

简介
近年来NLP领域最让人印象深刻的成果,无疑是以谷歌提出的Bert为代表的预训练模型了。它们不断地刷新记录(无论是任务指标上,还是算力需求上),在很多任务上已经能超越人类平均水平,还具有非常良好的可迁移性,以及一定程度的可解释性。
例如,当我们需要在论文里解释为什么算法或者改动能够work的时候,一张基于attention的热力图显然更容易说明我们的代码究竟做到了什么。
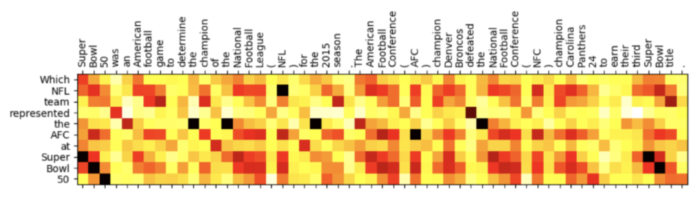
图1 一种论文中常见的attention热力图
而目前主流的预训练模型,都是以17年谷歌提出的Transformer模型作为基础进行修改,作为自己的特征抽取器。可以说,Transformer自从出现以来就彻底改变了深度学习领域,特别是NLP领域。
本文主要介绍了Transformer以及其在近年来的一些优化变种。
Transformer
如果用一句话来介绍Transformer,那就是:“首个完全抛弃RNN的recurrence,CNN的convolution,仅用attention来做特征抽取的模型。”也就是论文标题所写的,《Attention Is All You Need》。
Attention机制在NLP领域的应用最早可以追朔到2014年,Bengio团队将Attention引入NMT(神经机器翻译)任务。但那时Attention仅仅是作为一项外挂结构,模型的核心构架还是RNN。而到了Transformer则完全地以Attention机制作为模型的基础构架,抛弃了之前的CNN和RNN的网络。
Transformer的基本构架如下图所示,其中,左半边是Encoder部分,右半边是Decoder部分。Transformer有6层这样的结构。
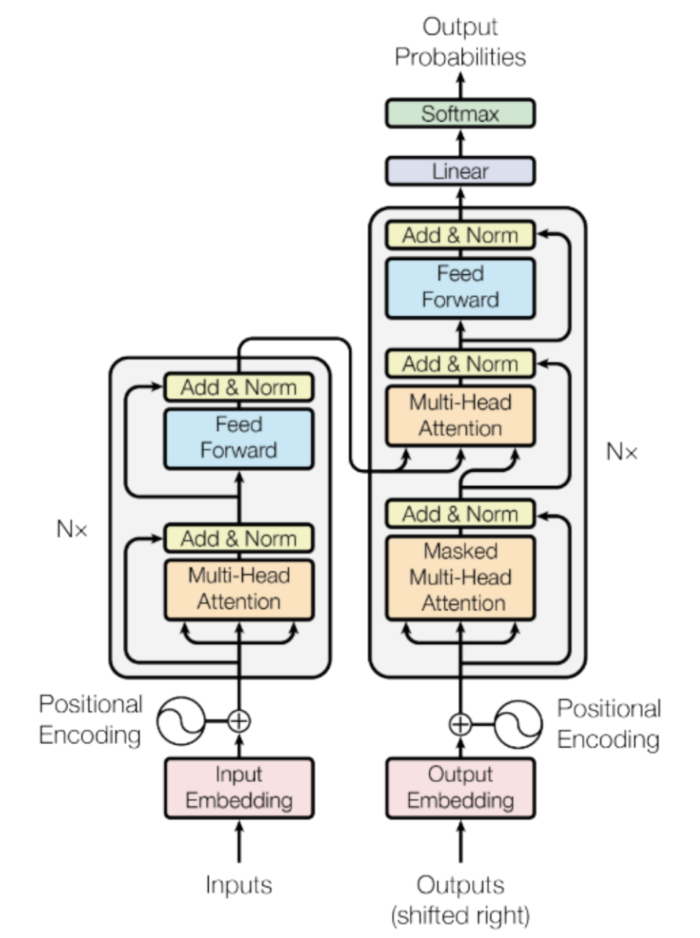 图2 Transformer详细构架
图2 Transformer详细构架
以翻译模型为例给出Transformer的总的结构图:
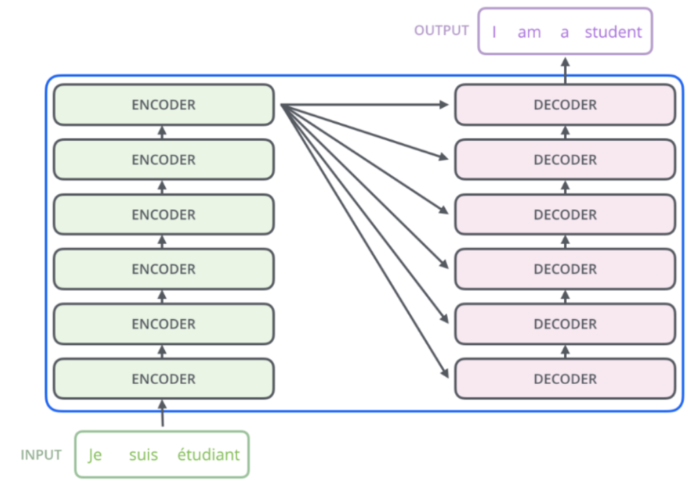 图3 Transformer整体构架
图3 Transformer整体构架
以上是对Transformer的整体介绍,下面将对Transformer各个创新之处进行讲解。
Attention
Transformer中一共使用了三次Attention。其中Decoder部分多一层比较特殊的Masked Attention。即在解码时,模型应当只知道当前中心词的上文,因此通过masking的方式,屏蔽中心词下文的内容,保持了自回归的特性。
