

本次使用的数据为银行的信用好坏情况数据。自变量包括了收入水平、信用卡数量、教育水平、贷款次数,年龄。
点击分类,决策树
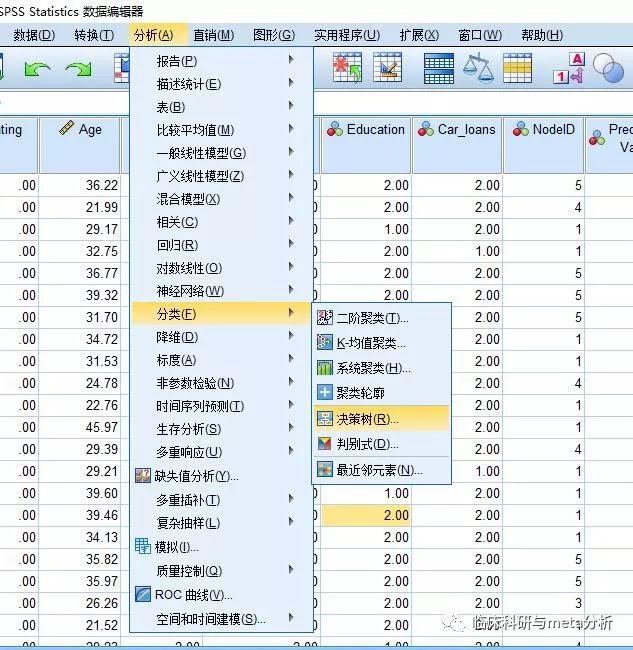
将相应变量选入应变量以及自变量。点击自变量的类别,进行勾选bad,因为我们只对信用差的感兴趣。
点击输出
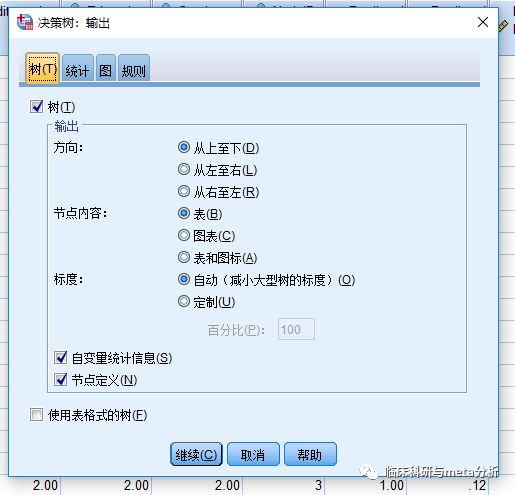
点击验证,我们选择50%的样本用于验证。
我们将收敛限制为父节点最小个案数为400,子节点为200个。
点击保存
结果
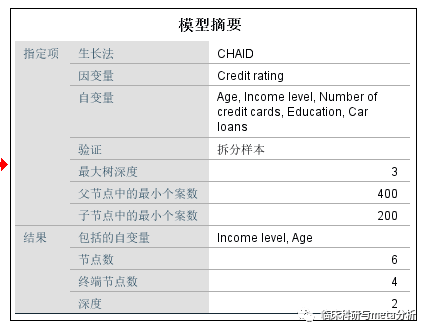
模型摘要对总体模型进行描述
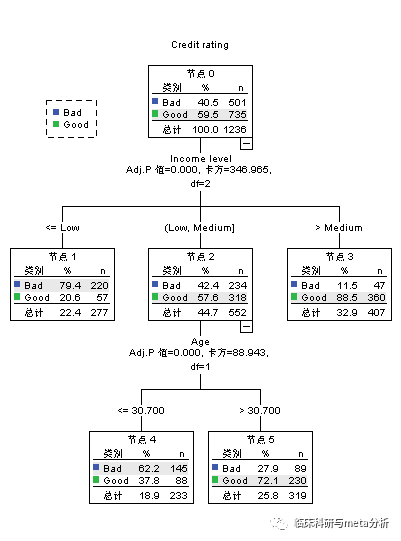
训练样本决策树
验证样本决策树
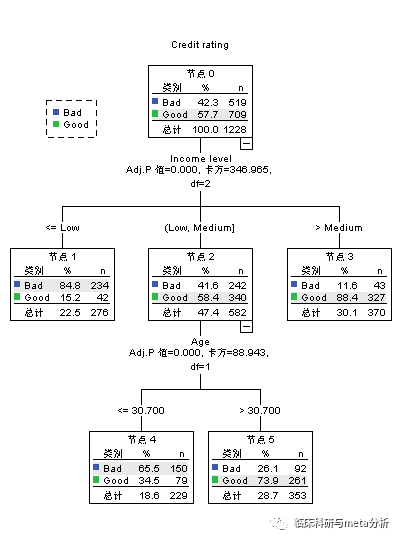
节点增益
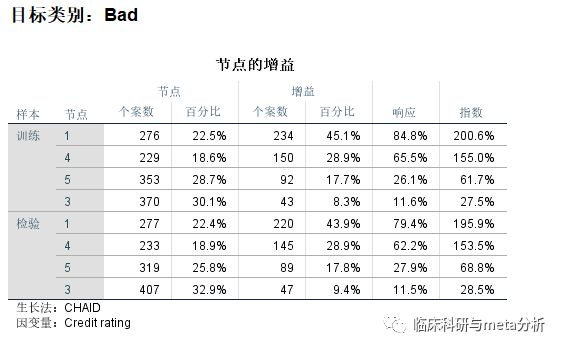
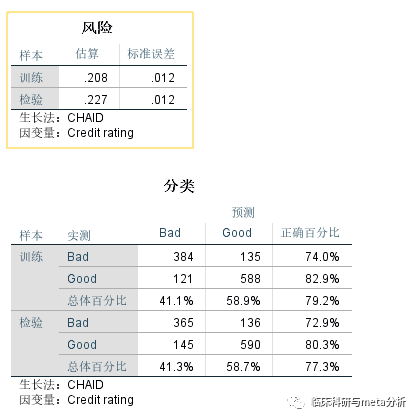
风险为误判率,分类为具体的分类情况
下面是对决策树归纳算法重要特点的总结:
(1)决策树归纳是一种构建分类模型的非参数方法。换句话说,它不要求任何先验假设,不假定类和其他属性服从一定的概率分布。
(2)找到最佳的决策树是NP完全问题。许多决策树算法都采取启发式的方法指导对假设空间的搜索。
(3)已开发的构建决策树技术不需要昂贵的计算代价,即使训练集非常大,也可以快速建立模型。此外,决策树一旦建立,位置样本分类非常快,最坏情况下的时间复杂度是O(w),其中w是树的最大深度。
(4)决策树相对容易解释,特别是小型的决策树,在很多简单的数据集上,决策树的准确率也可以与其他分类算法相媲美。
(5)决策树是学习离散值函数的典型代表。然而,它不能很好地推广到某些特定的布尔问题。一个著名的例子是奇偶函数,当奇数(偶数)个布尔属性为真时其值为0(1)。对这样的函数准确建模需要一颗具有2d个结点的满决策树,其中d是布尔属性的个数。
(6)决策树算法对于噪声的干扰具有相当好的鲁棒性,采用避免过分拟合的方法之后尤其如此。
