

半年多前写过一篇文章,关于病例-对照研究中,到底是否需要匹配对照的问题。在那篇文章中,提到了一个概念——匹配过度(overmatching),并说明了匹配过度反而会影响结果。那么匹配过度到底是什么呢?如何避免中选择对照时进入匹配过度的怪圈呢?
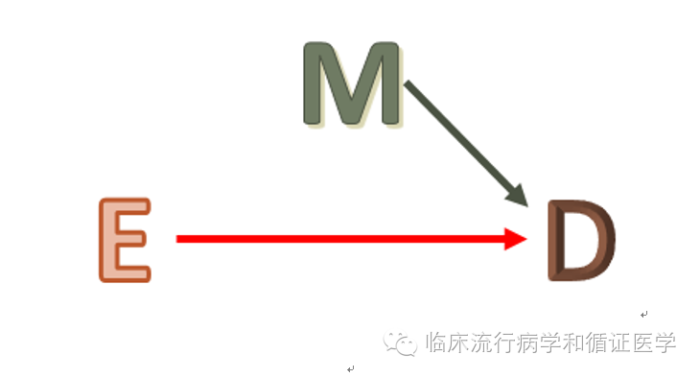
匹配过度(over matching)的定义是,针对不必要的匹配因素进行匹配,企图使病例和对照尽量一致,则可能丢失信息,增加工作难度,结果反而降低研究效率。我们知道,匹配是提高研究效率的有效方法。比如,我们会中研究队列中构建一个巢式病例-对照设计(Nested case-control study),我们会针对病例组的某些特征去匹配对照组,避免那些我们已知的,目前研究中不关心的因素影响我们的结果,这个过程我们叫匹配。由于匹配可以使病例组合对照组在匹配因素上一致,提高了组间可比性,也减少了我们在研究中多因素分析时自变量的数量,从而达到提高研究效能的目标。
就像这张图一样,当我们这次研究关心的E因素和匹配的M因素都可能导致研究结局D时,控制了M以后(对M进行匹配),同样的样本量能有更大的把握检验出E和D的关系,也就是提高检验效能(power)。
但在研究中,可能存在其他情况,E、M、D的关系可能更扑簌迷离。比如这个图:
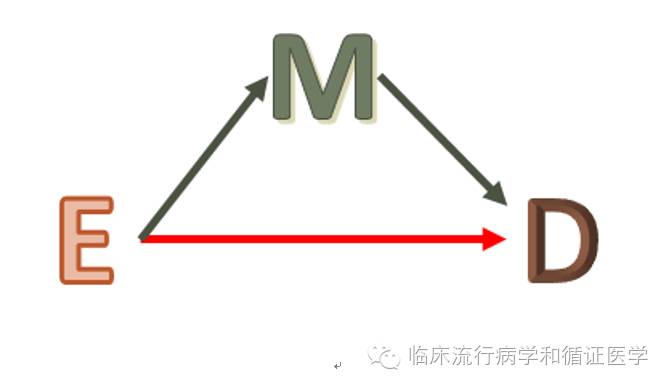
E会导致D,M也会导致D的发生,而且E可以通过M来导致D的发生。这时,如果我们匹配了M因素,则会把E→M这条通路切断,那么我们获得的E和D的关系则不是E对D影响的全部了,可能仅仅了能得到E对D影响的部分效应而已。比如,研究运动和代谢综合症之间的关系时,选择了有代谢综合症的患者作为病例组,没有代谢综合症者作为对照,如果我们根据病例组的BMI来匹配选择对照的话,很可能就会发生上图的问题。也许,运动量和代谢综合症的发生有直接关系,而运动又可能通过控制BMI来影响代谢综合症的发生。在这项研究中,我们匹配了BMI那么我们仅仅能发现运动量和代谢综合症直接效应这部分的关联,而无法分析它通过改变BMI水平对代谢综合症的影响。
我们再来看一种更为极端的情况:
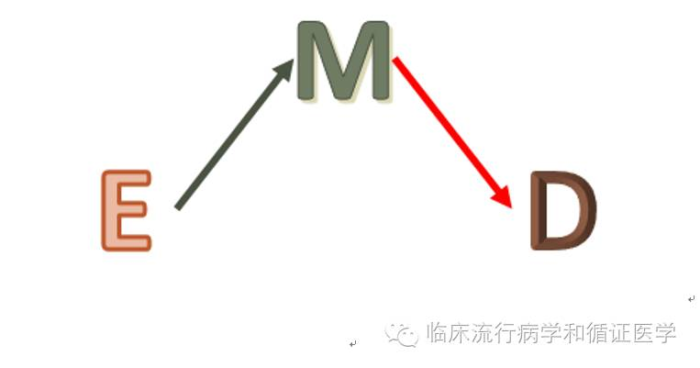
虽然E与D有关联,但是是通过E影响M,M在影响D来起作用的。在流行病学中,我们把这种情况下M这个因素叫做E→D之间的中间环节。这个时候,如果我们匹配了病例组和对照组中的M因素,那会发现E和D无关。比如,研究盐的摄入量与急性心肌梗塞的关系,选择急性心梗的患者作为病例组,选择没有心梗者作为对照,并根据病例组的年龄、性别、是否患高血压进行1:1匹配。咱们聪明的读者肯定会发现,盐的摄入量,很可能是通过影响高血压的发生再引起心梗的,也就是说,这里E是盐的摄入量,M是高血压,D是心梗。这三者的关系,符合我们上面图中所描绘的情况。由于我们在这个研究中匹配了高血压的因素,那么很可能会获得一个阴性的结果。也就是盐摄入和心梗无关。但事实呢?其实盐的摄入是会提高心梗发生的风险,只是途径被我们人为的掐断了。看到这儿,可能还会有人存在疑问,如果说,高血压是高食盐摄入导致心梗的中间环节,说明心梗的真正病因是高血压而不是食盐摄入量,因此,这么匹配没错。可是,我们的研究有时并不需要得知真正的病因,有时仅仅是希望发现可以控制的危险因素。回到这个例子,如果我们没有对高血压这个因素进行匹配,我们很可能会得到高盐的摄入是心梗的危险因素之一。那么从制定卫生政策上,我们可以通过健康教育或人群干预来减少盐的摄入,从而达到减少心梗疾病负担的目标。
从上面几个图我们知道了,虽然匹配可以达到提高研究效率的目标,但是匹配有时也是一把双刃剑,匹配还是不匹配需要考虑匹配因素和研究的暴露因素及结局之间的关系,再行决定。