

首先说说GATK可以做什么。它主要用于从sequencing 数据中进行variant calling,包括SNP、INDEL。比如现在风行的exome sequencing找variant,一般通过BWA+GATK的pipeline进行数据分析。
要run GATK,首先得了解它的网站(http://www.broadinstitute.org/gatk/)。
一.准备工作
(1)程序下载
http://www.broadinstitute.org/gatk/download
务必下载最新版,注意不是那个GATK-lite,而是GATK2.(目前是2,不知何时会更新到3.更新很快啊有木有,所以一定要用新版)解压到某个目录即可,无需安装。打开解压缩后的目录,会发现GenomeAnalysisTK.jar这个文件。我们要用的各种工具都在这个包里。
(2)Reference sequence和annotation下载
务必使用GATK resource bundle上各种序列和注释来run GATK。
GATK resource bundle介绍:
http://gatkforums.broadinstitute.org/discussion/1213/whats-in-the-resource-bundle-and-how-can-i-get-it
GATK resource bundle FTP地址:
http://gatkforums.broadinstitute.org/discussion/1215/how-can-i-access-the-gsa-public-ftp-server
例如呢,以hg19(human genome build 19.此外,b37也很常用)为参考序列,
输入如下命令: lftp ftp.broadinstitute.org -u gsapubftp-anonymous
回车后键入空格,便可进入resource bundle。进入其中名为bundle的目录,找到最新版的hg19目录。
要下载的文件包括:
ucsc.hg19.fasta
ucsc.hg19.fasta.fai
1000G_omni2.5.hg19.vcf
1000G_omni2.5.hg19.vcf.idx
1000G_phase1.indels.hg19.vcf
1000G_phase1.indels.hg19.vcf.idx
dbsnp_137.hg19.vcf
dbsnp_137.hg19.vcf.idx
hapmap_3.3.hg19.vcf
hapmap_3.3.hg19.vcf.idx
Mills_and_1000G_gold_standard.indels.hg19.vcf
Mills_and_1000G_gold_standard.indels.hg19.vcf.idx
(3)R 设置
GATK某些步骤需要使用R画一些图,此时会调用一些R packages。如果你使用的R没有装这些packages,就无法生成pdf文件。因此得安装一些必要的R packages,包括(但不限于)如下:
- bitops
- caTools
- colorspace
- gdata
- ggplot2
- gplots
- gtools
- RColorBrewer
- reshape
- gsalib
如何check这些packages有没有安装?以ggplot2为例,进入R,输入library(ggplot2),如果没有error信息,就表明安装了ggplot2;如果没有安装,输入命令install.packages("ggplot2"),按照提示操作便可安装ggplot2。如果package安装不成功,很可能是权限问题:默认使用的R是系统管理员安装的,而你在/usr等目录下没有write权限。这是可以选择直接在自己目录下安装了R,然后install各种packages。也可以在 install.packages时指定将packages安装到自己的目录。
将R packages安装到自己目录的方法:
- install.packages("ggplot2", lib="/your/own/R-packages/")
然后将指定的路径添加到R_LIBS变量即可。
gsalib的安装有点不一样。
从该网站下载gsalib:https://github.com/broadgsa/gatk