(7)冗余属性不会对决策树的准确率造成不利的影响。一个属性如果在数据中它与另一个属性是强相关的,那么它是冗余的。在两个冗余的属性中,如果已经选择其中一个作为用于划分的属性,则另一个将被忽略。然而,如果数据集中含有很多不相关的属性(即对分类任务没有用的属性),则某些不相关属性可能在树的构造过程中偶然被选中,导致决策树过大庞大。通过在预处理阶段删除不相关属性,特征选择技术能够版主提高决策树的准确率。
(8)由于大多数的决策树算法都采用自顶向下的递归划分方法,因此沿着树向下,记录会越来越少。在叶结点,记录可能太少,对于叶结点代表的类,不能做出具有统计意义的判决,这就是所谓的数据碎片(data fragmentation)问题。解决该问题的一种可行的方法是,当样本小于某个特定阈值时停止分裂。
(9)子树可能在决策树中重复多次,如图4-19所示,这使得决策树过于复杂,并且可能更难解释。当决策树的每个内部结点都依赖单个属性测试条件时,就会出现这种情形。由于大多数的决策树算法都采用分治划分策略,因此在属性空间的不同部分可以使用相同的测试条件,从而导致子树重复问题。
(10)迄今为止,本章介绍的测试条件每次都只涉及一个属性。这样,可以将决策树的生长过程看成划分属性空间为不相交的区域的过程,直到每个区域都只包含同一类的记录。两个不同类的相邻区域之间的边界称作决策边界(decision boundary)。由于测试条件只涉及单个属性,因此决策边界是直线,即平行于“坐标轴”,这就限制了决策树对连续属性之间复杂关系建模的表达能力。
斜决策树(oblique decision tree)可以克服以上的局限,因为它允许测试条件涉及多个属性。
尽管这种技术具有更强的表达能力,并且能够产生更紧凑的决策树,但是为给定的结点找出最佳测试条件的计算可能是相当复杂的。
构造归纳(constructive induction)提供另一种将数据划分成齐次非矩形区域的方法,该方法创建符合属性,代表已有属性的算术或逻辑组合。新属性提供了更好的类区分能力,并在决策树归纳之前就增广到数据集中。与斜决策树不同,构造归纳不需要昂贵的花费,因为在构造决策树之前,它只需要一次性地确定属性的所有相关组合。相比之下,在扩展每个内部结点时,斜决策树都需要动态地确定正确的属性组合。然而,构造归纳会产生冗余的属性,因为新创建的属性是已有属性的组合。
(11)研究表明不纯性度量方法的选择对决策树算法的性能的影响很小,这是因为许多度量方法相互之间都是一致的。