

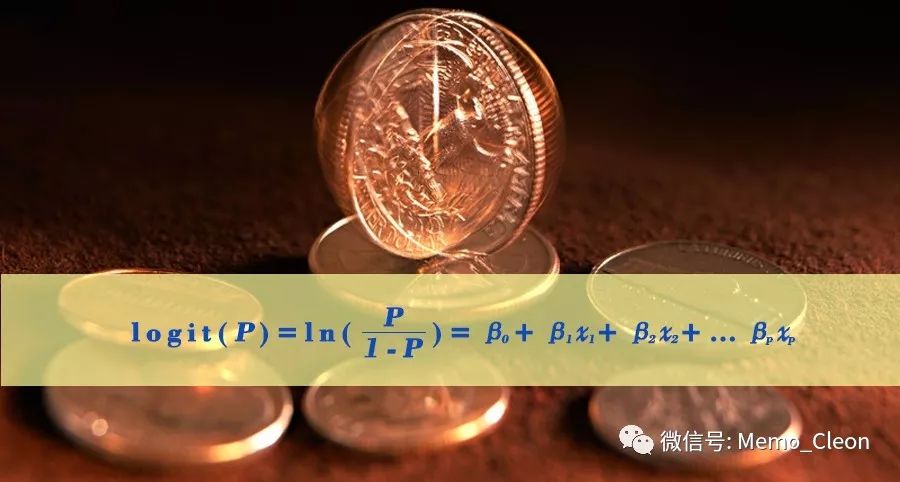
- 个概念:RR和OR
- 二分类资料的logistic回归SPSS操作示例
- 几个需要注意的问题:样本量、哑变量、模型拟合效果和拟合优度检验、多重共线
【1】两个概念
RR(Relative Risk):相对危险度,也称危险比(Risk Ratio)或率比(Rate Ratio),在前瞻性研究中用以表示暴露与疾病发生的关联强度,说明暴露组发病危险是非暴露组发病危险的多少倍,是两组发病率之比,计算公式为:
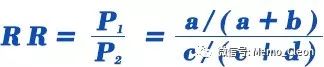
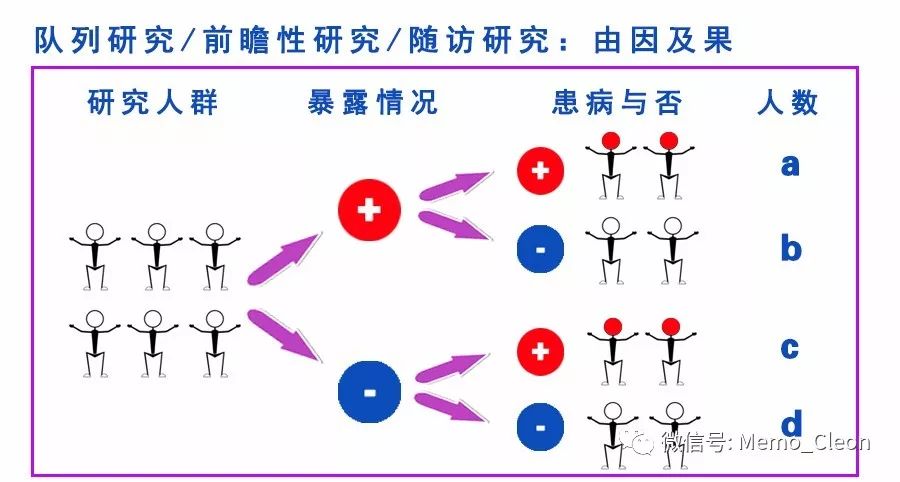
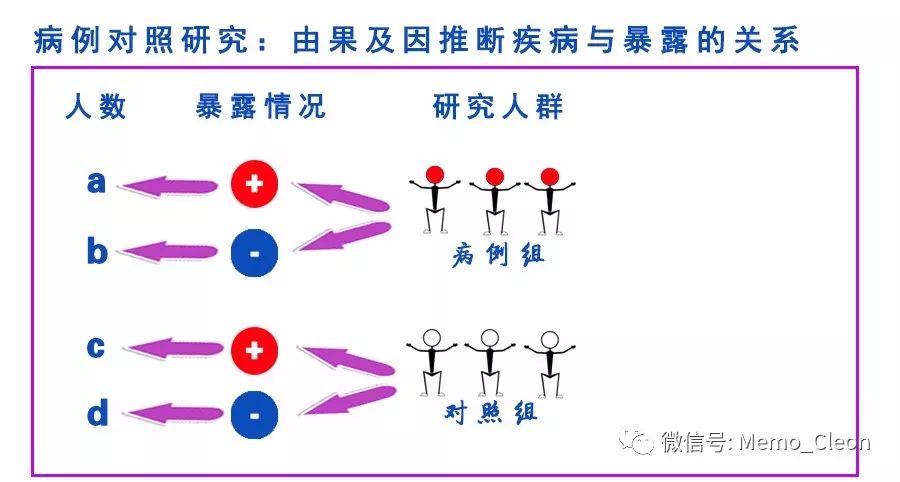
OR(Odds Ration):比值比,优势比,比数比。在病例对照研究中说明暴露与疾病的关联强度,它是暴露在某危险因子下的发病率P1与不发病率之比(1-P1)与未暴露在某危险因子下的发病率P2与不发病率(1-P2)之比的比值。
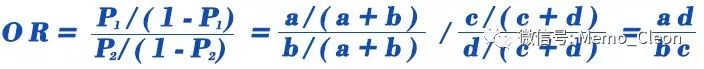
比值(odd)表示发生的可能性与不发行的可能性之比,odds1=P1/(1-P1),odds2=P2/(1-P2)。OR=odds1/odds2=ad/bc
在logistic回归中,各自变量的回归系数βi表示自变量Xi每改变一个单位,比值比的自然对数值该变量,而exp(βi)即OR,表示自变量Xi每改变一个单位,阳性结果出现概率与不出现概率之比是变化前相应比值的倍数,即优势比。当阳性结果出现概率较小时(一般小于0.05)或者较大时(大于0.95),OR=(P1/(1-P1))/(P2/(1-P2))≈P1/P2=RR
【2】二分类资料的logistic回归SPSS操作示例
适用条件:①因变量为二分类变量,自变量可以是连续变量也可以是分类变量;②各观测间相互独立;③自变量与因变量logit(P)之间存在线性关系;④自变量间不存在多重共线;⑤尽量避免异常值,残差服从二项分布合计为零;⑥研究对象无论是病例组还是对照组,样本量至少是需要分析的自变量个数的10倍,多分类自变量的哑变量的参照水平频数至少为30。
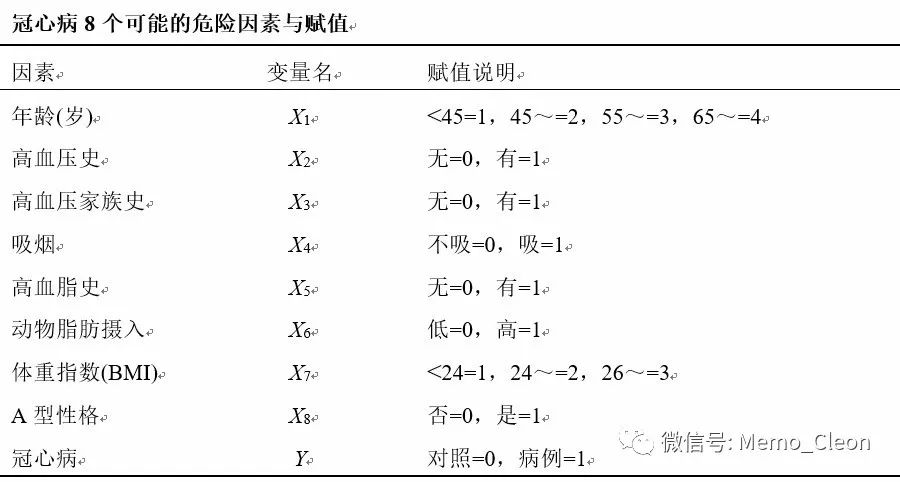
示例:探讨冠心病发生的有关危险因素
(1)数据录入赋值。二分类变量取值只有“0”和“1”两个值,本例年龄和体重指数严格来讲是要设成哑变量的(可参见本文后面关于哑变量的介绍),但由于样本量的问题,为更好的演示spss操作,本例按等级资料直接赋值。
(2)分析(Analyze)>>回归(Regression)>>二分类logistic(Binary Logistic…)