解压缩后,进入build.xml文件所在的目录,输入命令ant gsalib。这样就可以安装gsalib 了。如果该gsalib仍然无法load,可能需要将gsllib的path告诉R。
http://gatkforums.broadinstitute.org/discussion/1244/what-is-a-gatkreport
这里有较详细的步骤。(奇怪的是我没有~/.Rprofle文件,ant完后也没有add path,仍然work了)
此外,gaslib安装要求java的版本为1.6。
设置路径:
- export R_HOME=/your/R/install/path
- export R_LIBS=/your/R-packages/path
如何查看当前使用的R的路径?输入 which R即可。
二.流程概览
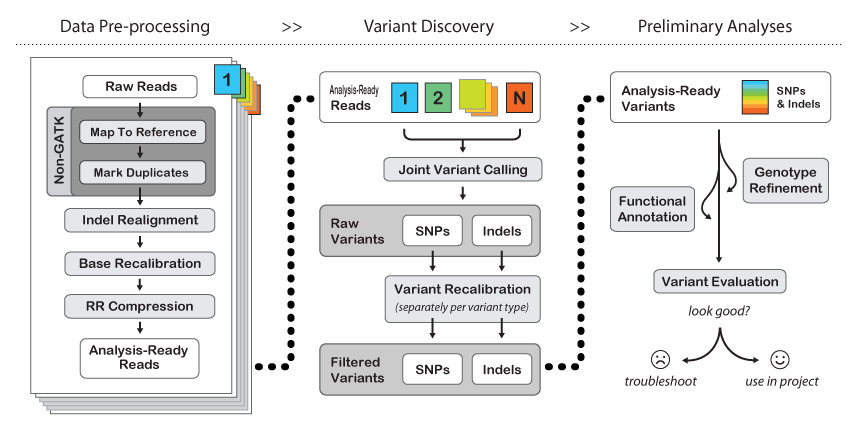
图片摘自http://www.broadinstitute.org/gatk/guide/topic?name=best-practices。话说这个Best practices,刚开始接触GATK时每个人都推荐我看,可是我就是看不懂...许多东西要亲自做过后,再回头看才能懂。不过既然那么元老级人物都说要看看,所以如果你是新手,还是看看吧。
好消息是现在该页面多了个BroadE Workshop的东东,里面的一些材料非常有用。http://www.broadinstitute.org/gatk/guide/events?id=2038#materials
在工作之前,最好把这些work materials通览一遍。
seqanswers上的这个wiki也是很好的入门材料,可以让你看看每一步在做什么。
http://seqanswers.com/wiki/How-to/exome_analysis
但是呢,它比较过时了,它使用的GATK版本应该是2.0以前的,现在的流程有了一些调整,一些参数设置也有变化。所以该pipeline仅供参考,切勿照抄代码。例如它关于reference sequence的那一部分,是自己手动generate hg19的genome sequence。但是,由于后面要用到dbSNP和indel的各种annotation,而这些file的index很可能和自己generate的hg19的index不一样(resource bundle上hg19除了chr1-22,X,Y,chrC,ChrM外还会多出一些没有组装的序列),这样会导致程序出错,到时候还得重头来过。所以,务必使用GATK resource bundle上的东西!
我后面贴出的代码也一样,切勿照抄。鬼知道过几个月GATK又会有什么变化。It keeps changing all the time...时刻跟上GATK网站上的update才是王道。(虽然它的网站做得...实在算不上好...好多时候我都找不到自己想要的东西)
三.流程
(1)Mapping。
因我只处理过Miseq和Hiseq的pair-end数据,以此为例。Mapping多使用BWA,因为它能允许indels。另一常用mapping软件Bowtie则不能generate indels,多用于perfect match的场合如sRNA mapping。
首先建立reference的index。
- bwa index -a bwtsw -p hg19 hg19.fasta
这个过程耗时良久...above 5h吧。
-p是给reference起的名字。完成后会生成如下几个文件:
hg19.amb
hg19.ann
hg19.bwt
hg19.dict
hg19.pac
hg19.sa
然后是mapping喽,开始贴代码...先对pair-end数据的pair1和pair2分别进行mapping,生成相应的sai file,然后再结合两者生成sam file。接着利用picard对sam file进行sort,并且生成sort后的bam file。
- sample=$1
- data_dir=***
- work_dir=***
- ref_dir=~/database/hg19
- sai_dir=$work_dir/saifiles
- sam_dir=$work_dir/samfiles
- bam_dir=$work_dir/bamfiles
- log_dir=$work_dir/logs
