

一、描述统计量
R为描述统计量的计算提供了较全函数。我们用R自带的sunspots数据对这些函数做简单了解:
> sp <- sunspots
> class(sp)
[1] "ts"
> str(sp)
Time-Series [1:2820] from 1749 to 1984: 58 62.6 70 55.7 85 83.5 94.8 66.3 75.9 75.5 ...
> #sunspots是时间序列数据,把它转为矩阵
> sp <- matrix(sp, ncol=12, byrow=TRUE)
> rownames(sp) <- 1749:1983
> colnames(sp) <- 1:12
> head(sp)
1 2 3 4 5 6 7 8 9 10 11 12
1749 58.0 62.6 70.0 55.7 85.0 83.5 94.8 66.3 75.9 75.5 158.6 85.2
1750 73.3 75.9 89.2 88.3 90.0 100.0 85.4 103.0 91.2 65.7 63.3 75.4
1751 70.0 43.5 45.3 56.4 60.7 50.7 66.3 59.8 23.5 23.2 28.5 44.0
1752 35.0 50.0 71.0 59.3 59.7 39.6 78.4 29.3 27.1 46.6 37.6 40.0
1753 44.0 32.0 45.7 38.0 36.0 31.7 22.2 39.0 28.0 25.0 20.0 6.7
1754 0.0 3.0 1.7 13.7 20.7 26.7 18.8 12.3 8.2 24.1 13.2 4.2
>
> #均值,最大值,最小值,求和,中位数,方差,标准差
> mean(sp); max(sp); min(sp); sum(sp); median(sp)
[1] 51.26596
[1] 253.8
[1] 0
[1] 144570
[1] 42
>
> #方差函数var用1向量、2向量和矩阵获得的结果和意义不一样,具体看在线参考
> #如果是矩阵数据,还有两个相关函数cov()和cor()
> var(sp[,1])
[1] 1840.18
> var(sp[,1], sp[,2])
[1] 1629.689
> var(sp)
1 2 3 4 5 6 7 8
1 1840.180 1629.689 1545.522 1588.485 1652.158 1577.559 1634.858 1631.202
2 1629.689 1752.184 1558.727 1573.566 1586.585 1525.066 1575.072 1572.282
3 1545.522 1558.727 1655.654 1556.592 1583.382 1495.263 1530.311 1556.609
#输出结果的其他行忽略
> #标准差sd只能以向量进行计算,如果是矩阵则按行计算(新版)。
> sd(sp)
1 2 3 4 5 6 7 8
42.89732 41.85910 40.68973 42.73195 45.08716 42.51302 43.52788 44.75650
9 10 11 12
45.76396 43.98236 43.13204 45.06596
警告信息:
sd(<matrix>) is deprecated.
Use apply(*, 2, sd) instead.
