情况,一般都会附带一个MD5校验值文件用于判断文件的完整性。如果文件内容不变,则MD5值不变,与是否压缩无关。
- # 获取MD5值
- ct@ehbio:~/$ md5sum test.fq.gz | tee >MD5.txt
- + d41d8cd98f00b204e9800998ecf8427e test.fq.gz
- # 验证MD5值
- ct@ehbio:~/$ md5sum -c MD5.txt
- test.fq.gz: 确定
测序量评估
测序量可以从两个水平评估:测序reads数和测序碱基数。
 测序reads数和测序碱基数都可以用简单的bash命令计算 (只是作为示例,不一定是最高效的方式)。
测序reads数和测序碱基数都可以用简单的bash命令计算 (只是作为示例,不一定是最高效的方式)。
- ct@ehbio:~/ $ zcat test.fq.gz
- @ehbio1
- ACCGAGCTTTTTTTTTTTTTT
- +
- ?????????????????????
- @ehbio2
- ACCGAGCTTTTTTTTTTTTTT
- +
- ?????????????????????
- @ehbio3
- ACCGAGCTTTTTTTTTTTTTT
- +
- ?????????????????????
- # 获取行数,然后除以4,得到reads数
- ct@ehbio:~/ $ echo $(( `zcat test.fq.gz | wc -l` / 4 ))
- 4
- # 获取碱基数
- ct@ehbio:~/ $ zcat test.fq.gz | grep -A 1 '^@' | grep '^[ACGTN]' | wc -c
- 66
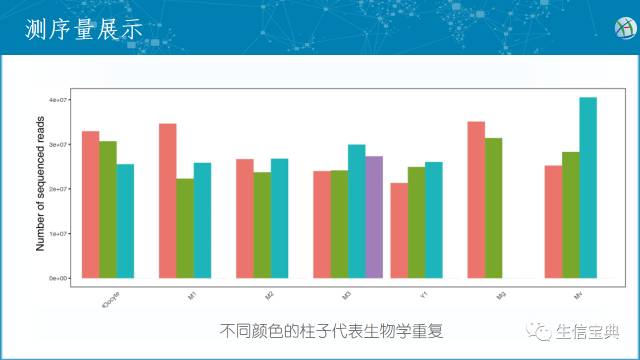
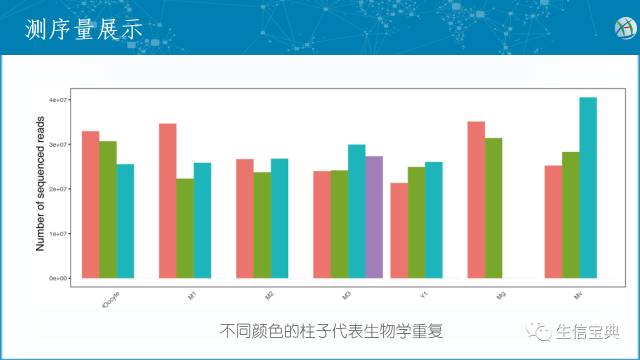
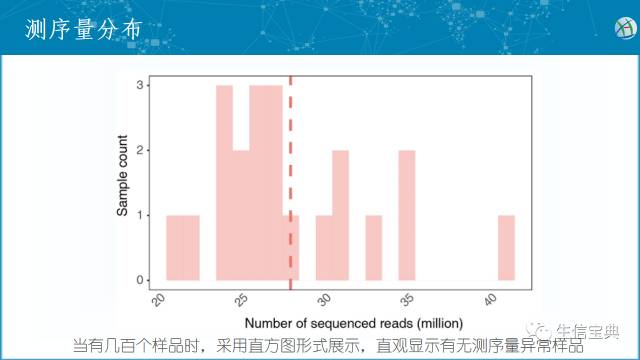
获得reads数和碱基数后,可以用表格展示。但为了更直观一般用柱状图展示。样品特别多时用直方图展示,优先关注是否存在测序量异常高或低的样品。
- 后续会推出柱状图和直方图一步绘图法
测序质量
FASTQ文件的测序质量评估一般用FastQC软件来实现。这是一个基于Java的软件包,下载下来放到环境变量即可使用。
运行方式也很简单: fastqc ehbio_1_1.fq.gz ehbio_1_2.fq.gz
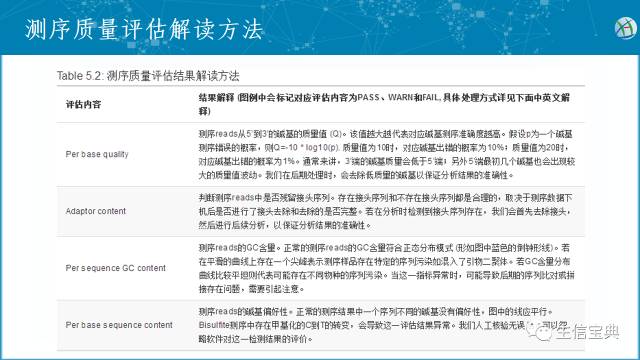
其生成结果和解释如下表所示
 具体来看,包括下面几部分内容,先是总括,包括了质量值的编码格式和总的reads数以及Reads长度的分布。