Scaled Dot-Product Attention
Self-Attention本质上是通过为当前词引入其上下文的信息,以增强对当前词的表示,写入更多的信息。这点基本类似于2014年,Bengio团队将Attention引入NMT(神经机器翻译)。
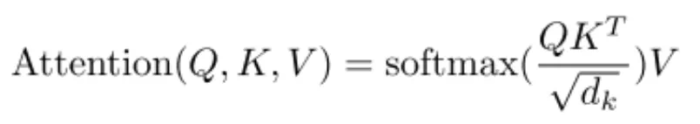 在Transformer中,这部分是通过Attention(Q, K, V)实现的。其中Q是query,K是key,V是value。通过Q和K的点积的结果来体现上下文词分别对中心词的影响程度,再通过softmax进行归一化。
在Transformer中,这部分是通过Attention(Q, K, V)实现的。其中Q是query,K是key,V是value。通过Q和K的点积的结果来体现上下文词分别对中心词的影响程度,再通过softmax进行归一化。
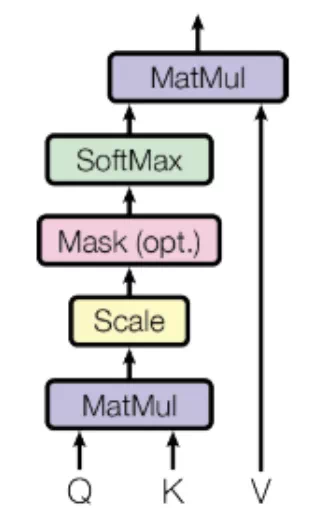 图4 Attention计算路径
图4 Attention计算路径
Multi-Head Attention
Multi-Head Attention基本是完全创新之处。
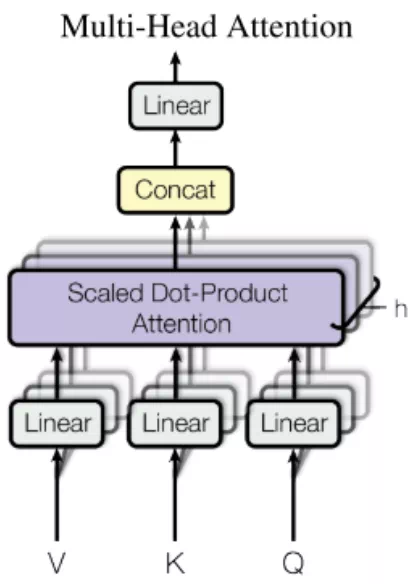 图5 Multi-Head Attention计算路径
图5 Multi-Head Attention计算路径
其会将原本512维的Q、K、V,通过8次不同的线性投影,得到8组低维的Qi、Ki、Vi,其维度均为64维。公式如下:

这样做由于每个注意力头的大小都相应地缩小了,实际上计算量并没有显著增加。
关于为什么使用多头注意力,而不是单头注意力,《Attention Is All You Need》作者认为:平均注意力加权降低了有效的分辨率,即它不能充分体现来自不同表示子空间的信息。而使用多头注意力机制有点类似于CNN中同一卷积层内使用多个卷积核的思想。可以增强模型对于文本在不同子空间中体现出的不同的特性,避免了平均池化对这种特性的抑制。
但是关于多头注意力机制是不是有用,为什么有用,目前还没有一个很好的解释。
有大量的研究表明,以Transformer为基础的Bert的特定层是有其独特的功能的,底层更偏向于关注语法,顶层更偏向于关注语义。既然在同一层Transformer关注的方面是相同的,那么对该层而言,不同的头关注点应该也是一样的。这就和作者的解释有些矛盾。