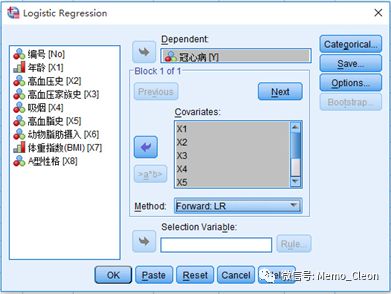
因变量(Dependent):选入冠心病[Y]
协变量(Covariates):选入自变量[X1]-[X8]
筛选变量方法(Method):
- 进入(Enter):强行引入,全部变量一次进入模型,不进行筛选
- 向前:条件(Forward:Conditional):向前逐步选择法,剔除变量的标准是条件参数估计的似然比检验
- 向前:似然比(Forward:LR):向前逐步选择法,剔除变量的标准是最大偏似然估计的似然比检验
- 向前:Wald(Forward:Wald):向前逐步选择法,剔除变量的标准Wald卡方检验不同的向前法选入自变量时均采用比分检验,只是采用的剔除变量的检验方法不同
- 向后法也三种,剔除标准分别对应条件、似然比和Wald
本例选中Forward:LR。
分类变量(Categorial…):可将多分类自变量设置为哑变量。
保存(Save…):可将中间的计算结果存储起来供以后分析,共有预测值、残差和影响强度因子三类
选项(Options…):可以选中相应选项对模型进行描述、预测和诊断,设置逐步法的进入和剔除标准等。本例选中CI for exp(B)选项
结果解释:
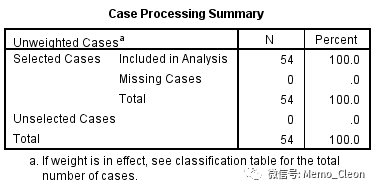
(1)数据处理情况汇总,本例共有54条记录纳入分析,无缺失值。本例样本量时偏少,要分析8个自变量至少需要160例记录,本例仅用于操作演示。
(2)因变量分类赋值

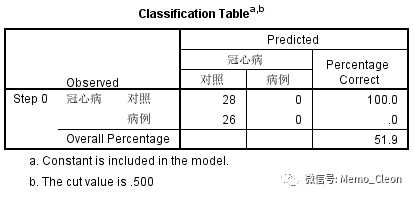
(3)预测分类表:此步开始进行拟合。Block 0拟合的是不包含任何自变量只有常数的无效模型,本例有28例对照的记录被预测为对照,有26例病例也被预测为对照,总预测准确率为51.9%,这是不纳入任何解释变量时的预测准确率,相当于比较基线。
Block 0: Beginning Block
(4)纳入方程的变量及检验情况。因此步拟合仅有常数项,β0=-0.074;检验方法Wald检验,检验统计量Wald χ2=0.074,P=0.786>0.05,H0假设是回归系数为0。Exp(B)为自然对数e的β0次方,实际意义是总体研究对象中(54例)中患病率(26/54)与未患病率(28/54)的比值0.929。
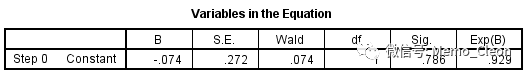
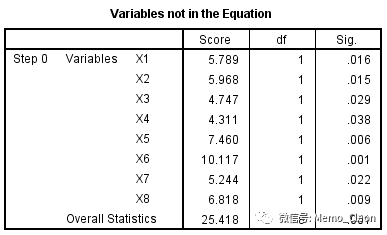
