

使用R处理数据完全可以不了解它的编程方法,但编程可以提高效率。
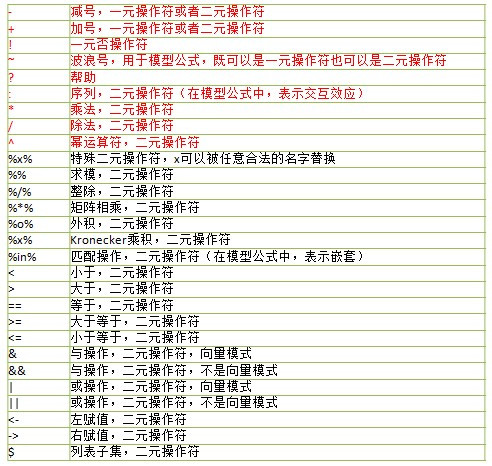
一、运算符
二、向量运算规则
R语言的数据以向量为基础。向量的运算不需要通过下标循环一个个元素来进行的。如果两个向量长度相同,是对位置相同的数据进行相应计算;如果长度不同,较短的向量要重复取值直到两个向量长度相同。如果短向量长度不是长向量的整倍数,仍可得到结果,但有警告。向量运算方式避免了使用循环,速度很快:
- > (a <- 1:5)
- [1] 1 2 3 4 5
- > (b <- 2:6)
- [1] 2 3 4 5 6
- > (c <- 2:3)
- [1] 2 3
- > (d <- 2)
- [1] 2
- > a*b
- [1] 2 6 12 20 30
- > a*c
- [1] 2 6 6 12 10
警告信息:
In a * c : 长的对象长度不是短的对象长度的整倍数
- > a*d
- [1] 2 4 6 8 10
三、数学函数
R语言的默认安装包提供了大量的数学与统计函数。在R语言的定义中,运算符事实上也是函数:
1、操作符函数,包括算术函数、比较函数和逻辑函数:
算术函数:
"+", "-", "*", "^", "%%", "%/%", "/"
比较函数:
"==", ">", "<", "!=", "<=", ">="
逻辑函数
"&", "|".
2、数学函数:
"abs", "sign", "sqrt", "ceiling", "floor", "trunc", "cummax", "cummin", "cumprod", "cumsum", "log", "log10", "log2", "log1p", "acos", "acosh", "asin", "asinh", "atan", "atanh", "exp", "expm1", "cos", "cosh", "sin", "sinh", "tan", "tanh", "gamma", "lgamma", "digamma", "trigamma"
3、数学函数2:
"round", "signif"
4、统计特征值函数:
"max", "min", "range", "prod", "sum", "any", "all"
5、复数函数:
"Arg", "Conj", "Im", "Mod", "Re"
四、程序流程控制:
1、if/else分支语句:
基本用法是:if (逻辑判断) { 语句 } else { 语句 }
2、switch分支语句:
基本用法是:switch(statment, list)
但具体意义和其他语言有些差别。第二个参数list可以分成多个参数,switch把2到n个参数都归为一个list。list参数分有名参数和无名参数。
- > a <- 2
- > switch(a, log(a), a+3, a-3) #a=2,执行列表第二项:a+3
- [1] 5
- > a <- 1
- > switch(a, log(a), a+3, a-3) #a=1,执行列表第一项:log(a)
- [1] 0
- > a <- "agi"
- > switch(a, gi=1030567, agi="AT1G10010", name="CBFx") #返回a(名称)对应的列表向量值
- [1] "AT1G10010"
3、for循环语句
基本用法:for (name in expression) { 语句 }
- > a <- 1:5
- > b <- NULL
- > for(i in a) {b <- c(b,log(i))}
- > b
- [1] 0.0000000 0.6931472 1.0986123 1.3862944 1.6094379
R语言的循环非常耗时,能使用向量运算的尽量避免使用循环。上面循环完全没有必要:
- > b <-log(a)
- > b
- [1] 0.0000000 0.6931472 1.0986123 1.3862944 1.6094379
4、while和repeat语句:这两个跟其他语言差不多。
跳出循环用break,忽略后面语句进行循环用next。
五、函数方法
