

ggplot2的功能不用我们做广告,因为它的作者Hadley Wickham就说ggplot2是一个强大的作图工具,它可以让你不受现有图形类型的限制,创造出任何有助于解决你所遇到问题的图形。一点也不谦虚。H.W.还说了另外一句话,“学习ggplot2你得忘记一些东西”,所以也有人说ggplot2是作图软件中的太极功。有点高深。
那好吧,我就怀着无比崇敬的心情来学一学这太极图法。先安装软件包:
- install.packages("ggplot2")
1 qplot函数参数
Hadley Wickham同学很善解人意,知道我们接受一种新事物不会太容易,所以设计了个qplot函数。qplot 即“快速作图”(quick plot),顾名思义,能快速对数据进行可视化分析。它的用法和R base包的plot函数很相似,主要作用是让读者/用户在不知不觉中洗脑。先看看它的参数:
- qplot(x, y = NULL, ..., data, facets = NULL,
- margins = FALSE, geom = "auto", stat = list(NULL),
- position = list(NULL), xlim = c(NA, NA),
- ylim = c(NA, NA), log = "", main = NULL,
- xlab = deparse(substitute(x)),
- ylab = deparse(substitute(y)), asp = NA)
- x, y: 意义明确,不用说了
- data: 这个可以有,为数据框(data.frame)类型;如果有这个参数,那么x,y的名称必需对应数据框中某列变量的名称
- facets: 图形/数据的分面。这是ggplot2作图比较特殊的一个概念,它把数据按某种规则进行分类,每一类数据做一个图形,所以最终效果就是一页多图
- margins: 是否显示边界
- geom: 图形的几何类型(geometry),这又是ggplot2的作图概念。ggplot2用几何类型表示图形类别,比如point表示散点图、line表示曲线图、bar表示柱形图等。
- stat: 统计类型(statistics),这个更加特殊。直接将数据统计和图形结合,这是ggplot2强大和受欢迎的原因之一。
- position: 图形或者数据的位置调整,这不算太特殊,但对于图形但外观很重要
- xlim, ylim, xlab, ylab, asp: 初步可以按照plot函数的相应参数来理解
作为入门的第一节,下面主要讲data和geom参数。
2 qplot做散点图
2.1 使用向量数据
和plot函数一样,如果不指定图形的类型,qplot默认做出散点图。对于给定的x和y向量做散点图,qplot用法也和plot函数差不多:
- library(ggplot2)
- x <- 1:1000
- y <- rnorm(1000)
- plot(x, y, main="Scatter plot by plot()")
- qplot(x,y, main="Scatter plot by qplot()")
2.2 使用数据框数据
虽然可以直接使用向量数据,但ggplot2更倾向于使用数据框类型的数据作图。使用数据框有几个好处:数据框可以用来存储数值、字符串、因子等不同类型等数据;把数据放在同一个R数据框对象中可以避免使用过程中数据关系的混乱;数据外观的整理和转换方便。ggplot2中使用数据框作图的最直接的一个效果就是:你可以直接用数据的分类特性(数据框中的列变量)来决定图形元素的外观,这个过程在ggplot2中称为映射(mapping),是自动的。
在演示使用数据框作图的好处之前我们先了解以下ggplot2提供的一组有关钻石的示范数据 diamonds:
- str(diamonds)
- ## 'data.frame': 53940 obs. of 10 variables:
- ## $ carat : num 0.23 0.21 0.23 0.29 0.31 0.24 0.24 0.26 0.22 0.23 ...
- ## $ cut : Ord.factor w/ 5 levels "Fair"<"Good"<..: 5 4 2 4 2 3 3 3 1 3 ...
- ## $ color : Ord.factor w/ 7 levels "D"<"E"<"F"<"G"<..: 2 2 2 6 7 7 6 5 2 5 ...
- ## $ clarity: Ord.factor w/ 8 levels "I1"<"SI2"<"SI1"<..: 2 3 5 4 2 6 7 3 4 5 ...
