

那么问题来了,当我们得到Logistic回归模型的时候,只能进行粗略的解释,而且只能分别把每个亚型和其中的同一个给定的亚型进行比较,并得到OR值。这还不是最让人郁闷的,因为如果这一X作为1个变量的时候,我们很难说清楚“亚型”这个X到底在预后(Y)的发生与否中占了多重要的位置。

2、如果我们在模型中引入了多个自变量X,以及自变量之间的交互项。结果却发现很多自变量间都存在交互作用。也就是X1*X2、X1*X4、X2*X5……这些交互项都有意义。那我们该怎么办呢?如果要进行简单效应分析的话,岂不是这些变量的组合都要被拆分成亚组,然后分别得到结论,那简直是分析灾难啊。如果用更复杂的模型,也让我们的解释变得困难。
这样苦逼的现象真的会发生,但是最惨的莫过于1和2两类事件叠加在一起
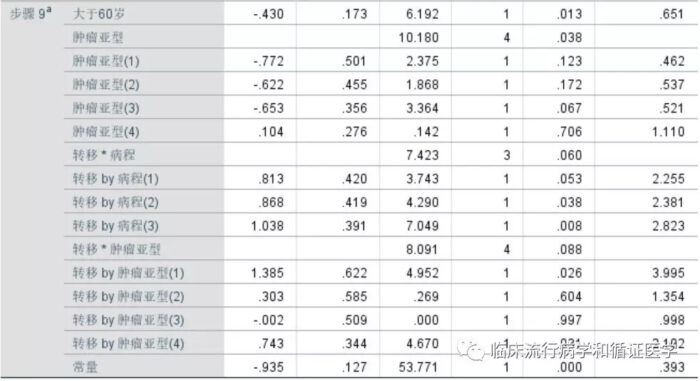
相信您拿到这样的结果,一时半会也开心不起来。我们该如何是好呢?
当然有很多好办法,不过今天我们只讲最简单粗暴,最投机取巧的办法之一。就是干脆放弃Logistic回归,改用决策树来解决这个问题。
关于决策树,让我们先抄一段百度:决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。
简单来说,决策树就是帮助我们寻找一个将对象(患者)最好区分开的路径。当然,所有被决策树留下的变量都应该是对我们区分患者有帮助的变量。于此同时,在更靠近树的根部(最先被用来进行区分)的变量也应该对患者的分类更具有价值。
对于上面那个让我们高兴不起来的阳性结果,我们抛弃Logistic回归,改用决策树分析一下试试看,瞬间结果就清新了:
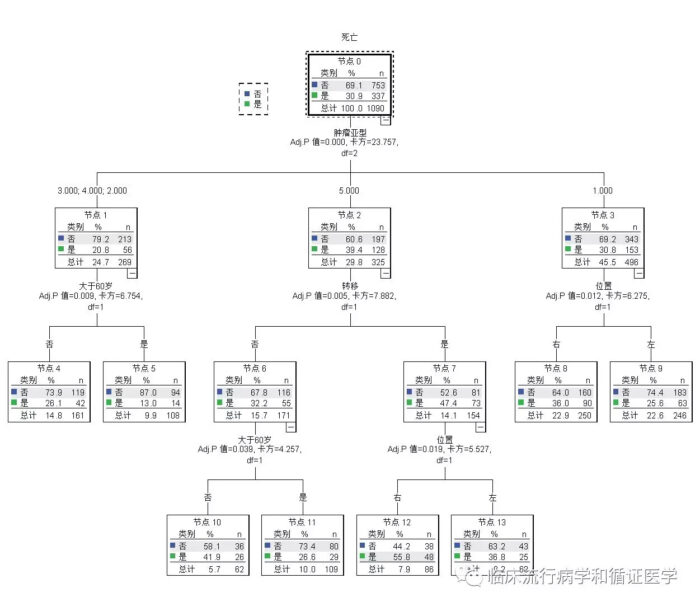
不难看出,在患者是否死亡这一结局中,最重要的因素(靠近根部的变量)是肿瘤亚型。对于2/3/4亚型,他们后续死亡风险主要受到年龄影响,而对于5亚型则主要受是否转移影响,对于1亚型主要受位置的影响。下面解释相同,也没必要再为交互而发愁了,毕竟对于根上长出来的不同树枝,后续的分类也不用按相同的路径实现。
对于上面两个让我们头疼的问题,在决策树面前都不是事。换句话说,对于存在多分类自变量,或是多个自变量间存在交互的情况下,如果Logistic回归结果过于复杂,我们不妨尝试使用决策树来得到更简洁更好解释的结果。