(5)尚未纳入模型方程的变量及其比分检验结果。所作的检验是分别将他们纳入方程,方程的改变是否有统计学意义。本例如果将X1-X8分别纳入方程,则方程的改变都是有统计学意义的,总的统计量也有统计学意义。逐步回归法(Stepwise)是一个一个的选入变量,下一步将会先纳入P值最小的变量X6重新计算选择。
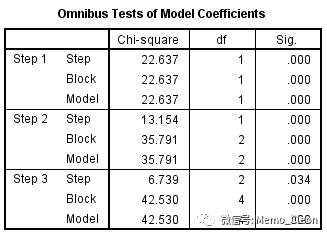
(6)模型系数的综合检验,此步开始Block 1的拟合,本例采用的方法为向前逐步选择法(似然比),本例依次引入了4个变量,结果显示每一步新引入的变量和最终的模型均有统计学意义(新引入变量系数不为零,所有引入变量系数不全为零)
Block 1: Method = Forward Stepwise (Likelihood Ratio)
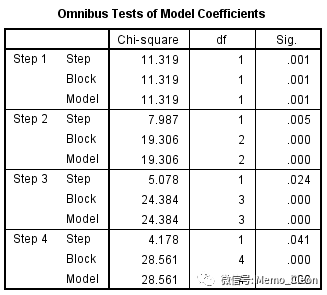
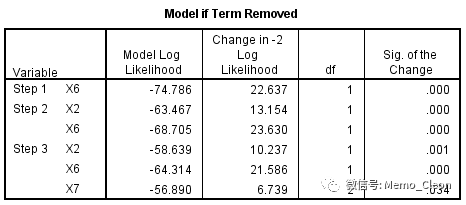
此处输出的即为每一步的似然比检验结果,模型新引入一个或几个变量后形成的新模型(当前模型)与“上一步(step)的模型/上一个区块(block)模型/初始模型(model)”进行比较,卡方值是上一个步模型/上一个区组模型/初始模型的-2logLR(负2倍的似然比值)与当前的-2logLR的差值,可通过下一张表格(Model Summary)中的值验证,step的卡方值结果上一步的模型与纳入新变量后的模型-2logLR之差,model的卡方值是初始模型(step0,各自变量系数均为0)与纳入新变量后的模型-2logLR之差,本例只设置了一个block,因此block与model相同。step检验的是每个step被纳入的变量引起的似然比变化,model则提示纳入新变量后整个模型的似然比变化。
SPSS软件中自带的帮助对几个卡方的描述如下:
Model Chi-Square
2(log-likelihood function for current model − log-likelihood function for initial model)。 The initial model contains a constant if it is in the model; otherwise, the model has no terms. The degrees of freedom for the model chi-square statistic is equal to the difference between the numbers of parameters estimated in each of the two models. If the degrees of freedom is zero, the model chi-square is not computed.