- met_dir=$work_dir/metrics
- other_dir=$work_dir/otherfiles
- gatk=/software/sequencing/GenomeAnalysisTK-2.3-4-g57ea19f/GenomeAnalysisTK.jar
- picard=/software/sequencing/picard_latest
- bwa aln $ref_dir/hg19 -t 4 $data_dir/${sample}_1.fastq.gz > $sai_dir/${sample}_1.sai
- bwa aln $ref_dir/hg19 -t 4 $data_dir/${sample}_2.fastq.gz > $sai_dir/${sample}_2.sai
- bwa sampe -r "@RG\tID:$sample\tLB:$sample\tSM:$sample\tPL:ILLUMINA" $ref_dir/hg19 $sai_dir/${sample}_1.sai $sai_dir/${sample}_2.sai $data_dir/${sample}_1.fastq.gz $data_dir/${sample}_2.fastq.gz | gzip > $sam_dir/$sample.sam.gz
- java -Xmx10g -Djava.io.tmpdir=/tmp \
- -jar $picard/SortSam.jar \
- INPUT=$sam_dir/$sample.sam.gz \
- OUTPUT=$bam_dir/$sample.bam \
- SORT_ORDER=coordinate\
- VALIDATION_STRINGENCY=LENIENT \
- CREATE_INDEX=true
Tips:
a. bwa以及后面使用的一系列tools都能直接读取gzip压缩文件。为了节省硬盘空间,以及减少压缩/解压缩过程的read/write时间,最好直接用*.gz文件作为input。output也最好先在管道里使用gzip压缩一下再输出。
b.bwa sample一步里的-r选项不可忽略。
c.Picard的SortSam需指定一个tmp目录,用于存放中间文件,中间文件会很大,above 10G.注意指定目录的空间大小。
d.对于压缩后大小约3G的fastq.gz文件,bwa aln需run 30-60min。将生成的两个sai file merge到一起生成sam file需60-90min。利用picard sort sam需30-60min。
e.Samtools也提供了工具进行sam file的sort和bam file的生成,并且不会生成大的中间文件。
(2) Duplicate marking。
这一步的目的是mark那些PCR的duplicate。由于PCR有biases,有的序列在会被overpresented, 它们有着相同的序列和一致的map位置,对GATK的work会造成影响。这一步给这些序列设置一个flag以标志它们,方便GATK的识别。还可以设置 REMOVE_DUPLICATES=true 来丢弃duplicated序列,不过还未探索过只标记不丢弃和丢弃对于后续分析的影响。官方流程里只用标记就好。
- java -Xmx15g
- -Djava.io.tmpdir=/tmp \
- -jar $picard/MarkDuplicates.jar \
- INPUT= $bam_dir/$sample.bam \
- OUTPUT= $bam_dir/$sample.dedupped.bam \
- METRICS_FILE= $met_dir/$sample.dedupped.metrics \
- CREATE_INDEX=true \
- VALIDATION_STRINGENCY=LENIENT
(3)Local relignment
INDEL附近的alignment通常不准,需要利用已知的indel信息进行realignment,分两步,第一步进行 RealignerTargetCreator,输出一个包含着possible indels的文件。第一步IndelRealigner,利用此文件进行realign。
第一步需要用到一些已知的indel信息。那么该使用哪些文件呢?
