

backbone:主干网络,用来提取特征,常用Resnet、VGG等
head:获取网络输出,利用提取特征做出预测
neck:放在backbone和head之间,进一步提升特征的多样性及鲁棒性
bottleneck:瓶颈,通常指网络输入输出数据维度不同,通常输出维度比输入维度小很多
GAP:Global Average Pool全局平均池化,将某个通道的特征取平均值
Warm up:小的学习率先训练几个epoch,这是因为网络的参数是随机初始化的,一开始就采用较大的学习率容易数值不稳定
一、数据增强方式
- random erase
- CutOut
- MixUp
- CutMix
- 色彩、对比度增强
- 旋转、裁剪

解决数据不均衡:
- Focal loss
- hard negative example mining
- OHEM
- S-OHEM
- GHM(较大关注easy和正常hard样本,较少关注outliners)
- PISA

二、常用backbone
- VGG
- ResNet(ResNet18,50,100)
- ResNeXt
- DenseNet
- SqueezeNet
- Darknet(Darknet19,53)
- MobileNet
- ShuffleNet
- DetNet
- DetNAS
- SpineNet
- EfficientNet(EfficientNet-B0/B7)
- CSPResNeXt50
- CSPDarknet53
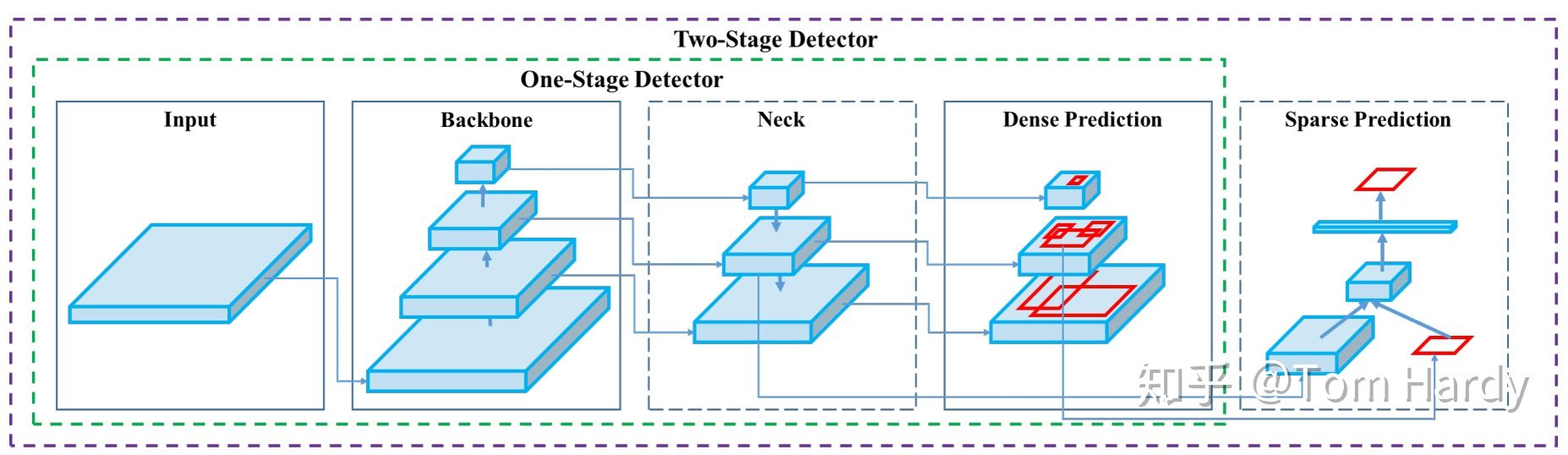
三、常用Head
Dense Prediction (one-stage):
- RPN
- SSD
- YOLO
- RetinaNet
- (anchor based)
- CornerNet
- CenterNet
- MatrixNet
- FCOS(anchor free)
Sparse Prediction (two-stage):
- Faster R-CNN
- R-FCN
- Mask RCNN (anchor based)
- RepPoints(anchor free)
四、常用neck
Additional blocks:
- SPP
- ASPP
- RFB
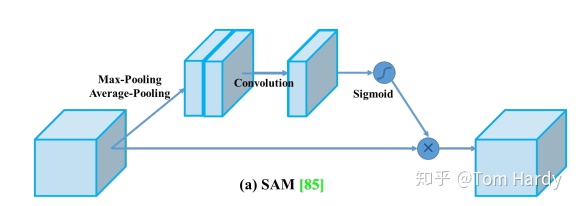
- SAM
Path-aggregation blocks:
- FPN
- PAN
- NAS-FPN
- Fully-connected FPN
- BiFPN
- ASFF
- SFAM
- NAS-FPN
五、Skip-connections
- Residual connections
- Weighted residual connections
- Multi-input weighted residual connections
- Cross stage partial connections (CSP)
六、常用激活函数和loss
激活函数:
- ReLU
- LReLU
- PReLU
- ReLU6
- Scaled Exponential Linear Unit (SELU)
- Swish
- hard-Swish
- Mish
loss:
- MSE
- Smooth L1
- Balanced L1
- KL Loss
- GHM loss
- IoU Loss
- Bounded IoU Loss
- GIoU Loss
- CIoU Loss
- DIoU Loss
七、正则化和BN方式
正则化:
- DropOut
- DropPath
- Spatial DropOut
- DropBlock
BN:
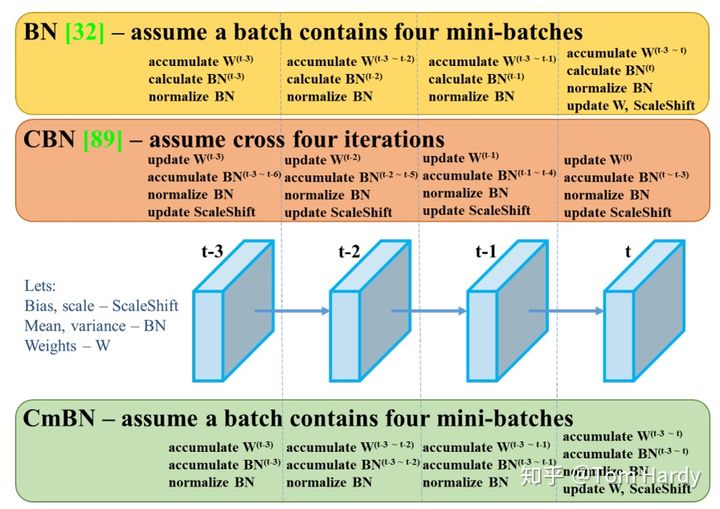
- Batch Normalization (BN)
- Cross-GPU Batch Normalization (CGBN or SyncBN)
- Filter Response Normalization (FRN)
- Cross-Iteration Batch Normalization (CBN)
八、训练技巧
- Label Smoothing
- Warm Up