Block Chi-Square
2(log-likelihood function for current model − log-likelihood function for the final model from the previous method)。The degrees of freedom for the block chi-square statistic is equal to the difference between the numbers of parameters estimated in each of the two models.
Improvement Chi-Square
2(log-likelihood function for current model − log-likelihood function for the model from the last step)。The degrees of freedom for the improvement chi-square statistic is equal to the difference between the numbers of parameters estimated in each of the two models.
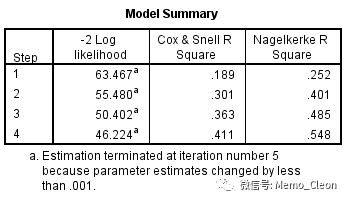
(7)模型概况,输出每一步的-2logLR(-2倍的对数似然比值)以及两个广义决定系数(也称伪决定系数),这两个指标是模型拟合效果的的判断指标。logistic模型估计一般采用最大似然法,即是得到模型的似然函数值LR达到最大值(LR取值在0-1之间)。模型预测效果越好,LR越大,-2logLR越小。Cox&Snell R2和Nagelkerke R2表示当前模型中的 自变量导致的因变量变异占因变量总变异的比例。本例在拟合过的4个模型中-2logLR逐步减小,广义决定系数在增大,模型拟合效果还是不错的。
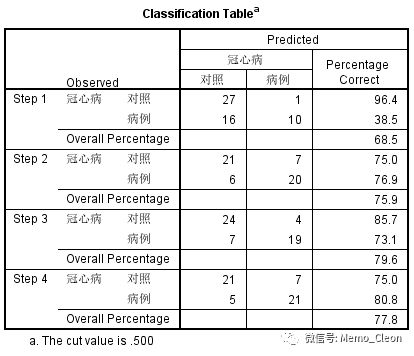
(8)每一步的预测分类表,预测准确率由Block 0的51.9%上升至77.8%。逐步回归得出的结果是保证模型的最大似然函数值最大,但不能保证此时的预测精度最高。
每一步第一行最后的百分比为真阴性率(特异度),第二行为真阳性率(灵敏度),以第四步结果为例,特异度75.0%,灵敏度80.8%。
(9)每一步拟合入选方程的变量检验情况,输出每一步模型中参数估计值,包括常数项、各自变量的回归系数及标准误、Wald卡方值、自由度、P值及OR值(Exp(B))。最后一步的入选变量作为最终结果,最终筛选出的危险因素有4个,分别是年龄(X1)、高血脂史(X5)、动物脂肪摄入(X6)、A型性格(X8),说明年龄、高血脂史、动物脂肪摄入及A型性格与冠心病呈正相关,优势比分别是2.519、4.464、23、7.008。以A型性格为例,其结果可做如下解释:不考虑其他因素的印象,A型性格的对非A型性格的人发生冠心病的优势比是7.008(一般文献中会近似的表达为:不考虑其他因素的印象,A型性格的人发生冠心病的可能是非A型性格的人发生冠心病可能的7.008倍)。对于本例年龄和体重指数,按统计结果直接表达年龄每增加10岁/体重指数每增加一级引起的优势比,但此解释应当慎重,因为我们不能确定年龄和体重指数对冠心病的影响和我们的赋值水平是一致的,严格来说此处两变量应该设置成哑变量进行分析,但由于样本量的原因本例仅做演示。哑变量的设置可参见本文后面关于哑变量的设置。