R语言的很多工作都由函数完成,这是保证结果准确性和可重复性的途径。我们也可以通过编写自己的函数提高工作效率。
R语言中函数定义的方法为:函数名 <- function(参数们) { R语句们 }
用法是:函数名(参数们)
函数可以有返回值,返回值就是最后一个语句的结果;也可以只完成一系列操作(如绘图)而不用返回值。
下面是一个两系列数据的柱形图绘制函数:
- bar.plot <- function(y1, y2, x=1:length(y1),
- sd1=y1*0.05, sd2=y2*0.05,
- xlab="Sample", ylab="Level",
- labels=c("S1","S2")){
- the.data <- rbind(y1, y2)
- par(mar=c(3,3,0.5,0.5))
- par(mgp=c(2,0.5,0))
- pos <- barplot(the.data, ylim=c(0, max(y1,y2)*1.2),
- offset=0, axis.lty=1, beside=TRUE,
- names.arg = x, col=c("orange","red"))
- legend("topleft", legend=labels, fill=c("orange","red"),box.col="white", inset=0.02)
- title(xlab=xlab, ylab=ylab)
- bw <- 0.2
- segments(pos[1,], y1-sd1, pos[1,], y1+sd1, lwd=2)
- segments(pos[1,]-bw, y1+sd1, pos[1,]+bw, y1+sd1, lend=2)
- segments(pos[1,]-bw, y1-sd1, pos[1,]+bw, y1-sd1, lend=2)
- segments(pos[2,], y2-sd2, pos[2,], y2+sd2, lwd=2)
- segments(pos[2,]-bw, y2+sd2, pos[2,]+bw, y2+sd2, lend=2)
- segments(pos[2,]-bw, y2-sd2, pos[2,]+bw, y2-sd2, lend=2)
- box()
- }
以mybar.R为文件名保存到D盘根目录下。重新启动R终端,你可以反复调用这个文件里面的bar.plot函数绘制出你需要的柱形图:
- > source("d:/mybar.R")
- > NF <- c(17.44 , 2.56 , 2.70 , 18.71 , 5.61 , 32.98)
- > CA <- c(11.48 , 0.75 , 1.16 , 12.73 , 2.84 , 20.04)
- > sd.NF <- c(1.27 , 0.15 , 0.48 , 2.01 , 0.80 , 4.09)
- > sd.CA <- c(1.09 , 0.36 , 0.11 , 1.82 , 0.92 , 2.36)
- > x <- paste("S", 1:length(NF), sep="")
- > bar.plot(x=x, y1=NF, y2=CA, sd1=sd.NF, sd2=sd.CA, labels=c("NF", "CA"))
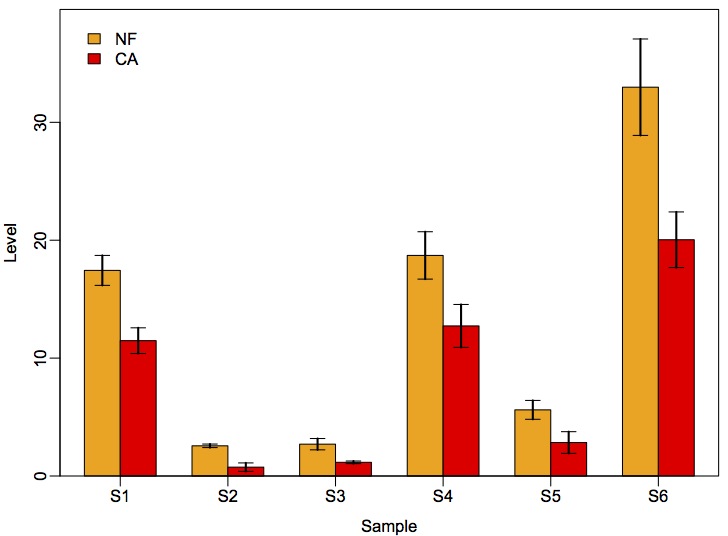
由于bar.plot函数除y1和y2外其他参数都有默认值,你可以只提供两个系列的数据(默认误差为数据的5%):
- > source("d:/mybar.R")
- > set.seed(1000)
- > y1 <- abs(rnorm(10))*10
- > y2 <- abs(rnorm(10))*5
- > bar.plot(y1,y2)
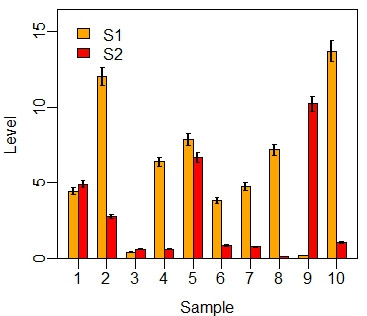
虽然数据更换了,但是获得的图形外观完全一样!这已经不仅仅是效率的问题了。是懒人的办法,也是聪明人的办法。比起origin作图软件,R的可重复性要好得多吧?Excel的作图方法是小儿科了,谈不上科学性(但是很多人在用,呵呵)。
原文来自:http://blog.csdn.net/u014801157/article/details/24372359