实际上,在《A Multiscale Visualization of Attention in the Transformer Model》这篇文章中,作者分析了前几层BERT的部分注意力头,如下图所示,结果显示,同一层中,总有那么一两个头关注的点和其他的头不太一样,但是剩下的头也相对趋同【考虑到同一层的注意力头都是独立训练的,这点就很神奇】。
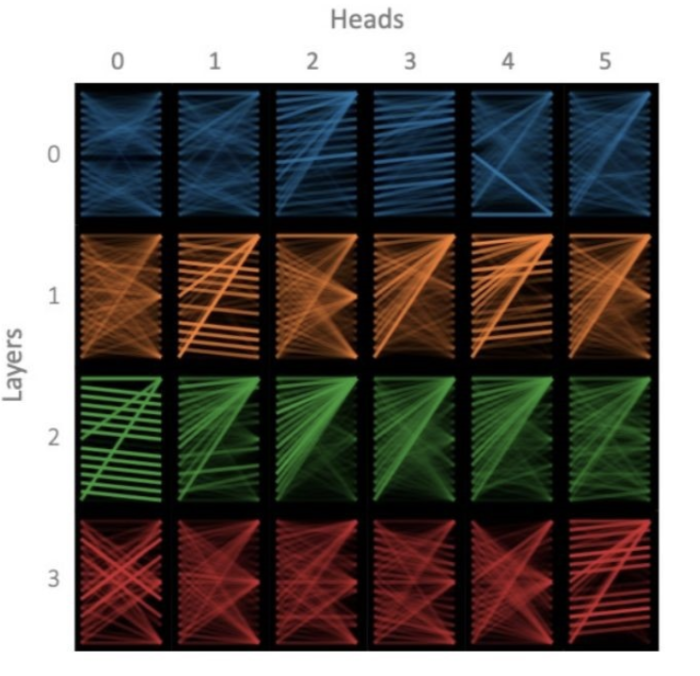 图6 Bert的0-3层中,第0-5的head对于同样的输入所关注的内容。 而在《What Does BERT Look At? An Analysis of BERT’s Attention》一文中,作者分析了,同一层中,不同的头之间的差距,以及这个差距是否会随层数变化而变化。结果如下图所示,似乎可以粗略地得出结论,头之间的差距随着所在层数变大而减少,即层数越高,头越趋同。但遗憾的是,这个现象的原因目前没有比较好的解释。
图6 Bert的0-3层中,第0-5的head对于同样的输入所关注的内容。 而在《What Does BERT Look At? An Analysis of BERT’s Attention》一文中,作者分析了,同一层中,不同的头之间的差距,以及这个差距是否会随层数变化而变化。结果如下图所示,似乎可以粗略地得出结论,头之间的差距随着所在层数变大而减少,即层数越高,头越趋同。但遗憾的是,这个现象的原因目前没有比较好的解释。
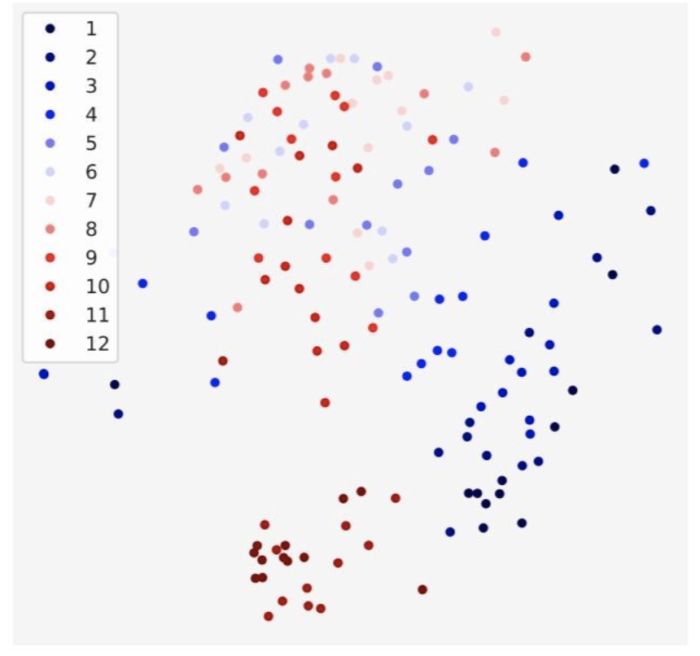 图7 对于Bert中,每一层的head之间的差异在二维平面上的投影 就我个人观点,多头注意力机制的作用可能是这样:注意力机制的冗余性很高(即使是独立计算的注意力头,大概率关注的点还是一致的),所以那些仅有很少部分的相对离群的注意力头,能够使得模型进一步优化。但是这些离群的头出现的概率并不高,因此需要通过提高头的基数,来保证这些离群头的出现频率。
图7 对于Bert中,每一层的head之间的差异在二维平面上的投影 就我个人观点,多头注意力机制的作用可能是这样:注意力机制的冗余性很高(即使是独立计算的注意力头,大概率关注的点还是一致的),所以那些仅有很少部分的相对离群的注意力头,能够使得模型进一步优化。但是这些离群的头出现的概率并不高,因此需要通过提高头的基数,来保证这些离群头的出现频率。
Positional Encoding
由于Attention机制并不会告诉模型,词与词之间的位置关系(这点和RNN、CNN不同),需要额外引入位置信息编码。