- ## $ depth : num 61.5 59.8 56.9 62.4 63.3 62.8 62.3 61.9 65.1 59.4 ...
- ## $ table : num 55 61 65 58 58 57 57 55 61 61 ...
- ## $ price : int 326 326 327 334 335 336 336 337 337 338 ...
- ## $ x : num 3.95 3.89 4.05 4.2 4.34 3.94 3.95 4.07 3.87 4 ...
- ## $ y : num 3.98 3.84 4.07 4.23 4.35 3.96 3.98 4.11 3.78 4.05 ...
- ## $ z : num 2.43 2.31 2.31 2.63 2.75 2.48 2.47 2.53 2.49 2.39 ...
可以看到这是数据框(data.frame)类型,有10个变量(列),每个变量有53940个测量值(行)。第一列为钻石的克拉数(carat),为数字型数据;第二列为钻石的切工好坏(cut),为因子类型数据,有5个水平;第三列为钻石颜色(color),为7水平的因子;后面还有其他数据。由于数据太多,我们只取前7列的100个随机观测值。数据基本就是我们平时记录原始数据的样式:
- set.seed(1000) # 设置随机种子,使随机取样具有可重复性
- datax<- diamonds[sample(53940, 100), seq(1,7)]
- head(datax, 4)
- ## carat cut color clarity depth table price
- ## 17686 1.23 Ideal H VS2 62.2 55 7130
- ## 40932 0.30 Ideal E SI1 61.7 58 499
- ## 6146 0.90 Good H VS2 61.9 58 3989
- ## 37258 0.31 Ideal G VVS1 62.8 57 977
如果要做钻石克拉和价格关系的曲线图,用plot和qplot函数都差不多:
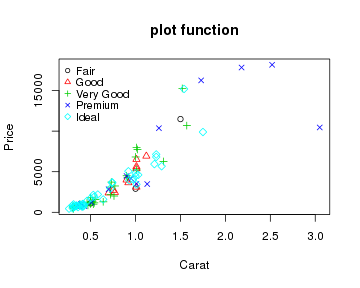
- plot(x=datax$carat, y=datax$price, xlab="Carat", ylab="Price", main="plot function")
- qplot(x=carat, y=price, data=datax, xlab="Carat", ylab="Price", main="qplot function")
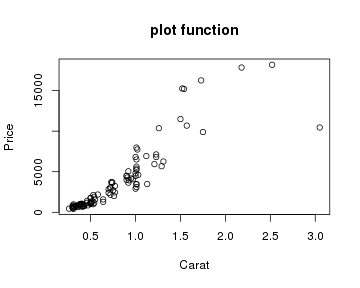
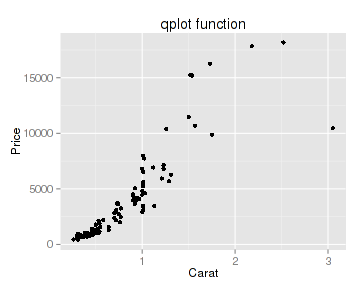
但如果要按切工进行分类作图,plot函数的处理就复杂了,你首先得将数据进行分类提取,然后再一个个作图。虽然可以用循环完成,但作图后图标的添加还得非常小心,你得自己保证数据和图形外观之间的对应关系:
- plot(x=datax$carat, y=datax$price, xlab="Carat", ylab="Price", main="plot function", type='n')
- cut.levels <- levels(datax$cut)
- cut.n <- length(cut.levels)
- for(i in seq(1,cut.n)){
- subdatax <- datax[datax$cut==cut.levels[i], ]
- points(x=subdatax$carat, y=subdatax$price, col=i, pch=i)
- }
- legend("topleft", legend=cut.levels, col=seq(1,cut.n), pch=seq(1,cut.n), box.col="transparent", cex=0.8)
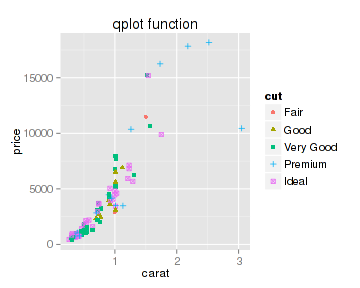
但用ggplot2作图你需要考虑数据分类和图形元素方面的问题就很少,你只要告诉它用做分类的数据就可以了:
- qplot(x=carat, y=price, data=datax, color=cut, shape=cut, main="qplot function")
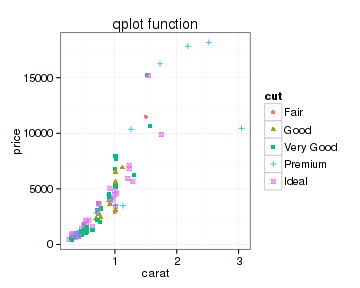
如果不喜欢它默认的图形背景,要改变也相当简单,ggplot2预置了几个模板,这些内容我们在后面再详细说:
- theme_set(theme_bw())
- qplot(x=carat, y=price, data=datax, color=cut, shape=cut, main="qplot function")
数据框可以存储不同的数据,而这些数据是有类型差别的。ggplot2作图对各类数据的要求也非常严格,用于分类的数据必需是因子类型,否则就出错,例如下面的语句就会出错:
- qplot(x=carat, y=price, data=datax, shape=depth)
- ## Error: A continuous variable can not be mapped to shape
3qplot做曲线图
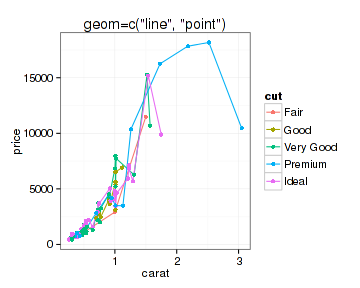
和plot函数一样,qplot也可以通过设置合适的参数产生曲线图,这个参数就是geom(几何类型)。图形的组合非常直接,组合表示几何类型的向量即可:
- qplot(x=carat, y=price, data=datax, color=cut, geom="line", main="geom=\"line\"")
- qplot(x=carat, y=price, data=datax, color=cut, geom=c("line", "point"), main="geom=c(\"line\", \"point\")")

4 qplot做统计图
qplot是名副其实的qplot(quick plot)函数,通过改变几何类型geom参数的值你可以获得各种图形。geom参数可以设置的值和意义是:
- point:散点图
- line:曲线图
- smooth:平滑曲线
- jitter:另一种散点图
- boxplot:箱线图
- histogram:直方图
- density:密度分布图
- bar:柱状图
前两种我们看过了,bar类型下面另讲,jitter以后有机会再说,看看其他4种类型:
- qplot(carat, price, data = diamonds, color=cut, geom = "smooth", main = "smooth")
- qplot(cut, price, data = diamonds, fill=cut, geom = "boxplot", main = "boxplot")
- qplot(price, data = diamonds, fill=cut, geom = "histogram", main = "histogram")
- qplot(price, data = diamonds, color=cut, geom = "density", main = "density")
能做什么样的图形取决于数据,这点我们都很清楚,所以不同类型的图使用的数据有所不同,参数也有变化。前面我们说ggplot2可以整合不同类型的图形到一个图中,但很重要的一个前提是要组合的这些形状要能共享一组数据和参数。道理很简单,如果某人绞尽脑汁把散点图和密度分布图融合在一个图中展示,不出一周他就要住进精神病院。
- qplot(price, data = diamonds, color=cut, geom = c("point", "density"))
- ## Error: geom_point requires the following missing aesthetics: y
5 qplot做柱形图
做柱形图很少直接用原始数据,一般都要通过计算变换如求平均值后再做。这其实是一个统计过程,所以多数柱形图应该也是统计类型的图。ggplot2对柱形图的处理体现了这一思想:柱形图是一种特殊的直方图。所以ggplot2可以直接用原始数据做出柱形图,这是它的优点之一。下面按钻石切工对价格求平均值后做柱形图:
- qplot(x=cut, y=price, data = diamonds, fill=cut, geom = "histogram",
- stat="summary", fun.y="mean")
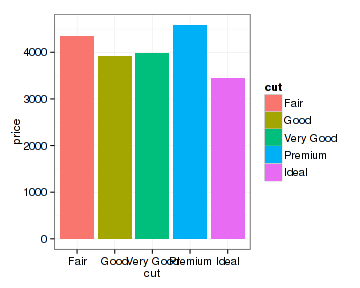
stat参数表示统计的类型,而fun.y则表示应用于统计的函数。把geom参数值换成bar得到相同的图形:
- qplot(x=cut, y=price, data = diamonds, fill=cut, geom = "bar",
- stat="summary", fun.y="mean")
如果不嫌麻烦,可以先计算出平均值再柱形图也没什么问题。引物bar图形的本质是统计图形,所以得设置stat参数为identity,即不做统计:
- (mean.price <- with(diamonds, aggregate(price~cut, FUN=mean)))
- ## cut price
- ## 1 Fair 4359
- ## 2 Good 3929
- ## 3 Very Good 3982
- ## 4 Premium 4584
- ## 5 Ideal 3458
- qplot(x=cut, y=price, data=mean.price, fill=cut, geom="bar", stat="identity")
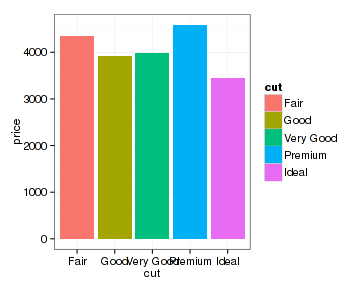
通过学习上面的简单例子可能会有点收获:了解了ggplot2的qplot函数能用什么样的数据做什么图,知道一点关于ggplot2几何类型和统计类型的概念,如何从传统的R语言作图中转过脑筋来。但也仅此而已。ggplot2作图是基于图层的,从上面qplot函数的使用例子中显然看不出来,除此外还有很多深层次的概念、理论和函数。
6 SessionInfo
- sessionInfo()
- ## R version 3.1.0 (2014-04-10)
- ## Platform: x86_64-pc-linux-gnu (64-bit)
- ##
- ## locale:
- ## [1] LC_CTYPE=zh_CN.UTF-8 LC_NUMERIC=C
- ## [3] LC_TIME=zh_CN.UTF-8 LC_COLLATE=zh_CN.UTF-8
- ## [5] LC_MONETARY=zh_CN.UTF-8 LC_MESSAGES=zh_CN.UTF-8
- ## [7] LC_PAPER=zh_CN.UTF-8 LC_NAME=C
- ## [9] LC_ADDRESS=C LC_TELEPHONE=C
- ## [11] LC_MEASUREMENT=zh_CN.UTF-8 LC_IDENTIFICATION=C
- ##
- ## attached base packages:
- ## [1] tcltk stats graphics grDevices utils datasets methods
- ## [8] base
- ##
- ## other attached packages:
- ## [1] mgcv_1.7-29 nlme_3.1-117 ggplot2_0.9.3.1 zblog_0.1.0
- ## [5] knitr_1.5
- ##
- ## loaded via a namespace (and not attached):
- ## [1] colorspace_1.2-4 digest_0.6.4 evaluate_0.5.3 formatR_0.10
- ## [5] grid_3.1.0 gtable_0.1.2 highr_0.3 labeling_0.2
- ## [9] lattice_0.20-29 MASS_7.3-31 Matrix_1.1-3 munsell_0.4.2
- ## [13] plyr_1.8.1 proto_0.3-10 Rcpp_0.11.1 reshape2_1.2.2
- ## [17] scales_0.2.4 stringr_0.6.2 tools_3.1.0
原文来自:http://blog.csdn.net/u014801157/article/details/24372499