logit(P)=-4.705+0.924X1+1.496X5+3.135X6+1.947X8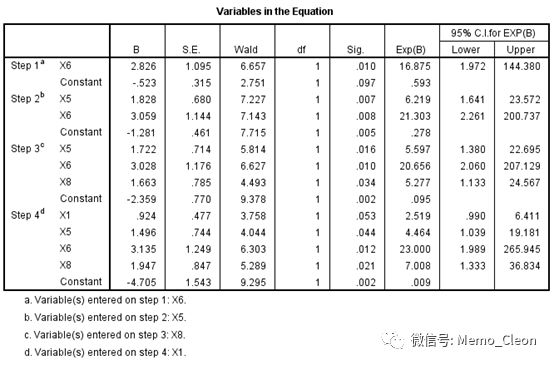
需要特别指出的是,本例X1的Wald检验P=0.053>0.05依然保留在了最终的模型中,是因为未达到变量剔除的标准,剔除检验见下一张表格:Model if Term Removed。SPSS默认的进入标准是0.05,剔除标准是0.10(可在选项(Options…)中设置),每一步P值小于等于0.1的变量均保留在方程中。
在对尚未进入模型的自变量进行分析时(结果见表(11):Variables not in the Equation),在进行到step3引入X6后,X1的比分检验结果,P=0.042<0.05,符合纳入标准,因此将其纳入方程。在进行变量剔除时(Model if Term Removed)采用的似然比检验,P=0.041<0.05,尚未达到剔除标准,因此保留在模型中。从检验方法上看,似然比检验是基于整个模型的拟合情况,比分检验一般与似然比检验类似,而Wald检验没有考虑各因素的综合作用,结果最不可靠,因此当结果出现冲突时应以似然比检验结果为准。
(10)输出每一步被纳入的自变量是否需要被剔除,采用的方法是似然比检验。结果显示每一步单独移除纳入的自变量后模型的改变均有统计学意义,因此需要全部保留在方程中。采用不同的变量筛选方法(剔除方法),该处的统计量会有差异。
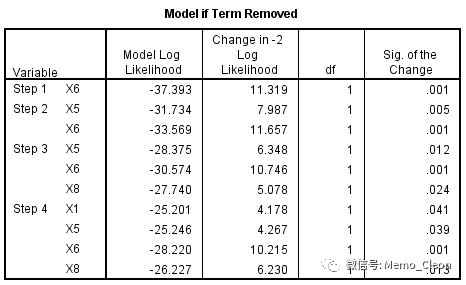
(11)尚未进入模型的自变量是否可能被纳入的比分检验结果:尚未进入方程的自变量如果再进入现有模型,模型的改变有无统计学意义。可见在Step 1时,还有多个变量可以引入,其中X5的P值最小,Step2时首先引入;在Step 2时首先考虑引入X8,Step3时首选考虑引入X1,而Step4时在现有的进入标准下已经没有需要引入的变量了。
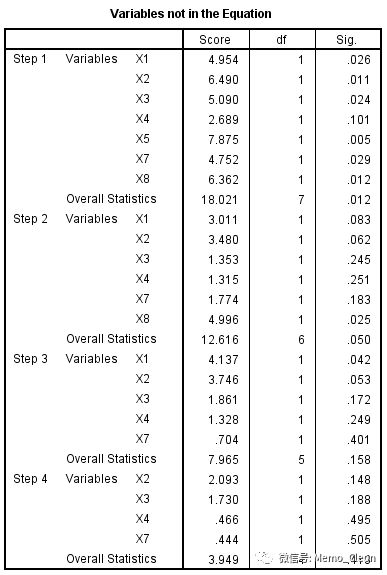
需要特别说明的是,变量是否最终入选,最重要的准则是专业判断,如在专业上认为某自变量对结果有影响,不论其检验水准如何,都可强行纳入方程。
其次为多变量分析,最差的是单变量分析。多变量模型综合考虑了各个自变量的影响,结果更为客观,如多变量模型与单变量模型出现矛盾时应以多变量分析结果为准。
【3】几个需要注意的问题
(1)样本量
越多越好。理论上讲,每个自变量所需要的事件数至少为10个,也就是研究对象中较少组的记录数与自变量个数之商大于等于10。本例有8个自变量需要分析,病例组和对照组至少各需要80例以上,总样本160例以上,如设置哑变量,自变量增多样本量要求也就更大,而且参照水平至少30例以。本例对照组只有28例,病例组只有26例,最多只能分析的自变量个数是26/10=2.6个,若要分析所有的自变量,样本量就需要增加,否则就需要减少自变量个数。本例仅演示操作。
(2)哑变量