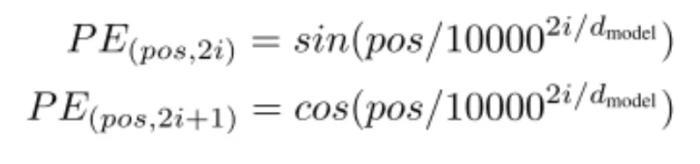
使用上述位置编码的理由很简单,因为它能够很好的编码两个词之间的相对位置关系。三角函数有着非常方便的和差化积公式。
作者还提到了可以使用Learned embedding,但是实验表明两种方法效果上并没有差别,但使用公式方法更为简单,可以处理比训练时更长的序列。
缺点
Transformer从现在看来也存在着一些缺点和不足:
非图灵完备:证明略过不表。通俗来说,就是Transformer不能处理所有问题。例如,当我们需要输出直接复制输入时,Transformer并不能很好地学习到这个操作。
不适合处理超长序列:当针对文章处理时,序列的长度很容易就超过512。而如果选择不断增大模型的维度,训练时计算资源的需求会平方级增大,难以承受。因此一般选择将文本直接进行截断,而不考虑其自然文本的分割(例如标点符号等),使得文本的长距离依赖建模质量下降。
计算资源分配对于不同的单词都是相同的:在Encoder的过程中,所有的输入token都具有相同的计算量。但是在句子中,有些单词相对会更重要一些,而有些单词并没有太多意义。为这些单词都赋予相同的计算资源显然是一种浪费。
原始版的Transformer虽然并不成熟,层数固定不够灵活、算力需求过大导致的不适合处理超长序列等缺陷限制了其实际应用前景。但是其优秀的特征抽取能力吸引了很多学者的关注。很多人提出了不同的变种Transformer来改进或者规避它的缺陷。其中,Universal Transformer、Transformer-XL、Reformer就是典型的代表。
Universal Transformer
从构架来看,Universal Transformer和Transformer并没有太大的区别,这里就不详细解读了,主要谈谈其最大的创新之处。
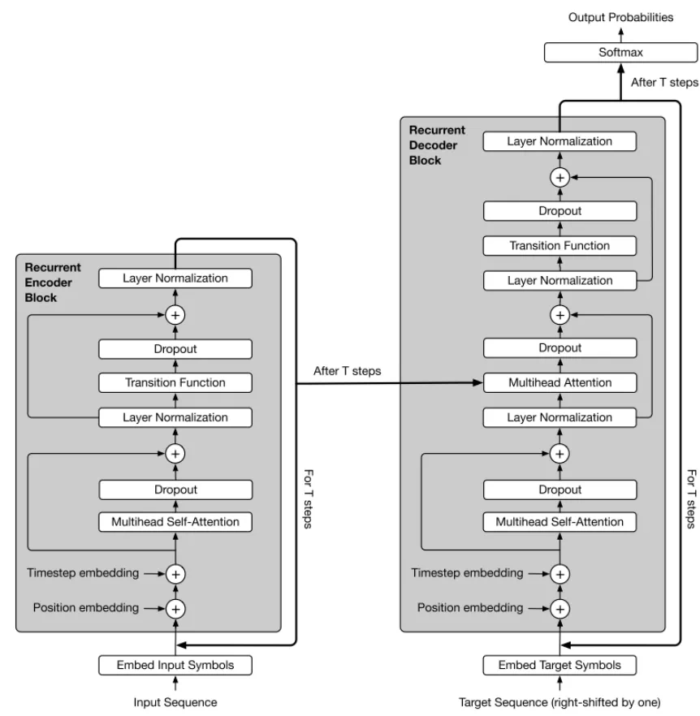 图8 Universal Transformer模型架构 在Transformer中,输入经过Attention后,会进入全连接层进行运算,而Universal Transformer模型则会进入一个共享权重的transition function继续循环计算
图8 Universal Transformer模型架构 在Transformer中,输入经过Attention后,会进入全连接层进行运算,而Universal Transformer模型则会进入一个共享权重的transition function继续循环计算
