

在临床研究中,匹配是常用的平衡两组基线资料和混杂因素的方法。传统的匹配方法是选择几个混杂因素进行匹配,近几年发展起来的倾向评分匹配也是将多个混杂因素综合成一个混杂因素—倾向评分,用评分进行匹配,其匹配的思想都是相同的。匹配后的两组平衡性会变好,但不要以为匹配后就万事大吉了。在匹配的资料进行统计比较时,仍会发现基线不平衡的情况,原因可能与资料类型和匹配方法有关系,下面以实例进行说明。(为方便理解,以一个混杂因素为例进行说明,并假设对照组病例数多于对照组,进行1:1匹配,如遇到多个混杂因素等其它情况,可类推。)
数据A:如下散点图,横轴是分组(1组和2组),纵轴是某混杂因素值。1组样本量远小于2组,而且两组的值完全交叉,理论是能从2组找到与1组非常相近的病例,适宜进行匹配。
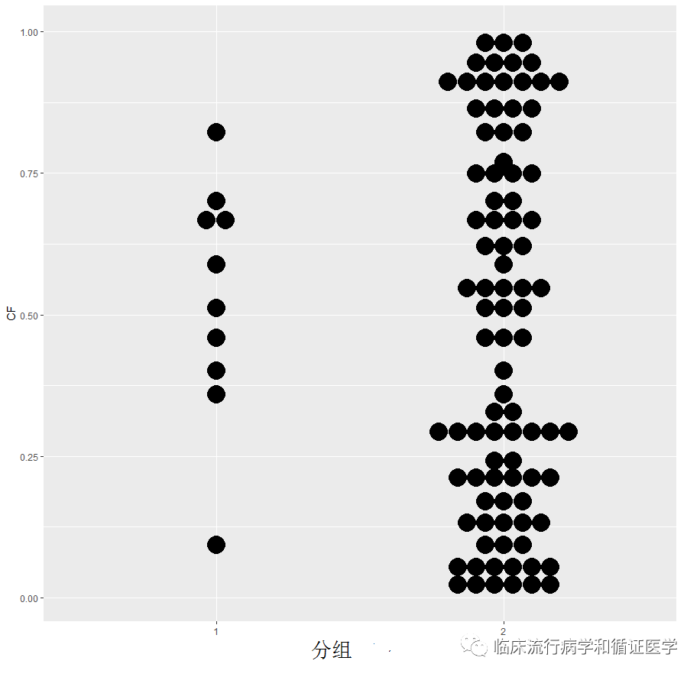
数据B:1组的资料的最小值仍高于2组资料的最大值,即两组资料没有交叉,这种情况很难找到两组能配对的资料,无论如何匹配,两组的基线仍会不平衡。