参考如下的链接:http://gatkforums.broadinstitute.org/discussion/1247/what-should-i-use-as-known-variantssites-for-running-tool-x
其中这张图表尤其有用,可以看到RealignerTargetCreator和IndelRealigner步骤中推荐使用两个indel注释file,如代码中-known所示。
| Tool | dbSNP 129 | dbSNP >132 | Mills indels | 1KG indels | HapMap | Omni |
| RealignerTargetCreator | X | X | ||||
| IndelRealigner | X | X | ||||
| BaseRecalibrator | X | X | X | |||
| (UnifiedGenotyper/ HaplotypeCaller) | X | |||||
| VariantRecalibrator | X | X | X | X | ||
| VariantEval | X |
- java -Xmx15g -jar $gatk \
- -T RealignerTargetCreator \
- -R $ref_dir/hg19.fasta \
- -o $other_dir/$sample.realigner.intervals \
- -I $bam_dir/$sample.dedupped.bam \
- -known $ref_dir/1000G_phase1.indels.hg19.vcf \
- -known $ref_dir/Mills_and_1000G_gold_standard.indels.hg19.vcf
- java -Xmx15g -jar $gatk \
- -T IndelRealigner \
- -R $ref_dir/hg19.fasta \
- -I $bam_dir/$sample.dedupped.bam \
- -targetIntervals $other_dir/$sample.realigner.intervals \
- -o $bam_dir/$sample.dedupped.realigned.bam \
- -known $ref_dir/1000G_phase1.indels.hg19.vcf \
- -known $ref_dir/Mills_and_1000G_gold_standard.indels.hg19.vcf
在一些老版本的pipeline中(如seqanswers上的那个),这一步做完后还要对pair-end数据的mate information进行fix。不过新版本已经不需要这一步了,Indel realign可以自己fix mate。参考http://gatkforums.broadinstitute.org/discussion/1562/need-to-run-a-step-with-fixmateinformation-after-realignment-step
(4) Base quality score recalibration
这一步简称BQSR,对base的quality score进行校正。同样要用到一些SNP和indel的已知文件(参考上表和代码中-known选项)。第一步BaseRecalibrator生成一个用于校正的recal.grp文件和一个校正前的plot;第一步BaseRecalibrator生成一个校正后的plot;第三步PringReads利用recal.grp进行校正,输出校正后的bam file。
- java -Xmx15g -jar $gatk \
- -T BaseRecalibrator \
- -R $ref_dir/hg19.fasta \
- -I $bam_dir/$sample.dedupped.realigned.bam \
- -knownSites $ref_dir/dbsnp_137.hg19.vcf \
- -knownSites $ref_dir/Mills_and_1000G_gold_standard.indels.hg19.vcf \
- -knownSites $ref_dir/1000G_phase1.indels.hg19.vcf \
- -o $other_dir/$sample.recal.grp \
- -plots $other_dir/$sample.recal.grp.pdf
- java -Xmx15g -jar $gatk \
- -T BaseRecalibrator \
- -R $ref_dir/hg19.fasta \
- -I $bam_dir/$sample.dedupped.realigned.bam \
- -BQSR $other_dir/$sample.recal.grp \
- -o $other_dir/$sample.post_recal.grp \
- -plots $other_dir/$sample.post_recal.grp.pdf \
- -knownSites $ref_dir/dbsnp_137.hg19.vcf \
- -knownSites $ref_dir/Mills_and_1000G_gold_standard.indels.hg19.vcf \
- -knownSites $ref_dir/1000G_phase1.indels.hg19.vcf
- java -Xmx15g -jar $gatk \