二分类变量取值只有“0”和“1”两个值,它们分别代表两种成对出现的逻辑概念,如“是”和“否”、“有”和“无”、“高”和“低”、“真”和“假”等,spss默认取值水平高的为阳性结果。当自变量为无序多分类时,SPPS中对变量的赋值大小并不代表自变量间存在次序或者程度的差异,比如研究血型对性格的影响,对A、B、AB、O血型分别赋值1、2、3、4,并不代表性格的logit(P)会按此顺序进行线性递增或递减,此时需要设置哑变量,自变量有n个水平,需要n-1个哑变量,如上面的4个血型,则需要3个哑变量来设置。
无序多分类变量可直接设置成哑变量,对于有序多分类,则视情况而定。张文彤老师给出的解决方案是专业上不能判断不同等级的自变量对因变量的影响程度是一致的时候,需要将有序变量分别以哑变量和连续性变量引入模型,对两个模型进行似然比检验(似然比卡方值等于两模型-2logLR之差,自由度为两模型自变量个数之差),如果似然比检验无统计学意义,且各哑变量回归系数间存在相应的等级关系,则可将该自变量作为连续性变量引入模型,否则还是采用哑变量方式引入。本例年龄和体重指数均为有序多分类变量,我们不能确定冠心病的发病率logit转换值会与设定的年龄等级递增相同,体重指数不同分类之间划分切点是不等距的,直接按等距赋值为1、2、3也不太符合实际情况。上面的示例将年龄和体重指数直接引入模型进行筛选是不恰当的,严格来说这两个变量是应该采用哑变量来分析的,但本来例数太少,引入哑变量后所需样本量应该更多,如果引入哑变量分析可能会使结果误差很大。实际上本例直接引入后,就出现了年龄不再是冠心病发病的危险因素。为更好的演示哑变量的设置及解读,将原数据复制一倍,变量只保留X2、X4、X6、X7,重新进行回归分析。
分析>>回归>>二分类logistic…
因变量:选入冠心病[Y]
协变量:选入自变量[X2]、[X4]、[X6]、[X7]
筛选变量方法(Method):Forward:LR
分类变量(Categorial…):可将多分类自变量设置为哑变量,将“体重指数(BMI)[X7]”选入分类协变量(Categorial Covariats)框中,低BMI水平(BMI<24)设为参照水平,将Contrast-Indicator,Reference Category-First,Change,Continue
大部分结果解读同示例结果,以下仅结合哑变量对应的结果进行解读。
分类变量的哑变量编码见下表

拟合纳入方程的变量及其检验情况见下表。最后一步的入选变量作为最终结果,最终筛选出的危险因素有3个,分别是X2、X6、X7。对于X2的解读:不考虑其他因素的影响,有高血压病史的患者发生冠心病的可能是无高血压史患者发生冠心病可能的4.646倍(近似,实际是OR=4.646),X6的解释与此类同,高动物脂肪摄入对低脂肪摄入发生冠心病的优势比是22.042。对哑变量的解释则是与参照水平相比的结果:不考虑其他因素的影响,BMI24-26水平对BMI<24水平的优势比是3.279,BMI>26水平对BMI<24水平的优势比是4.039。
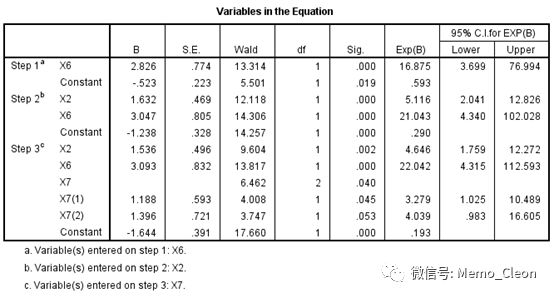
要特别注意,哑变量需要遵循同进同出的原则,即在一个模型中同一个多分类变量的所有哑变量要么全部纳入模型,要么全部不纳入模型。目前在各很多统计论坛上,普遍认为结果的第一行是该自变量的总体检验,总体检验有统计学意义,所有哑变量都应保留,本例X7总P值=0.04<0.05,X7(1):P=0.04<0.05,X7(2):P=0.53>0.05。
一般来说第一行的总体检验有统计学意义,其后的哑变量至少有一个是有统计学意义的,有时可能出现后面的哑变量都没有统计学意义的情况,因为哑变量选取不同的参照水平,其他哑变量与之相比的P值会不同,出现这种情况可能是其他哑变量与选取的参照水平相比刚好没有统计学意义。