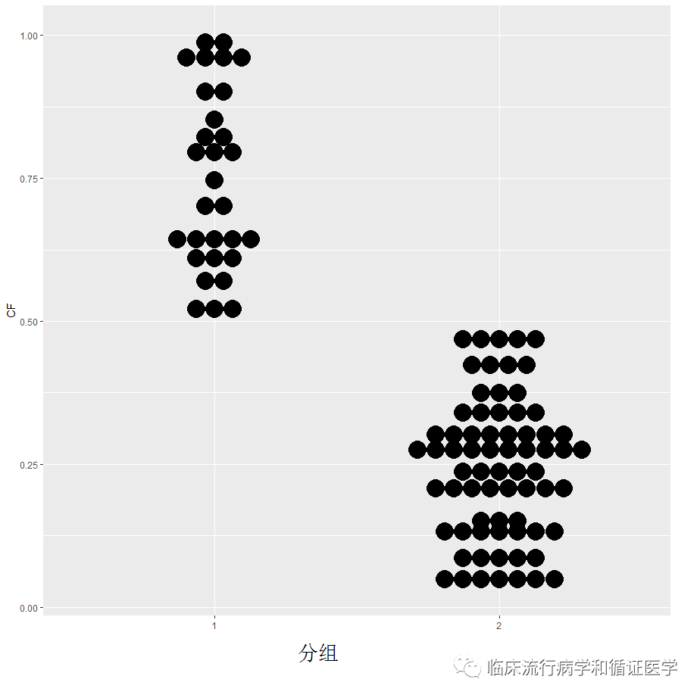
数据C:在此时两组有可以匹配的资料,但并不多,如果进行匹配,两组都有可能损失大量病例。
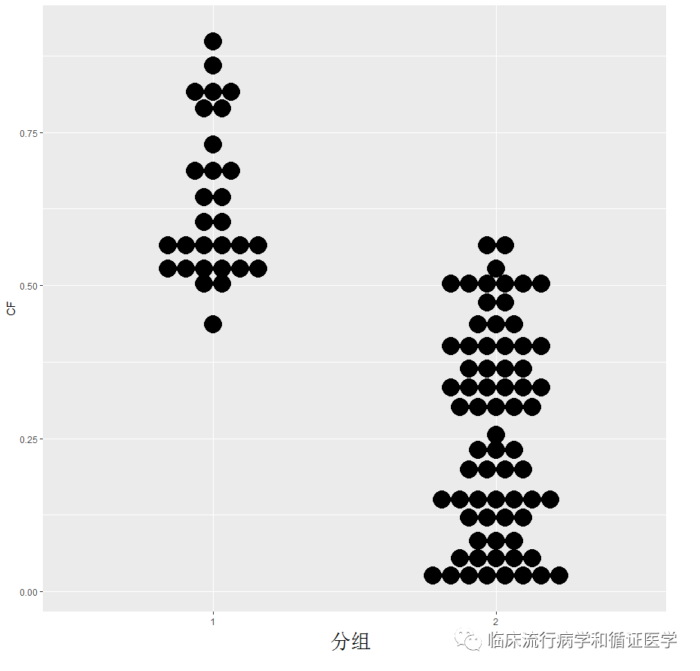
除了数据类型会影响倾向评分匹配结果,匹配方法也会影响匹配结果。较常用的两种匹配方法有最邻匹配法和卡钳匹配。
最邻匹配法,就是从对照组中为试验组中每个病例找一个最相近的病例进行匹配,这种方法对于三种资料类型都总能找到匹配对象,如下图从两条线中间进行匹配。
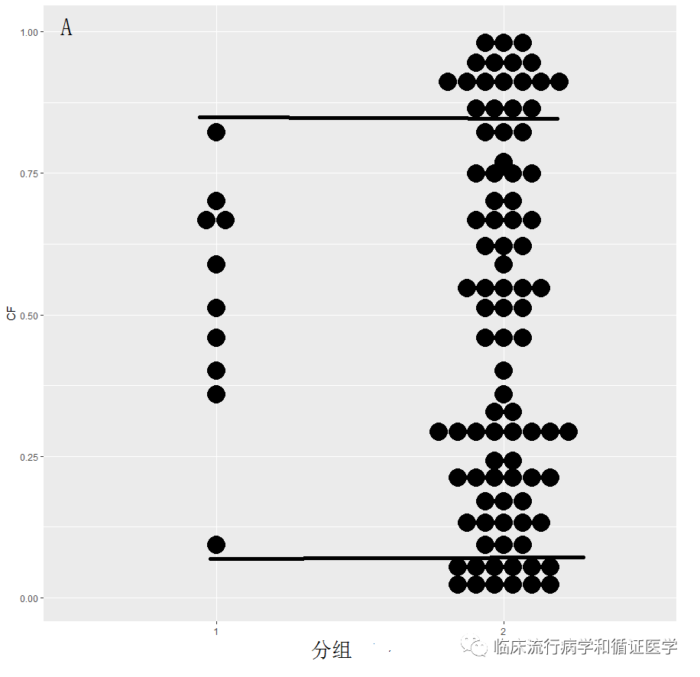
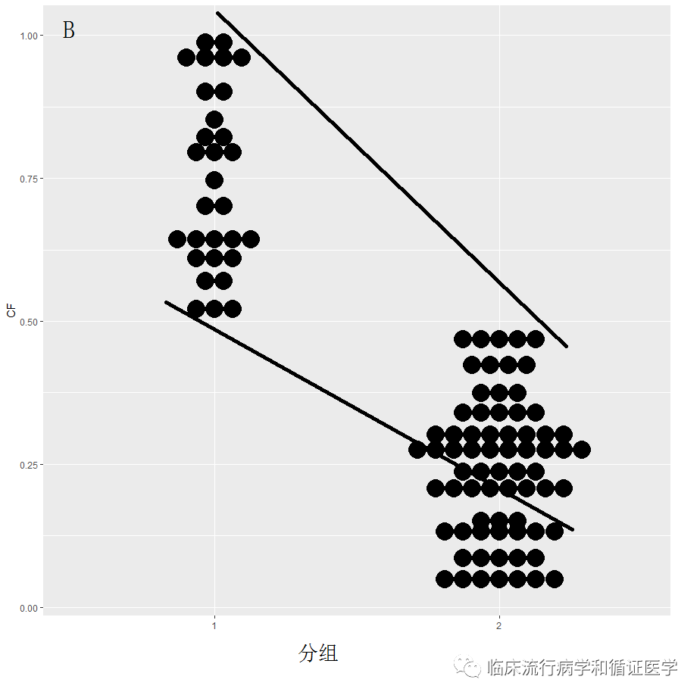
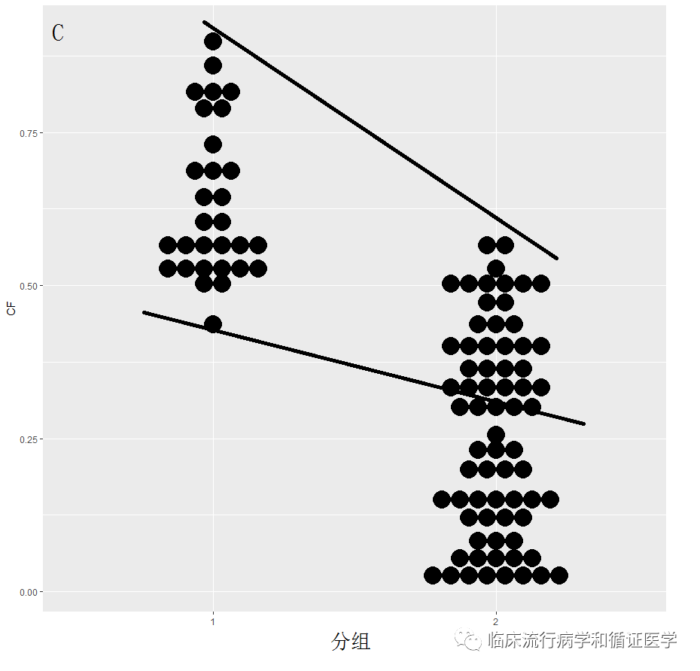
因此上述方法实验组病例不会损失,但匹配均衡性可能会受影响。数据A匹配后的结果可能较好,但数据B、C匹配后基线可能仍不平衡。本方法适用于试验组病例较少,对损失病例较敏感时使用,保证试验组病例不损失,但又可以控制一部分混杂因素的作用。