> sd(sp[1,])
[1] 27.22469
> sd(sp[,1])
[1] 42.89732
> #求百分位数
> quantile(sp)
0% 25% 50% 75% 100%
0.000 15.700 42.000 74.925 253.800
> quantile(sp, probs = c(0.1, 0.2, 0.4))
10% 20% 40%
5.00 11.60 30.56二、数据分布
1、直方图:hist函数
> hist(sp) > hist(sp, breaks = seq(from=min(sp), to=max(sp), length=1000)) #改变breaks参数可以获得更详细的图形
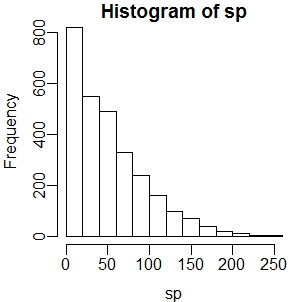
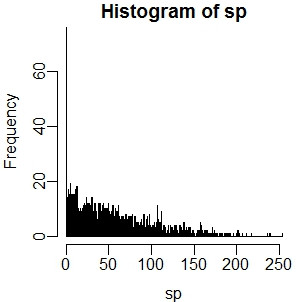
2、核密度估计函数density:
> d <- density(sp, n=length(sp)) #密度函数的返回值可以直接作图 > plot(d, main="") #叠加直方图和密度曲线 > hist(sp, breaks = seq(from=min(sp), to=max(sp), length=100), freq=FALSE, main="") > lines(d, col="red")
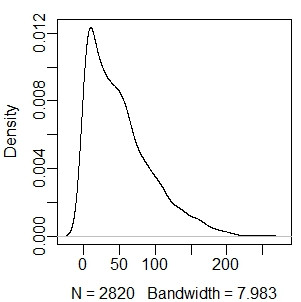
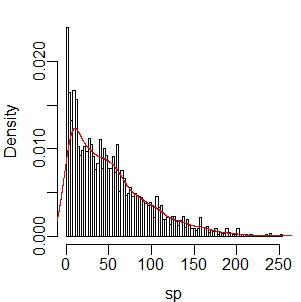
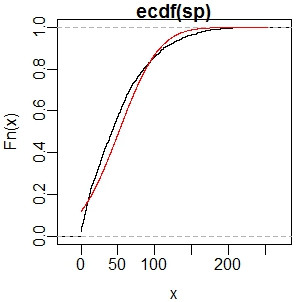
3、经验分布曲线(与正态分布曲线比较,初步判断数据是否符合正态分布):
> ecd <- ecdf(sp) #获得经验分布函数 > plot(ecd) #经验分布函数可以直接绘图 > x <- sort(as.vector(sp)) > lines(x, pnorm(x,mean(x), sd(x)), col="red") #获取该组数据的正态分布曲线,为图中红线
4、QQ图:
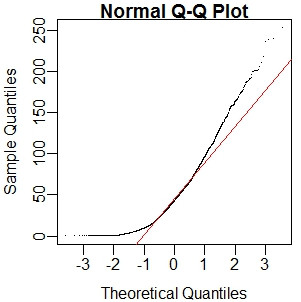
用QQ图可以直观判断数据是否符合正态分布:如果符合正态分布,qqnorm应该接近qqline(右上图)
> qqnorm(sp, pch=".") > qqline(sp, col="red") #右上图中的红线
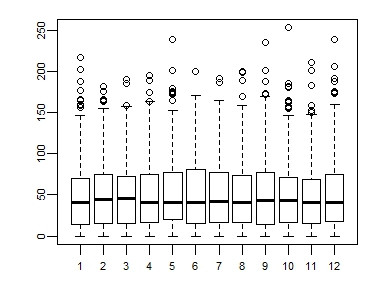
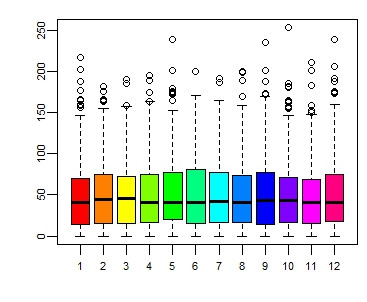
5、箱线图:
这个用得很多。对于矩阵数据默认按列统计。
> boxplot(sp, cex.axis=0.7) #如果觉得眼花,加点颜色 > color <- rainbow(ncol(sp)) > boxplot(sp, cex.axis=0.7, col=color)
6、多变量分组比较:dotchart
sunspots为1749年1月到1983年12月的数据,取其中一部分进行作图:
> dotchart(sp[i,1:4], pch=1:4, cex=0.8) > i <- c(1,21,41,61) > dotchart(sp[i,1:4], pch=1:4, cex=0.8)
7、其他
三个变量的数据可以用coplot分析他们之间的关系,更多变量的数据用pairs()做初步分析,或自编绘图函数完成。一些R统计软件包提供了更丰富的函数和参数选项,如需要可自行学习使用。
原文来自:http://blog.csdn.net/u014801157/article/details/24372367