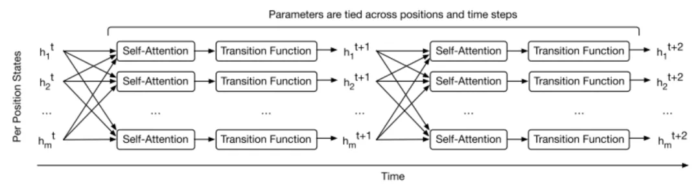 图9 Universal Transformer重新启用了循环机制 其中,纵向看是文本的序列顺序,横向看是时间步骤。其中每一步的计算公式如下:
图9 Universal Transformer重新启用了循环机制 其中,纵向看是文本的序列顺序,横向看是时间步骤。其中每一步的计算公式如下:
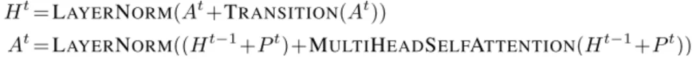
这里Transition function可以和之前一样是全连接层,也可以是其他函数层。
之前Transformer的位置编码因为因为层数是固定的,所以不需要将层数编码进去。大师Universal Transforer模型多了一个时间维度,因此每一次循环都需要进行一轮坐标编码,公式为:
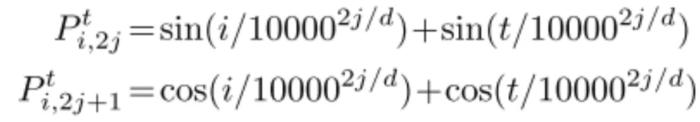
为了控制循环的次数,模型引入了Adaptive Computation Time(ACT)机制。
ACT可以调整计算步数,加入ACT机制的Universal transformer被称为Adaptive universal transformer。以下图为例,可以看出,引入ACT机制后,模型对于文本中更重要的token会进行更多次数的循环,而对于相对不重要的单词会减少计算资源的投入。
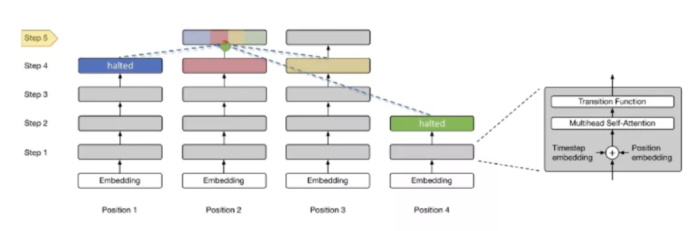 图10 Universal Transformer模型会对重要的token投入更多的资源 Universal Transformer对transformer的缺点进行了改进,解决了Transformer非图灵完备的缺点,和计算资源投入平均的问题。
图10 Universal Transformer模型会对重要的token投入更多的资源 Universal Transformer对transformer的缺点进行了改进,解决了Transformer非图灵完备的缺点,和计算资源投入平均的问题。
Transformer-XL

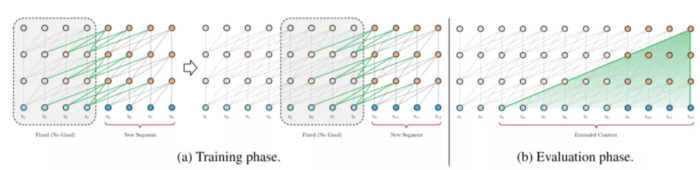 图11 Transformer-XL中,节点能够“看到”之前的segment中的内容
图11 Transformer-XL中,节点能够“看到”之前的segment中的内容 