还有一种情况是此表哑变量总检验P>0.05,结果仍保留在方程中,原因可能是不同的检验方法造成的,跟正文结果(9)后面的解释一样,纳入标准、剔除标准以及方程中变量的检验方法是不一样的,以本例为例,纳入变量方法是比分检验(默认纳入标准P=0.05),剔除标准是最大似然比检验(默认标准P=0.10),而本表方程中变量的检验采用的是Wald卡方检验。Wald与似然比检验出现矛盾时以似然比检验为准。
实际上,自变量设为哑变量后,Variables in the Equations表中直接显示的都是最终入选的变量,具体的纳入和剔除检验则需要从Variables not in the Equation和Model if Term Removed表中查看。如本例,结合上表X7在step3时被纳入,从模型系数的综合检验表格(Omnibus Tests of Model Coefficient)中可以看出,Step3与上一步的似然比检验有统计学意义,纳入该变量时模型的改变有统计学意义(Variables not in the Equation表中step2比分检验结果:P=0.033<0.05),剔除该变量时模型的改变也有统计学意义(Model if Term Removed表中step3的似然比检验结果:P=0.034<0.05)。

(3)模型效果检验
模型拟合效果可以通过对似然比值的变化和广义决定系数(Model Summary)、预测分类表(Classification Table),解读如正文。另外对模型效果的检验还有ROC曲线。
制作ROC曲线步骤如下:
分析>>回归>>二分类logistic…
- 因变量:选入冠心病[Y]
- 协变量:选入自变量[X2]、[X4]、[X6]、[X7]
- 筛选变量方法(Method):Forward:LR
- 保存(Save…):选中预测值中的概率(Probabilities)
- Continue
- OK
分析>>ROC曲线(ROC Curve…)
- 检验变量(Test Variable):选入新生产的预测概率(Predicted probability[PRE_1])
- 状态变量(State Variable):选入冠心病[Y],将Y=1的研究对象指定为病人(状态变量值(Value of State Variable):1)。
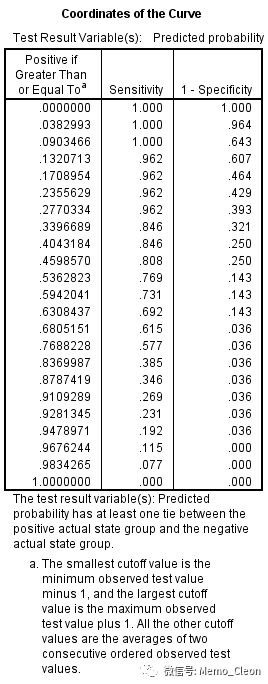
- 显示(Dispaly)选中所有复选框:ROC曲线、带对焦参考线、标准误和置信区间、ROC曲线的坐标点
- OK
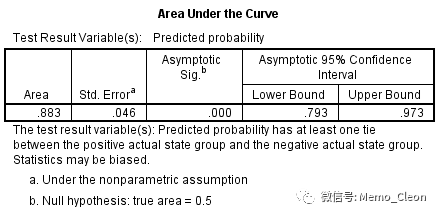
结果显示曲线下面积为0.883,P<0.001。P值的H0假设是曲线下面积为0.5。
ROC曲线下面积取值范围0.5-1,0.5-0.7表示诊断价值较低,0.7-0.9表示诊断价值中等,0.9以上表示诊断价值较高。如果ROC曲线沿着对角线方向分布. 表示分类是机遇造成的,正确和错误的概率各位50%,此时该诊断方法无效,较好的诊断方法的ROC曲线应该是从左下角垂直上升至顶线.然后水平向右至右上角,更外面离对角线更远的曲线其灵敏度和特异度均高于里面的离对角线更近的曲线。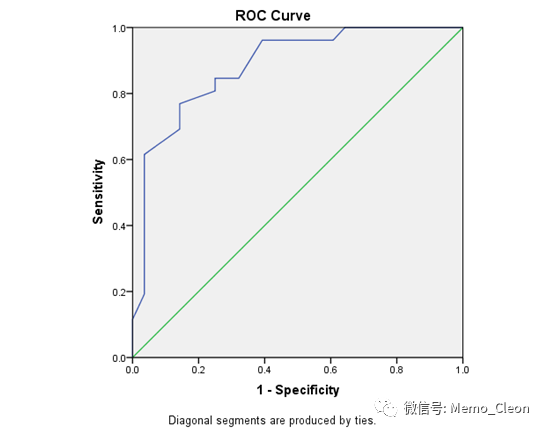