卡钳匹配:即为每个匹配对象设定一个匹配误差,在误差范围内可以成功匹配,否则不能匹配。
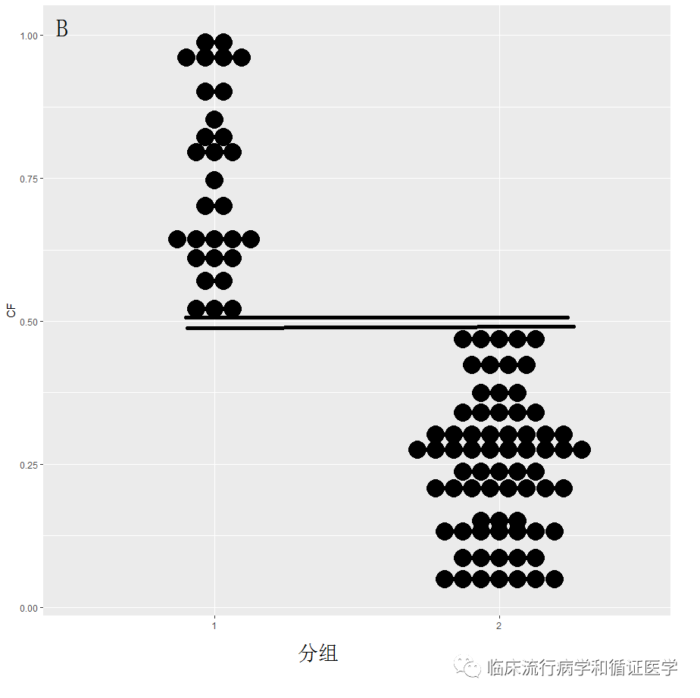
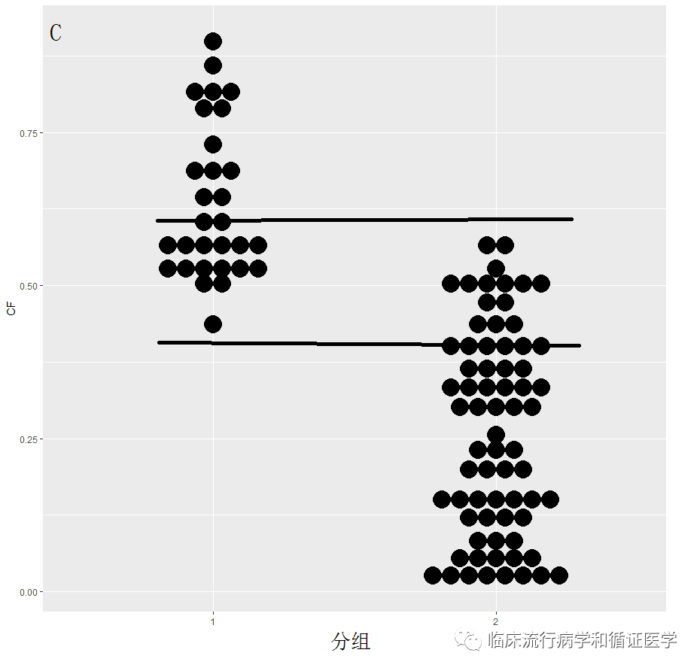
这种方法对于资料A的匹配效果与最邻匹配法相关不大,但对于资料B可能无法进行,因为无法找到合适的匹配对象,而对于资料c可能会损失大量病例,少部分病例匹配成功。适用于两组样本量都较大,对损失病例不敏感时使用。
从上面结果来看,匹配后是否均衡与数据数据类型和匹配方法都有关系。对于A类数据,两组资料完全交叉,而且对照组样本量远大于试验组,无论选用哪种方法,匹配结果都是非常好的。而对于B、C类数据,我们要根据实际需要选择相应的匹配方法。但无论何种数据和匹配方法,匹配后还是要进行均衡性检验的,如果某个混杂因素不均衡,还是要纳入多因素模型进行调整。