从图中可以看出,在当前segment中,第n层的每个隐向量的计算,都是利用下一层中包括当前位置在内的,连续前L个长度的隐向量。这也就意味着,每一个位置的隐向量,除了自己的位置,都跟下一层中前(L-1)个位置的token存在依赖关系,而且每往下走一层,依赖关系长度会增加(L-1)。所以最长的依赖关系长度是N(L-1),N是模型中layer的数量。在对长文本进行计算的时候,可以缓存上一个segment的隐向量的结果,不必重复计算,大幅提高计算效率。
由于考虑了之前的segment,那么先前的位置编码就不足以区分不同segment之间的相同位置的token,因此作者提出了使用Relative Positional Encodeing来替代之前的位置编码。具体来说,就是使用相对位置编码来替代绝对位置编码。这种做法在思想上是很容易理解的,因为在处理序列时,一个token在其中的绝对位置并不重要,我们需要的仅仅是在计算attention时两个token的相对位置。由于这部分工作起到的作用主要是补丁,这里不再展开说。
总结来看。Transformer-XL在没有大幅度提高算力需求的情况下,一定程度上解决了长距离依赖问题。
Reformer

作者还考虑到有一定的概率相似的向量会被分到不同的桶里,因此采用了多轮hashing来降低这个概率。
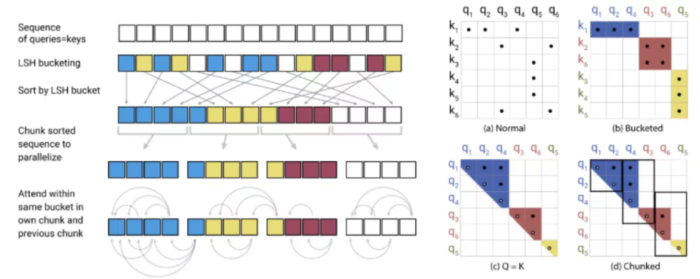 图12 Reformer模型预先使用了hashing筛选,类似桶排序,避免了对QK的计算
图12 Reformer模型预先使用了hashing筛选,类似桶排序,避免了对QK的计算
LSH解决了计算速度的问题,但仍有一个内存消耗的问题。一个单层网络通常需要占用GB级别的内存,但是当我们训练一个多层模型时,需要保存每一层的激活值和隐变量,以便在反向传播时使用。这极大地提高了内存的占用量。
这里作者借鉴了RevNet的思想,不保留中间残差连接部分的输入了,取而代之的,是应用一种“可逆层”的思路,就如同下图中所示的那样,(a)为前向传播,(b)为反向传播。
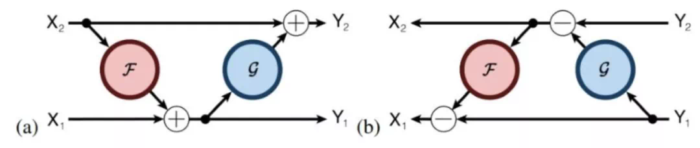 图13 Reformer中的反向传播时,每一层的输入可以根据其输出计算出来 可逆层对每个层有两组激活。一个遵循正常的标准过程,并从一个层逐步更新到下一个层,但是另一个只捕获对第一个层的更改。因此,要反向运行网络,只需减去应用于每个层的激活。
图13 Reformer中的反向传播时,每一层的输入可以根据其输出计算出来 可逆层对每个层有两组激活。一个遵循正常的标准过程,并从一个层逐步更新到下一个层,但是另一个只捕获对第一个层的更改。因此,要反向运行网络,只需减去应用于每个层的激活。