- -T PrintReads \
- -R $ref_dir/hg19.fasta \
- -I $bam_dir/$sample.dedupped.realigned.bam \
- -BQSR $other_dir/$sample.recal.grp \
- -o $bam_dir/$sample.dedupped.realigned.recal.bam
TIPS:
这一步里如果产生不了PDF文件,很可能是Rscript的执行出了问题。检查R里面是否安装了该安装的packages。如果仍无法找出原因,可以在BaseRecalibrator那两步加上-l DEBUG再运行,此时的log信息中会详细写明为什么Rscript执行不了。
(5)Reduce bam file
这一步类似将bam file进行压缩,减小size,也方便后续的UnifiedGenotyper对数据的读取和处理。
- java -Xmx15g -jar $gatk \
- -T ReduceReads \
- -R $ref_dir/hg19.fasta \
- -I $bam_dir/$sample.dedupped.realigned.recal.bam \
- -o $bam_dir/$sample.dedupped.realigned.recal.reduced.bam
到现在已经准备好了call variant所需要的bam file。下一篇会讲讲如何利用UnifiedGenotyper进行variant calling以及downstream的分析。
(6)Variant calling
GATK提供两种工具进行Variant calling,HaplotypeCaller 和UnifiedGenotyper。
按照GATK开发者的说法,HaplotypeCaller使用local de novo assembler和HMM likelihood function,性能优于UnifiedGenotyper,但是HaplotypeCaller还处于实验阶段,运行时可能会出现问题。GATK的推荐是如果可以用HaplotypeCaller,还是用它。要注意的是目前HaplotypeCaller的input不能使reduced bam files,也不能支持多线程。
这里使用的GATK工具是UnifiedGenotyper。
相比起对每一个sample分别进行calling,更好的方式是multi-sample calling。这样的pooled calling可以更多地利用多个sample的信息,对于特定位点,信息更多更加可信。
- data_dir=*******
- work_dir=******
- ref_dir=~/database/hg19
- bam_dir=$work_dir/bamfiles
- log_dir=$work_dir/logs
- met_dir=$work_dir/metrics
- other_dir=$work_dir/otherfiles
- vcf_dir=$work_dir/vcf
- gatk=/software/sequencing/GenomeAnalysisTK-2.3-4-g57ea19f/GenomeAnalysisTK.jar
- java -Xmx15g -jar $gatk \
- -glm BOTH \
- -l INFO \
- -R $ref_dir/hg19.fasta \
- -T UnifiedGenotyper \
- -I $bam_dir/sample1.dedupped.realigned.recal.reduced.bam \
- -I ... \
- -I ... \
- -D $ref_dir/dbsnp_137.hg19.vcf \
- -o $vcf_dir/allsamples.vcf \
- -metrics $met_dir/snpcall.metrics \
- -L $work_dir/Truseq.bed
-l BOTH 指对SNP和INDEL同时进行calling。
-L参数指定capture region的bed file。
这一步如果是deep coverage的exome sequencing data,时间还是蛮久的,>12h。由于每一条染色体的calling是相对独立的,如果赶时间,可以分别对每条染色体进行calling,然后用CombineVariants将不同的vcf文件合并。UnifiedGenotyper也可以使用多线程,multithreading,具体请参照如下两篇:
http://gatkforums.broadinstitute.org/discussion/1988/a-primer-on-parallelism-with-the-gatk#latest
http://www.broadinstitute.org/gatk/guide/article?id=1975
(7)Variant quality score recalibration
在做这一步前建议好好阅读这篇
http://gatkforums.broadinstitute.org/discussion/39/variant-quality-score-recalibration-vqsr
弄清楚VQSR的原理:基于已知的variants,建立模型去评估和filter新的variants。