(4)模型的拟合优度的检验
可采用Pearson拟合优度检验和Deviance拟合优度检验,此两法在SPSS的二分类的logistic回归没有输出
似然比检验是 计算经筛选出的变量的饱和模型的-2logLR值和只引入筛选出的变量的主效应模型(简单模型)的-2logLR值,两者之差服从卡方分布,自由度为两者参数个数之差,若P>0.05则说明拟合筛选的自变量主效应的logistic回归模型已经足够。注:饱和模型可以理解为纳入各自变量主效应及其交互项的模型,简约模型为非饱和模型,比如缺少交互项。
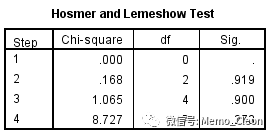
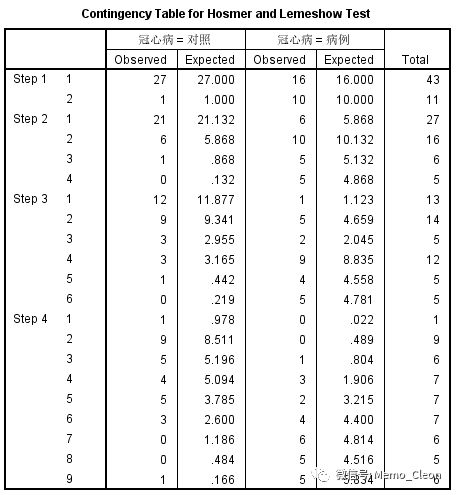
除了似然比检验外,SPSS中还有Hosmer-lemeshow检验,可在选项(Options…)中选入Hosmer-lemeshow goodness-of-fit,结果出现在“模型概况(Model Summary)”表格之后,输出“Hosmer和Lemeshow检验”以及“Hosmer和Lemeshow检验列联表”。其中Hosmer和Lemeshow检验列联表是十分位组的观测值和期望值,按模型求得某个体的得病概率,概率递增排序后分为10等份,据此期望值与相应的观测值求得Pearson卡方(自由度=组数-2=8,但有时自变量组合和样本量的原因组数可能少于10)。
本例最终结果χ2=8.727,P=0.273>0.05,表明简约模型与饱和模型间无差异(H0假设是简约模型与饱和模型无差异。如果结果显著则说明现有简约模型仍然需要加入新的变量以提升模型的解释力度;相反若结果不显著说明简约模型中包括的自变量已足够,即解释力度已与饱和模型无差异)。
(5)模型诊断
可采用残差分析、迭代记录、分类图等。
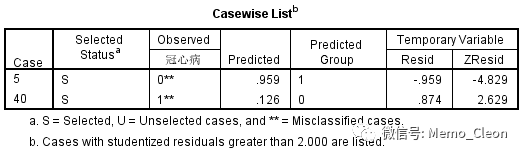
- 通过残差分析可以查找异常值,可通过保存(Save…)中的残差( Residuals)部分来进行,一般来说残差绝对值大于2,该条记录可能是异常点。残差图可参见正态分布与方差齐性的检验方法与SPSS操作部分。异常点的查找也可通过选项(Option…)中选中Casewise listing of residuals来进行,本例结果如下:第5和40条记录的的标准化残差均大于2,应根据实际情况分析是否为异常值。如确定异常值,需要删除记录后重新进行回归分析。
- 代记录在选项(Option…)中选中Iteration history来获得,健康迭代过程的迭代记录似然值和自变量系数从迭代开始就向着一个方向发展,如中间出现波折,尤其是当引入新变量后变化方向改变了,则提示要好好进一步分析。
- 分类图可以直观的观测模型的预测状况,可在选项(Option…)中选中Classification plots来获得
(6)多重共线的检验
运用相同的因变量和自变量拟合线性回归模型进行共线性诊断
分析>>回归>>线性(Linear…)
选入相应的因变量和自变量
统计(Statistics…):选中Collinearity diagnostics,Continue,OK
查看结果中的回归系数表(Coefficients),如容忍度(Tolerance)小于0.1,方差膨胀因子(VIF)大于10,则提示共线性的存在。存在共线性最简单的处理方法就是剔除引起共线性的因素。
来自外部的引用