具体来看,包括下面几部分内容,先是总括,包括了质量值的编码格式和总的reads数以及Reads长度的分布。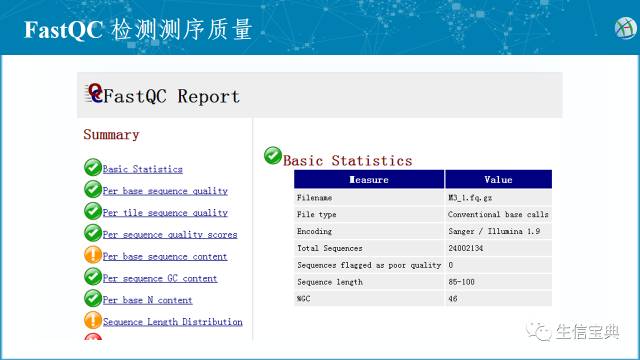 随后是单个碱基测序质量的箱线图 (箱线图通过最大值、上四分位数、中位数、下四分位数和最小值五处位置来获取一维数据的分布概况)。横坐标表示read中每个碱基的位置,纵坐标表示质量得分。将所有reads的第一位碱基质量得分进行箱线图展示得到第一位碱基质量得分的分布情况,以此类推,获得下图。左图显示每个碱基的中位质量得分(箱线图中间的蓝线)都比较高,而右图的的碱基质量得分变化较大,测序质量逐渐下降,测序质量差。可能需要进行一定的预处理比如移除低质量碱基。
随后是单个碱基测序质量的箱线图 (箱线图通过最大值、上四分位数、中位数、下四分位数和最小值五处位置来获取一维数据的分布概况)。横坐标表示read中每个碱基的位置,纵坐标表示质量得分。将所有reads的第一位碱基质量得分进行箱线图展示得到第一位碱基质量得分的分布情况,以此类推,获得下图。左图显示每个碱基的中位质量得分(箱线图中间的蓝线)都比较高,而右图的的碱基质量得分变化较大,测序质量逐渐下降,测序质量差。可能需要进行一定的预处理比如移除低质量碱基。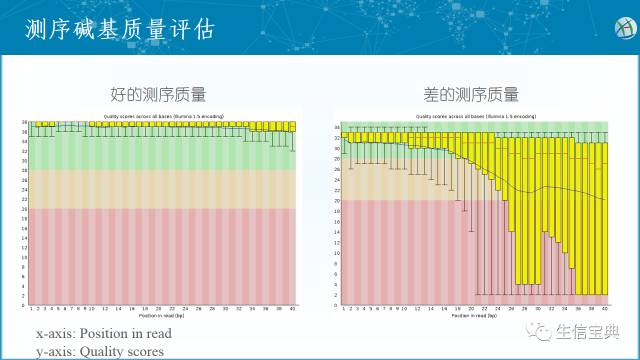 每个read GC含量的分布图。图横坐标表示平均GC含量,纵坐标表示reads数。左图显示每个read的GC分布(红线)与理论分布(蓝线)相契合,GC含量均一。右图出现了GC含量双峰,表示测序样品可能存在特定的序列污染如混入了引物二聚体,当这一指标异常并且导致后期的序列比对率很低时,需要引起注意。
每个read GC含量的分布图。图横坐标表示平均GC含量,纵坐标表示reads数。左图显示每个read的GC分布(红线)与理论分布(蓝线)相契合,GC含量均一。右图出现了GC含量双峰,表示测序样品可能存在特定的序列污染如混入了引物二聚体,当这一指标异常并且导致后期的序列比对率很低时,需要引起注意。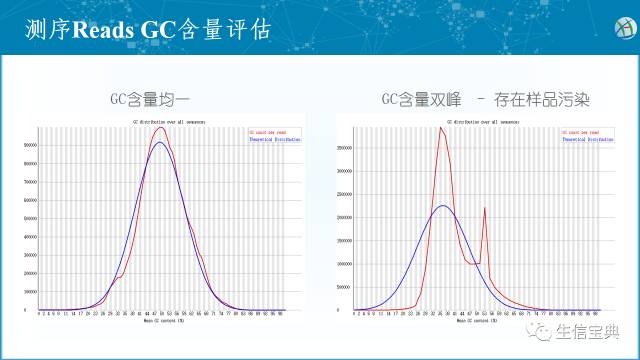 接头序列含量图。横坐标表示read中碱基的位置,纵坐标表示接头序列含量。从图中可以得知read的前17 bp是干净的,之后的位置出现了比例不等的接头序列,需要去除。另一方面也反映了这个库的质量很差,有可能需要重建。
接头序列含量图。横坐标表示read中碱基的位置,纵坐标表示接头序列含量。从图中可以得知read的前17 bp是干净的,之后的位置出现了比例不等的接头序列,需要去除。另一方面也反映了这个库的质量很差,有可能需要重建。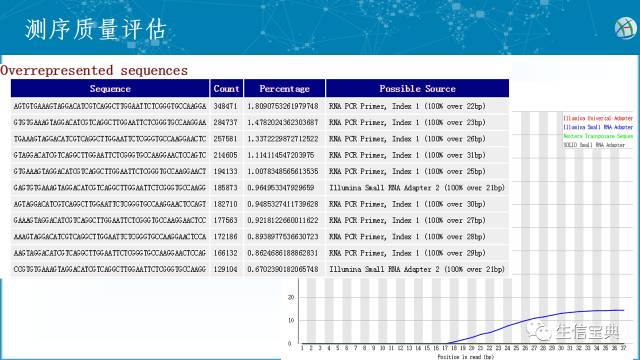
当样品数目很多时,会得到更多的质量评估图,结果很不直观。因此可以用下面所示的所有样品测序质量的散点图来表示。通过GC含量(横坐标)和碱基测序质量(纵坐标)来判断样品的测序质量。
- + 两个值都是FAIL的样品,需要重点关注。

来自外部的引用