这意味着不需要缓存任何激活来计算后向传播。类似于使用梯度检查点,虽然仍然需要做一些冗余计算,但由于每一层的输入都可以很容易地从它的输出中构造出来,内存使用不再随网络中层数的增加而增加。
总结来看,Reformer在减少了attention计算量的情况下,还减少了模型的内存占用,为未来大型预训练模型的落地奠定了基础。
总结
本文主要介绍了Transformer模型以及针对其缺点作出改进的一些变种模型,总结了它们的设计思路和优缺点。未来,以Transformer及其改进版为基础特征抽取器的预训练模型,一定能够在自然语言处理领域取得更大的突破。
参考文献
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Advances in neural information processing systems. 2017: 5998-6008.
[2] Dehghani M, Gouws S, Vinyals O, et al. Universal transformers[J]. arXiv preprint arXiv:1807.03819, 2018.
[3] Dai Z, Yang Z, Yang Y, et al. Transformer-xl: Attentive language models beyond a fixed-length context[J]. arXiv preprint arXiv:1901.02860, 2019.
[4] Kitaev N, Kaiser Ł, Levskaya A. Reformer: The Efficient Transformer[J]. arXiv preprint arXiv:2001.04451, 2020.
[5] Vig J. A multiscale visualization of attention in the transformer model[J]. arXiv preprint arXiv:1906.05714, 2019.
[6] Clark K, Khandelwal U, Levy O, et al. What does bert look at? an analysis of bert's attention[J]. arXiv preprint arXiv:1906.04341, 2019.