要注意的是,VQSR只适用于samples数目大于30的exome sequencing或者whole genome sequenicing。如果sample数目不够或者capture region过小,请参考http://www.broadinstitute.org/gatk/guide/topic?name=best-practices中对于此类问题的解决方法建议。一般是使用VariantFiltration进行hard filter。
对于能够进行VQSR的,分两步进行:
a. VariantRecalibrator 这一步建立模型,生成用于评估和recalibration的file。
- java -Xmx15g -jar $gatk \
- -T VariantRecalibrator \
- -R $ref_dir/hg19.fasta \
- -mode SNP \
- -input $vcf_dir/allsamples.vcf \
- -resource:hapmap,known=false,training=true,truth=true,prior=15.0 $ref_dir/hapmap_3.3.hg19.vcf \
- -resource:omni,known=false,training=true,truth=false,prior=12.0 $ref_dir/1000G_omni2.5.hg19.vcf \
- -resource:dbsnp,known=true,training=false,truth=false,prior=6.0 $ref_dir/dbsnp_137.hg19.vcf \
- -an QD -an HaplotypeScore -an MQRankSum -an ReadPosRankSum -an FS -an MQ -an InbreedingCoeff \
- -recalFile $other_dir/allsamples_snp.recal \
- -tranchesFile $other_dir/allsamples_snp.tranches \
- -rscriptFile $other_dir/allsamples_snp.plots.R \
- --TStranche 90.0 \
- --TStranche 93.0 \
- --TStranche 95.0 \
- --TStranche 97.0 \
- --TStranche 99.0 \
- --TStranche 99.9 \
- --TStranche 100.0
首先run上面的代码。-an flag应尽可能多地包括variant的那些annotator参数,以方便后来我们对这些参数进行评估,以选出最优组合。这一步产生的allsamples_snp.plots.R的图片,类似下面这种:
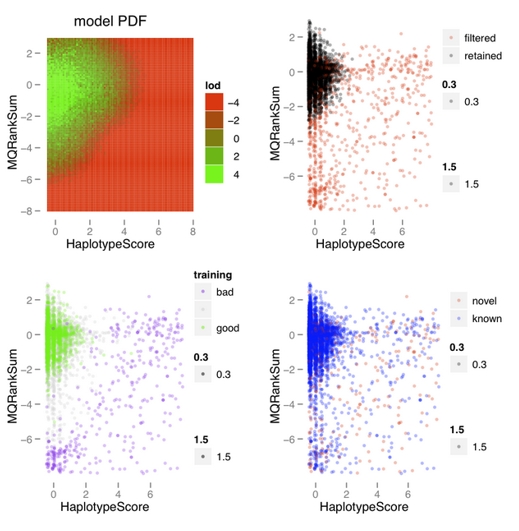
每一张图都描述了两个annotator参数的散点图。具体含义请参考前述链接。我们要做的就是选择那些可以很好地区分known/novel以及retained/filtered的variants的参数。上图所示的MQRankSum和HaplotypeScore就可以很清楚地将known variants聚类,从而filter那些和已知的cluster差别特别大的variants,因此这两个参数保留。
选择annotator参数的过程其实有点主观,需要经验...anyway, good luck.
当我们选择完所有对variants有很好区分度的参数后,再将上面的代码run一次,这次在-an那一行去掉没被选上的参数,保留我们选择的参数。
如果犹豫不定哪些参数该加还是不加,可以看看.tranches和.tranches.pdf这两个文件,看看在哪种参数组合下run出来的结果比较好一点。如何判断哪种结果好呢?(1)Ti/Tv rate.(2)保留的variants数目.(3)True positive和false positive的比例。一般来说Ti/Tv在接近于3的范围内越大越好,该值越小,False positive就越多。
下图是.tranches文件的内容示例。其中列出在在给定的target truth sensitivity下,有多少的novel和known variants,以及对应的Ti/Tv比例。target truth sensitivity越高,包括的variants数目越多,可能的假阳性就越多;想要降低假阳性,增加结果的specificity,可以降低target truth sensitivity。target truth sensitivity可以通过--TStranche进行设置,VariantRecalibrator默认只会给出--TStranche 99的选项,我们在程序中可以多设置几个threshold,进而可以在sensitivity和specificity之间进行选择。
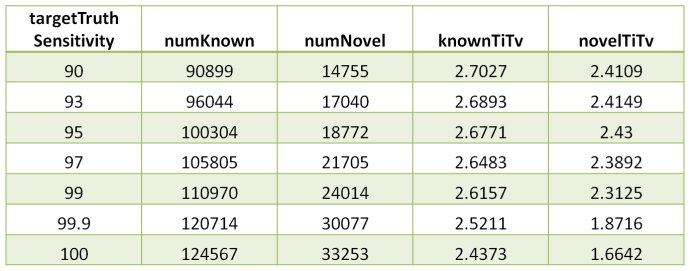
对INDEL也是同样的操作。只是INDEL的training resources和SNP不一样。另外根据GATK的建议,还set了一些别的参数。
- java -Xmx15g -jar $gatk \
- -T VariantRecalibrator \
- -R $ref_dir/hg19.fasta \
- -mode INDEL \
- --maxGaussians 4 -std 10.0 -percentBad 0.12 \
- -input $vcf_dir/allsamples.vcf \
- -resource:mills,known=true,training=true,truth=true,prior=12.0 $ref_dir/Mills_and_1000G_gold_standard.indels.hg19
