

问题与数据
以下是胃癌真菌病因研究中3种食物样品的真菌检出率,比较3个检出率有无差异。
表1 物种食物样品的真菌检出率
对数据结构的分析
本例是独立四格表χ2检验的拓展,由两个分组增加到多个分组,分析思路与四格表χ2检验类同,需要注意的是,这里我们不光想知道多个分组间有无差异,如果差异存在统计学意义,那么具体到组间两两比较是否均存在差异。
SPSS分析方法
多个独立样本列联表χ2检验的SPSS操作与四格表一样,需要注意的是,不同于四格表χ2检验,SPSS对于R*C列联表χ2检验不会自动输出Fisher确切概率检验结果,如果样本例数较少,建议在Exact设置中勾选Exact(如下图)。
结果解读
表2 统计汇总
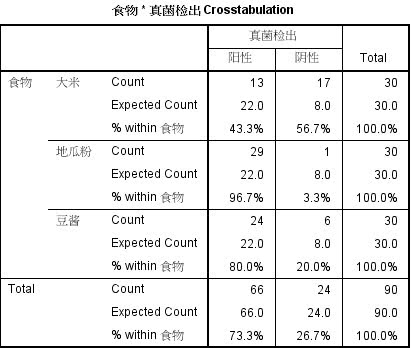
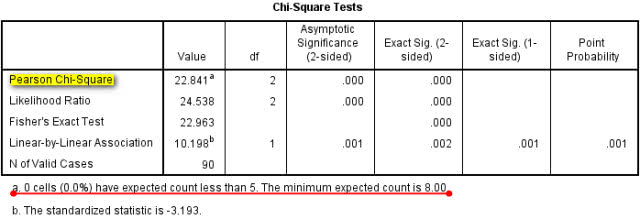
表3 卡方检验结果
多个独立样本列联表χ2检验的结果选择:
1. 所有理论频数≥5,看Pearson Chi-Square的结果;
2. 超过20%的理论频数Fisher’s Exact Test结果(也可以考虑增加样本量或者依据专业判断适当合并行或列,再进行χ2检验)。
本例中SPSS提示没有理论频数小于5,且最小的理论频数为8.00,故直接选择Pearson Chi-Square结果,即χ2=22.841,P
组间的两两比较
通过上述χ2检验,明确了三种食物的真菌检出率并不相同,此时我们还需要进一步考虑三种食物真菌检出率到底谁与谁之间的差异存在统计学意义,这里就需要用到“卡方分割”,通俗讲就是把R*C列联表拆分成若干个四个表分别进行χ2检验,进而判断不同组两两比较差异是否用统计学意义,但是,因为多组比较可能会增加犯I类错误概率,所以还需要对χ2检验的P值进行校正,这里主要介绍 Bonferroni校正。
本例中需要进行3次两两比较,校正的检验水准α=0.05/比较次数=0.05/3=0.0167。
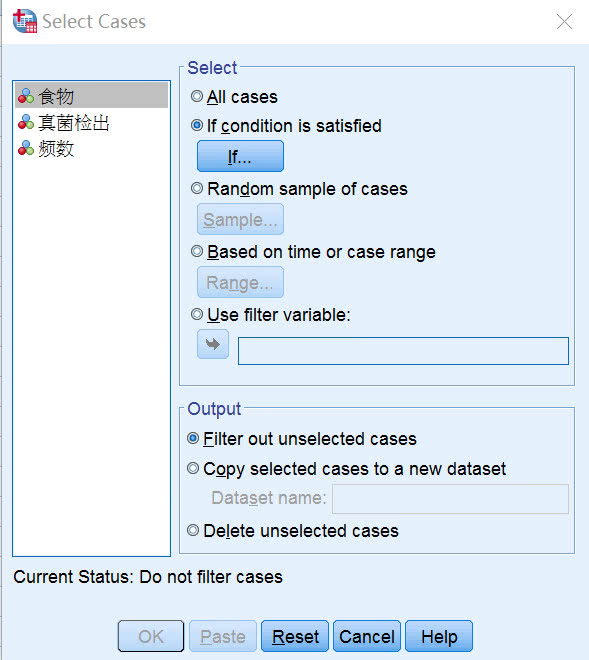
到这里,有的小伙伴要问了,SPSS数据库中原来有3组,怎么才能方便地构造任意两组的“四格表”,进行χ2检验呢?这里教大家一个SPSS中比较实用的小技巧——选择特定对象进行统计分析。
A.菜单的Data中找到Select Cases
B.Select Cases中提供了多种用于选择研究对象的方式 ,这里我们将用到条件筛选(如下图)
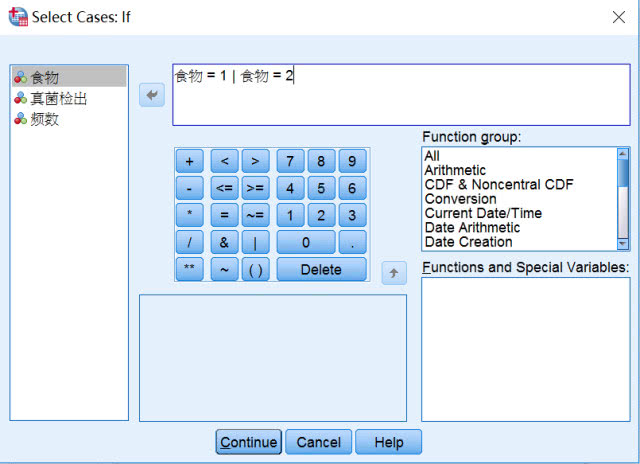
C.条件筛选中提供了丰富的筛选公式,假如想选择1-大米和2-地瓜粉,可以做如下图设置,“食物=1|食物=2”,这里“|”代表“或者”,即数据库只要有1或者2都会被选中进行统计分析→Continue。
按照上面介绍的小技巧,我们就可以进行任意两组的四格表χ2检验(表4)
表4. 不同食物真菌检出率比较
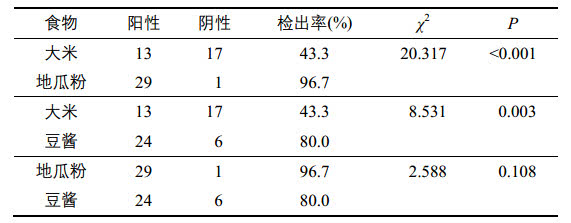
如上表,按照校正的检验水准α=0.0167,大米和地瓜粉,大米和豆酱之间的真菌检出率差异具有统计学意义,而地瓜粉和豆酱之间差异无统计学意义。
撰写结论
大米、地瓜粉和豆酱的真菌检出率并不相同(χ2=22.841,PPP>0.0167)。
PS:多个独立样本的χ2检验除了包含上述R*2列联表卡方检验外,还包含R*C卡方检验,即我们考虑的指标变量为多分类(例如血型),其统计分析思路和SPSS操作分析与R*2列联表卡方检验一致,这里不再赘述。