- -an MQ -an FS -an InbreedingCoeff \
- -recalFile $other_dir/allsamples_indel.recal \
- -tranchesFile $other_dir/allsamples_indel.tranches \
- -rscriptFile $other_dir/allsamples_indel.plots.R
同样也是选择-an的flag,然后再run一次。
b.ApplyRecalibration 先对SNP进行apply,再对INDEL进行apply。
- java -Xmx15g -jar $gatk \
- -T ApplyRecalibration \
- -R $ref_dir/hg19.fasta \
- -mode SNP \
- -input $vcf_dir/allsamples.vcf \
- -tranchesFile $other_dir/allsamples_snp.tranches \
- -recalFile $other_dir/allsamples_snp.recal \
- -o $vcf_dir/allsamples_t90.SNPrecal.vcf \
- --ts_filter_level 90
- java -Xmx15g -jar $gatk \
- -T ApplyRecalibration \
- -R $ref_dir/hg19.fasta \
- -mode INDEL \
- -input $vcf_dir/allsamples_t90.SNPrecal.vcf \
- -tranchesFile $other_dir/allsamples_indel.tranches \
- -recalFile $other_dir/allsamples_indel.recal \
- -o $vcf_dir/allsamples_t90.bothrecal.vcf
--ts_filter_lever 90 是指将target truth sensitivity在90以下的在“filter”field标记为PASS,其余的根据我们设置的TStranche选项,分别标记不同的flag。例如VQSRTrancheSNP90.00to93.00,VQSRTrancheSNP93.00to95.00等等。
(8)Filtering
做完VQSR后,就可以根据vcf文件中FILTER一栏进行filter。filter没有一定的标准,主要还是看自己的期望,在specificity和sensitivity之间做选择。参考的主要还是.tranches文件里的数据。如果想包括尽可能多的novel variants而不太在乎false positive的问题,可以选择较高的target truth sensitivity,例如97。这样我们的filter策略就是:保留FILTER一栏的值为PASS,VQSRTrancheSNP90.00to93.00,VQSRTrancheSNP93.00to95.00,VQSRTrancheSNP95.00to97.00的variants,filter掉其他的variants。使用awk就可以啦。
(9)variants评估
使用的工具为VariantEval。它可以给出很多summary信息,例如每个sample的Ti/Tv,variants数目等等。
- java -Xmx70g -jar $gatk \
- -T VariantEval \
- -R $ref_dir/genome.fa \
- --eval:allsamples $vcf_dir/allsamples_t90-97.bothrecal.vcf \
- -o $other_dir/allsamples_t90.eval.gatkreport \
- -D $ref_dir/dbsnp_137.hg19.vcf \
- -ST Sample -ST Filter \
- -noEV \
- -EV TiTvVariantEvaluator
- java -Xmx70g -jar $gatk \
- -T VariantEval \
- -R $ref_dir/genome.fa \
- --eval:allsamples $vcf_dir/allsamples_t90-97.bothrecal.vcf \
- -o $other_dir/allsamples_t90.eval_1.gatkreport \
- -D $ref_dir/dbsnp_137.hg19.vcf \
- -ST Sample -ST Filter \
- -noEV \
- -EV CompOverlap \
- -EV CountVariants \
- -EV IndelSummary \
- -EV MultiallelicSummary \
- -EV ValidationReport
这一步很耗memory,所以有时候得run多次,每次产生一部分结果。
-ST 对每个sample分别进行统计。
-noEV 由于EV包括的选项太多,全部run有点吃不消,因此disable它,然后用-EV flag挑选我们感兴趣的指标进行summary。
本文来自:
http://blog.sina.com.cn/s/blog_681aaa550101bhdc.html
http://blog.sina.com.cn/s/blog_681aaa550101cdmk.html